
PUBLIC
SAP HANA Platform 2.0 SPS 04
Document Version: 1.1 – 2019-10-31
SAP HANA Troubleshooting and Performance
Analysis Guide
© 2019 SAP SE or an SAP aliate company. All rights reserved.
THE BEST RUN
Content
1 SAP HANA Troubleshooting and Performance Analysis Guide.......................... 6
2 Analyzing Generic Symptoms...................................................9
2.1 Performance and High Resource Utilization...........................................9
2.2 Common Symptoms and Troubleshooting...........................................11
Slow System-wide Performance............................................... 12
Slow Individual SQL Statements............................................... 15
Frequent Out of Memory (OOM)............................................... 18
3 Root Causes and Solutions....................................................22
3.1 Memory Problems........................................................... 22
Memory Information in SAP HANA Cockpit....................................... 23
Memory Information from Logs and Traces....................................... 23
Memory Information from SQL Commands.......................................25
Memory Information from Other Tools...........................................29
Root Causes of Memory Problems............................................. 30
Transparent Huge Pages on Linux..............................................38
3.2 CPU Related Root Causes and Solutions............................................39
Indicators of CPU Related Issues...............................................39
Analysis of CPU Related Issues................................................39
Resolving CPU Related Issues.................................................41
Retrospective Analysis of CPU Related Issues......................................41
Controlling Parallel Execution of SQL Statements ...................................42
Controlling CPU Consumption................................................ 44
3.3 Disk Related Root Causes and Solutions............................................48
Reclaiming Disk Space......................................................52
Analyze and Resolve Internal Disk-Full Event (Alert 30)...............................53
3.4 I/O Related Root Causes and Solutions.............................................55
Analyzing I/O Throughput and Latency..........................................58
Savepoint Performance.....................................................59
3.5 Conguration Parameter Issues..................................................61
Issues with Conguration Parameter log_mode (Alert 32 and 33)........................63
3.6 Backup And Recovery.........................................................64
3.7 Delta Merge................................................................68
Inactive Delta Merge....................................................... 68
Indicator for Large Delta Storage of Column Store Tables..............................70
Failed Delta Merge.........................................................73
2
P U B L I C
SAP HANA Troubleshooting and Performance Analysis Guide
Content
Delta Storage Optimization...................................................74
3.8 SAP Web IDE............................................................... 75
Post-Installation Problems with Web IDE......................................... 75
Web IDE Common Issues with Modeling..........................................77
3.9 Troubleshooting BW on HANA...................................................79
3.10 Troubleshooting Multi-Dimensional Services Queries...................................90
3.11 Troubleshooting Tips for the Calculation Engine.......................................94
Native HANA Models.......................................................97
3.12 License Issues..............................................................97
System Locked Due to Missing, Expired, or Invalid License.............................98
License Problem Identication and Analysis.......................................98
Resolution of License Issues..................................................99
3.13 Security-Related Issues.......................................................100
Troubleshooting Authorization Problems........................................ 101
Troubleshooting Problems with User Name/Password Authentication....................106
Troubleshooting Problems with User Authentication and SSO......................... 108
3.14 Transactional Problems........................................................111
Blocked Transactions ......................................................111
Troubleshooting Blocked Transaction Issues that Occurred in the Past....................116
Multiversion Concurrency Control (MVCC) Issues..................................116
Version Garbage Collection Issues.............................................119
3.15 Statement Performance Analysis................................................ 121
SQL Statement Optimization.................................................122
Analysis of Critical SQL Statements............................................125
Optimization of Critical SQL Statements.........................................131
3.16 Application Performance Analysis................................................139
SQL Trace Analysis........................................................139
Statement Measurement................................................... 140
Data Analysis............................................................141
Source Analysis..........................................................142
Technical Analysis........................................................ 143
3.17 System Hanging Situations.................................................... 144
Transparent Huge Pages....................................................145
CPU Power Saving........................................................146
3.18 Troubleshoot System Replication................................................ 147
Replication Performance Problems............................................ 148
Setup and Initial Conguration Problems........................................152
Intermittent Connectivity Problems............................................157
LogReplay: Managing the Size of the Log File......................................158
3.19 Network Performance and Connectivity Problems.................................... 161
Network Performance Analysis on Transactional Level...............................161
SAP HANA Troubleshooting and Performance Analysis Guide
Content
P U B L I C 3
Stress Test with NIPING.................................................... 163
Application and Database Connectivity Analysis...................................164
SAP HANA System Replication Communication Problems............................166
SAP HANA Inter-Node Communication Problems..................................168
3.20 SAP HANA Dynamic Tiering....................................................170
Tools and Tracing.........................................................170
Query Plan Analysis.......................................................170
Data Loading Performance.................................................. 172
4 Tools and Tracing.......................................................... 174
4.1 System Performance Analysis...................................................174
Thread Monitoring........................................................ 174
Blocked Transaction Monitoring...............................................177
Session Monitoring........................................................178
Job Progress Monitoring....................................................179
Load Monitoring..........................................................180
4.2 SQL Statement Analysis...................................................... 180
Analyzing SQL Traces......................................................181
Analyzing Expensive Statements Traces.........................................185
Analyzing SQL Execution with the SQL Plan Cache................................. 189
4.3 Query Plan Analysis..........................................................190
Analyzing SQL Execution with the Plan Explanation.................................191
Analyzing SQL Execution with the Plan Visualizer.................................. 195
4.4 Result Cache.............................................................. 210
Static Result Cache........................................................211
Dynamic Result Cache.....................................................216
4.5 Tracing for Calculation View Queries..............................................223
4.6 Advanced Analysis..........................................................224
Analyzing Column Searches (qo trace)..........................................224
Analyzing Table Joins......................................................226
SQL Plan Stability........................................................ 227
4.7 Additional Analysis Tools for Support............................................. 231
Performance Trace........................................................231
Kernel Proler...........................................................233
Diagnosis Information..................................................... 234
Analysis Tools in SAP HANA Web-based Developer Workbench........................ 235
5 SAP HANA Database monitoring with Solution Manager............................ 238
6 Alerts and the Statistics Service.............................................. 242
6.1 Reference: Alerts........................................................... 243
6.2 Alerts Reference............................................................262
4
P U B L I C
SAP HANA Troubleshooting and Performance Analysis Guide
Content
1 SAP HANA Troubleshooting and
Performance Analysis Guide
With SAP HANA, you can analyze data at incredible speeds, for example, with scans of 1 billion rows per second
per core and join performance of 10 million rows per second. However, such results are only possible if the
system is monitored and performance issues are kept to a minimum.
This guide describes the measures you can take to identify and resolve specic performance issues and shows
you how to enhance the performance of your SAP HANA database in the following areas:
● Host resources (CPU, memory, disk)
● Size and growth of data structures
● Transactional problems
● SQL statement performance
● Security, authorization, and licensing
● Conguration.
Prerequisites
● This guide assumes knowledge of the relevant functionality of the SAP HANA database (knowledge which
can be gained from HANA training courses such as HA100, HA200).
● Access to the administration tool SAP HANA cockpit (or alternatively SAP HANA studio) is required.
Overview
Analyzing Generic Symptoms
This section of the troubleshooting guide helps you to nd out about causes of generic problems such as:
● slow system-wide performance
● slow individual SQL statements
● frequent out-of-memory (OOM) situations
Furthermore, you are directed to sections of this guide that contain more specic root causes.
SAP Note references lead you to possible solutions.
Analyzing Generic Symptoms [page 9]
Root Causes & Solutions
In this section of the troubleshooting guide you nd concrete root causes for problems together with possible
solutions. Some of the areas covered are:
6
P U B L I C
SAP HANA Troubleshooting and Performance Analysis Guide
SAP HANA Troubleshooting and Performance Analysis Guide

● Memory Problems
● CPU Related Root Causes and Solutions
● License Issues
● Statement Performance Analysis
You may nd the SAP Notes very useful for solving your issue as they contain detailed explanations and step-
by-step instructions, for example.
Root Causes and Solutions [page 22]
Tools and Tracing
This section of the troubleshooting guide presents monitoring tools which can be used for analyzing and
tracing certain issues.
Tools and Tracing [page 174]
Apart from those more specic monitoring tools discussed here, there are important tools for administrators
and developers in general:
● SAP HANA cockpit
Tip
For the documentation of the latest SAP HANA cockpit support package (SP), see https://
help.sap.com/viewer/p/SAP_HANA_COCKPIT
● SAP HANA database explorer
SAP HANA Database Explorer
● SQL analyzer
Analyzing Statement Performance
● Support Log Assistant
The Support Log Assistant is a tool that allows you to automatically scan and analyze text les such as
logs, conguration les or traces. The tool will then suggest solutions to known issues found in the les and
highlight important details that it nds. The tool is integrated into the incident logging procedure and is
also available as a standalone tool; the following link is to a Support Portal getting started page which also
gives direct access to the Support Log Assistant.
Support Log Assistant
Alerts
Alert checkers run in the background and you are notied in case of potentially critical situations arising in your
system. In the SAP HANA cockpit, you can easily see in which areas you might need to take some action.
Reference: Alerts [page 243]
SAP Notes
SAP Notes are used to give detailed supplementary customer support information in addition to the formal set
of published documents. This troubleshooting guide includes many references to relevant SAP Notes. The
Alerts reference section, for example, gives links to corresponding notes for each system alert. Some other
FAQ-format SAP Notes which you may nd useful are listed here:
● SAP Note 2000003 - FAQ: SAP HANA
● SAP Note 1999997 - FAQ: SAP HANA Memory
SAP HANA Troubleshooting and Performance Analysis Guide
SAP HANA Troubleshooting and Performance Analysis Guide
P U B L I C 7

● SAP Note 2186744 - FAQ: SAP HANA Parameters
Guided Answers
Guided Answers is an interactive online support tool to help users to diagnose and solve problems using
decision trees. It covers many SAP products including SAP HANA and oers a set of step-by-step problem-
solving online documents each one designed to address a specic topic. Guided Answers is available in the
SAP Support portal at the following address:
https://ga.support.sap.com/dtp/viewer/
This troubleshooting guide includes links to specic trees where relevant. The following tree is a general high-
level troubleshooting tree for SAP HANA:
https://gad5158842f.us2.hana.ondemand.com/dtp/viewer/#/tree/1623/actions/21021
Further Resources
The following SAP HANA documents are important resources for working with SAP HANA and are often
referred to in this guide:
● SAP HANA Administration Guide
● SAP HANA SQL and System Views Reference
In particular, the SAP HANA Administration Guide gives general details on using the administration tools SAP
HANA cockpit and SAP HANA studio.
There is a central online portal for a variety of support resources for SAP products which is available from the
SAP ONE Support Launchpad Software Downloads : https://launchpad.support.sap.com/#/
softwarecenter
In the SAP Community Network (SCN) you can nd many support resources online including wikis, blogs,
reference materials and so on. This SCN wiki page, for example, provides links to many specialist topics: SAP
HANA In-Memory Troubleshooting Guide .
Both SAP HANA Academy and SAP Support oer YouTube channels with a wide range of support materials in
video format:
● https://www.youtube.com/user/saphanaacademy
● http://www.youtube.com/user/SAPSupportInfo
8
P U B L I C
SAP HANA Troubleshooting and Performance Analysis Guide
SAP HANA Troubleshooting and Performance Analysis Guide
2 Analyzing Generic Symptoms
The purpose of this section of the document is to help you to nd the probable root cause of some generic
problems and refer you to more detailed sections of the SAP HANA Troubleshooting and Performance Analysis
Guide to proceed with your analysis.
Performance issues may be dicult to diagnose; problems may be rooted in a number of seemingly unrelated
components. Checking for system alerts is a good starting point if you experience any trouble with your SAP
HANA system. If the system issues an alert, refer to the Reference: Alerts section to nd the part of this guide,
an SAP Note or Knowledge Base Article which addresses the problem.
However, alerts are congurable (see Memory Problems for information on conguring alerts) and do not cover
all aspects of the system, problems can still occur without triggering an alert. This section therefore describes
some generic symptoms which you may observe and helps you to analyze the underlying problem.
Related Information
Memory Problems [page 22]
Reference: Alerts [page 243]
2.1 Performance and High Resource Utilization
By observing the general symptoms shown by the system such as poor performance, high memory usage,
paging or column store unloads we can start to narrow down the possible causes as a rst step in analyzing the
issue.
High Memory Consumption
You observe that the amount of memory allocated by the SAP HANA database is higher than expected. The
following alerts indicate issues with high memory usage:
● Memory usage of name server (Alert 12)
● Total memory usage of Column Store tables (Alert 40)
● Memory usage of services (Alert 43)
● Memory usage of main storage of Column Store tables (Alert 45)
● Runtime dump les (Alert 46)
See the section Memory Problems for information on analyzing the root cause.
SAP HANA Troubleshooting and Performance Analysis Guide
Analyzing Generic Symptoms
P U B L I C 9

Out-of-Memory Situations
You observe trace les or error messages indicating an Out-of-Memory (OOM) situation.
See the section Memory Problems for information on analyzing the root cause.
Paging on Operating System Level
You observe that paging is reported on operating system level.
See the section Memory Problems for information on analyzing the root cause.
Column Store Unloads
You observe unloads in the column store. The following alerts indicate issues with high memory usage:
● Column store unloads (Alert 55)
See the section Memory Problems for information on analyzing the root cause.
Permanently Slow System
Issues with overall system performance can be caused by a number of very dierent root causes. Typical
reasons for a slow system are resource shortages of CPU, memory, disk I/O and, for distributed systems,
network performance.
Check Overview Monitoring and Administration Performance Monitor for either Memory, CPU or Disk
Usage. If you see a constant high usage of memory or CPU, proceed with the linked sections Memory Problems
or CPU Related Root Causes and Solutions respectively. I/O Related Root Causes and Solutions provides ways
to check for disk I/O related problems. In case of network performance issues, have a look at the Monitor
Network page accessible from the Monitoring group in the SAP HANA cockpit.
Note that operating system tools can also provide valuable information on disk I/O load. Basic network I/O
data is included in the Load graph and in the M_SERVICE_NETWORK_IO system view, but standard network
analysis tools can also be helpful to determine whether the network is the main bottleneck. If performance
issues only appear sporadically, the problem may be related to other tasks running on the database at the
same time.
These include not only maintenance related tasks such as savepoints (disk I/O, see I/O Related Root Causes
and Solutions) or remote replication (network I/O), but also SQL statements dispatched by other users, which
can block a lot of resources. In the case of memory, this can lead to unloads of tables, which aects future SQL
statements, when a table has to be reloaded into memory. In this case, see Memory Problems as well. Another
reason for poor performance, which in many cases cannot be detected by the SAP HANA instance itself, are
other processes running on the same host that are not related to SAP HANA. You can use the operating system
tools to check for such processes. Note that SAP only supports production systems running on validated
hardware.
10
P U B L I C
SAP HANA Troubleshooting and Performance Analysis Guide
Analyzing Generic Symptoms
Slow Individual SQL Statements or with Increasingly Long Runtimes
Issues with the performance of a particular statement can be caused by a number of very dierent root causes.
In principle, a statement can trigger all the resource problems that also lead to an overall slowdown of the
system, so most of the previous information also applies to statement performance. In addition, statement
performance can suer from transactional problems, that is, blocked transactions. Blocked transactions can
be checked in the Threads tile or on the Blocked Transactions page accessible from the Monitoring group. For
troubleshooting, proceed with Transaction Problems.
If the runtime of a statement increases steadily over time, there could be an issue with the delta merge
operation. Alerts should be issued for most problems occurring with the delta merge, but since they depend on
congurable thresholds, this is not always the case. For troubleshooting, proceed with Delta Merge. If you have
none of the above problems, but the statement is still too slow, a detailed Statement Performance Analysis
might reveal ways to optimize the statement. However, some queries are inherently complex and require a lot
of computational resources and time.
Related Information
Memory Problems [page 22]
CPU Related Root Causes and Solutions [page 39]
Disk Related Root Causes and Solutions [page 48]
I/O Related Root Causes and Solutions [page 55]
M_SERVICE_NETWORK_IO
Transactional Problems [page 111]
Delta Merge [page 68]
Statement Performance Analysis [page 121]
2.2 Common Symptoms and Troubleshooting
Typical symptoms and the related troubleshooting information are described in this section.
System-side slow performance, slow individual statement performance, and OOM problems are issues that
you might experience while using the SAP HANA database. For each section, this document will cover the
known symptoms and the corresponding troubleshooting steps to follow depending on the causes.
SAP HANA Troubleshooting and Performance Analysis Guide
Analyzing Generic Symptoms
P U B L I C 11

2.2.1 Slow System-wide Performance
Slow system-wide performance issues are problems that could be caused by excessive use of CPU, database
resource locks or incorrect conguration of OS parameters.
Generally, when you encounter a performance issue, you may see these symptoms in SAP HANA cockpit:
● Continually high CPU usage according to OS commands or load graph (visible from CPU Usage tile -
Performance Monitor)
● Many pending or waiting threads in the thread view (details visible from the Threads tile).
To look for the cause at the operating system level refer to the topic System Appears to Hang with High System
CPU Usage.
If the performance issue persists or if it recurs sporadically you may need to contact Support to analyze the
root cause. In this case please generate at least two runtime dumps at 3 minute intervals while the system
performance is slow for further investigation. For details refer to SAP Note 1813020 - How to generate a runtime
dump on SAP HANA or the Guided Answer How to generate a runtime dump.
Related Information
System Appears to Hang with High System CPU Usage [page 13]
SAP Note 1813020
How to generate a runtime dump (Guided Answer)
2.2.1.1 System Appears to Hang with no new Connections
and no Response from DML
In cases where logs cannot be written, all DML statement will fall into wait status. This can lead to a failure of
opening new connections because the system internally executes DML statements during the process.
Typically, a full log volume is the cause for this.
Root cause: Log volume full either caused by disk full or quota setting
Required action:
1. Check DISKFULL event in indexserver trace or
2. Run "df -h" in OS shell or
3. Check quota setting in le system
4. Then, follow the procedure described in SAP Note 1679938 - Log Volume is full.
You can nd additional information in SAP Note 2083715 - Analyzing log volume full situations.
Root cause: log volume full caused by failure of log backup
Required action:
1. Check backup.log (located at /usr/sap/<SID>/HDB<Instance#>/<Host>/trace ) to see whether it
includes ERROR in log backup. Check M_BACKUP_CATALOG, M_LOG_SEGMENTS.
12
P U B L I C
SAP HANA Troubleshooting and Performance Analysis Guide
Analyzing Generic Symptoms

2. If log backup uses backint, please check backint.log (located at /usr/sap/<SID>/HDB<Instance#>/
<Host>/trace ) to see whether it includes ERROR information, and contact backint vendor support. With
certain revision and conditions, the conict between savepoint lock and DML lock blocks subsequent
statements when long running update/insert statements exist. Please contact SAP support if you
encounter the next case described below.
Root cause: Savepoint lock conict with long running update
Required action:
1. Collect runtime dump as per SAP Note 1813020 - How to generate a runtime dump on SAP HANA and look
for the following call stacks in many threads.
…
DataAccess::SavepointLock::lockShared(…)
DataAccess::SavepointSPI::lockSavepoint(…)
…
And one of the following call stacks that is in the savepoint phase.
…
DataAccess::SavepointLock::lockExclusive()
DataAccess::SavepointImpl::enterCriticalPhase(…)
…
2. Check whether the symptoms match the description in SAP Note 2214279 - Blocking situation caused by
waiting writer holding consistent change lock. If so, apply the parameter in the Note.
3. Create a support ticket attaching a runtime dump for further analysis.
Related Information
SAP Note 1679938
SAP Note 2083715
SAP Note 1813020
SAP Note 2214279
2.2.1.2 System Appears to Hang with High System CPU
Usage
The SAP HANA database is an in-memory database and by its nature, it consumes large amounts of memory.
Therefore, some performance issues of SAP HANA can be caused by the OS's memory management.
For this case, you can see high usage of SYSTEM CPU that can be monitored in the Performance Monitor,
available from SAP HANA cockpit Monitoring and Administration CPU Usage .
Root cause: Problem caused by the conguration of transparent huge page
Required action:
1. Check Transparent Huge Page whether it is set to [never] by running the command "cat /sys/kernel/mm/
transparent_hugepage/enabled".
SAP HANA Troubleshooting and Performance Analysis Guide
Analyzing Generic Symptoms
P U B L I C 13

2. Apply KBA 2031375 - SAP HANA: Transparent HugePages (THP) setting on Linux.
Root cause: Problem caused by the conguration of OS page cache
Required action:
1. Check sar le ( /var/log/sa ) whether kbcached usage ( sar -r ) is higher than 10% of physical memory and
high page in/out occurred.
2. Check and apply SAP Note 1557506 - Linux paging improvements.
Root cause: Problem caused by translation lookaside buer (TLB) shootdown
Required action:
1. Check plan trace. For more information, see SAP Note 2206354 - SAP HANA DB: High System CPU
Consumption Caused by Plan Trace.
Root cause: Due to high context switches (High SYS CPU) by many SqlExecutor threads
Required action:
1. Check Performance Monitor and indexserver.ini -> sql -> sql_executors / max_sql_executors and refer to
Controlling Parallelism of SQL Statement Execution.
Root Cause: Due to high context switches (High SYS CPU) by many JobExecutor threads
Required action: Check that the following parameters are set to be bigger than the number of logical CPU
cores:
1. indexserver.ini -> parallel -> num_cores (<=SPS07) and refer to Controlling Parallelism of SQL Statement
Execution
2. global.ini/indexserver.ini -> execution -> max_concurrency (>SPS08)
Related Information
Controlling Parallel Execution of SQL Statements [page 42]
SAP Note 2031375
SAP Note 1557506
SAP Note 2206354
System Hanging Situations [page 144]
2.2.1.3 Slower Response with High User CPU Usage
The performance may degrade with increased usage of the CPU and applications.
Root cause: Not many executor threads but high CPU in a few nodes and a few tables accessed
Required Action: In an SAP Business Warehouse system, check for non-even partitioning of huge column
tables. For more information, see SAP Note 1819123 - BW on SAP HANA SP5: landscape redistribution and
Indicator for Large Delta Storage of Column Store Tables.
Root Cause: Performance degradation by huge MVCC versions
14
P U B L I C
SAP HANA Troubleshooting and Performance Analysis Guide
Analyzing Generic Symptoms

Required Action: Check for KPI Active Version in the Performance Monitor to nd the MVCC garbage
blocker, then kill it via the Threads tile on the Overview page. For more information, see Troubleshooting Blocked
Transactions.
Related Information
Indicator for Large Delta Storage of Column Store Tables [page 70]
Troubleshooting Blocked Transactions [page 114]
SAP Note 1819123
2.2.2 Slow Individual SQL Statements
This section looks at the causes of slow individual SQL statements although there is no signicant performance
issue on system level and the associated troubleshooting steps.
If the following doesn’t help to resolve the problem, see Getting Support. In this case, to analyze further, collect
the explain plan, plan visualizer le, performance trace and catalog export. Also refer to SQL Statement
Analysis and Query Plan Analysis for more information. SAP KBA 2000002 - FAQ: SAP HANA SQL Optimization
explains general information about SQL optimization.
Related Information
SQL Statement Analysis [page 180]
Query Plan Analysis [page 190]
SAP Note 2000002
Getting Support
2.2.2.1 A Statement is Sometimes Slow and Sometimes
Fast
There are a number of things to check when you experience inconsistent query execution time.
Check the following possibilities:
Root Cause: If a related table was unloaded, it takes some time to load tables
Required Action: Check unload trace and execute after table loaded fully. You can refer to LOADED column of
M_CS_TABLES.
Root Cause: Query compilation time is long.
Required Action: Check the execution time after adding 'with hint (ignore_plan_cache)' at the end of query.
This hint will always cause the query to be compiled. If a long running compiled query plan has been evicted
SAP HANA Troubleshooting and Performance Analysis Guide
Analyzing Generic Symptoms
P U B L I C 15
frequently from the plan cache, increase the query cache size. For more information, see SQL Plan Cache
Analysis.
Root Cause: Merge status of column table can aect query plan
Required Action: Check MEMORY_SIZE_IN_DELTA, RAW_RECORD_COUNT_IN_DELTA, and
LAST_MERGE_TIME columns of M_CS_TABLES whether there is large amount of data in delta. Check
M_DELTA_MERGE_STATISTICS to see when the last merge occurred. For more information, see Delta Merge.
Related Information
SQL Plan Cache Analysis [page 126]
Delta Merge [page 68]
2.2.2.2 A Statement is Slower After an Upgrade
After upgrade, the query execution time can be dierent because of changes in the query execution plan.
Root cause: After an upgrade, a query can have a dierent plan, which leads to a dierent execution time.
Required Action: If you have an instance running on an older revision, compare the plan and collect the plan
visualizer le. See Getting Support for further help.
Refer also to the SQL Plan Stability section of this guide; this feature oers the option to preserve a query's
execution plan by capturing an abstraction of the plan and reusing it after the upgrade to regenerate the
original plan and retain the original performance.
For more information, see Expensive SQL Statements.
Related Information
Expensive SQL Statements [page 32]
Analyzing SQL Execution with the Plan Visualizer [page 195]
SQL Plan Stability [page 227]
Getting Support
2.2.2.3 A Query on Multiple Nodes can be Slower
In distributed systems, query execution can be routed to other nodes for better performance. However, there is
a chance of having slow performance in the case where the network used for transferring intermediate results
generated during query execution is slow or where there is an inecient network conguration.
Root cause: A miscongured network can lead to slow queries.
16
P U B L I C
SAP HANA Troubleshooting and Performance Analysis Guide
Analyzing Generic Symptoms

Required Action: Check your network conguration and its bandwidth/latency among SAP HANA servers. For
more information see Network View and SAP Note 2183363 - Conguration of SAP HANA internal network.
Root cause: Statement routing and huge data transfer among distributed nodes can cause dierences of
query execution times due to the dierence of anchor nodes.
Required Action: Check how much data is transferred among distributed nodes and the network performance.
Consider the locations of joined tables to reduce transferred intermediate result size.
Related Information
Network View [page 203]
Performance Trace [page 231]
SAP Note 2183363
2.2.2.4 Slow Select for all Entries (FAE) Query
There are a number of points to check if you have performance issues with SELECT FOR ALL ENTRIES (FAE)
from an ABAP query.
For FAE on SAP HANA, please generally refer to SAP Note 1662726 - Optimization of select with FOR ALL
ENTRIES on SAP HANA database.
Root cause: Indexes are missing.
Required Action: Check WHERE clause and check concat indexes for all elds used in WHERE clause.
Root cause: Due to DBSL behavior, slower operator can be chosen.
Required Actions: Apply parameters for ABAP optimization. For more information, see SAP Note 1987132 -
SAP HANA: Parameter setting for SELECT FOR ALL ENTRIES.
Root cause: When using less than or greater than ('<' or '>') lters in FAE query, it can be slower than having no
lter.
Required Actions: Do not use less than or greater than ('<' or '>') lters in an FAE query.
Related Information
SAP Note 1662726
SAP Note 1987132
SAP HANA Troubleshooting and Performance Analysis Guide
Analyzing Generic Symptoms
P U B L I C 17

2.2.2.5 All Statements Accessing a Specic Table are Slow
In case queries run on specic tables are slow, check if there are too many versions.
Root cause: If there are too many versions of single records, accessing the table can be slow. In this case, the
number of system-wide MVCC versions is in acceptable range. To verify further whether there are too many
versions for a specic table, check the result of this query:
SELECT * FROM M_RS_TABLE_VERSION_STATISTICS where table_name='mytable';
This can be caused by a cursor unnecessarily being held on a query result or a long-lived transaction without a
commit/rollback.
Required Action: Applications should commit as early as possible or close any cursors that are not needed.
Check the application logic to see whether it really needs to update single records frequently.
2.2.3 Frequent Out of Memory (OOM)
If Out Of Memory situations happen frequently, it can also lead to performance drop by unloading tables or
shrinking memory jobs.
First check Memory Problems and SAP KBA 1999997 - FAQ: SAP HANA Memory as they provide information on
SAP HANA memory and its problems.
This section introduces common problems and their troubleshooting steps.
Related Information
Memory Problems [page 22]
SAP Note 1999997
2.2.3.1 Out of Memory Caused by Sudden Increased
Memory Usage
Check the memory consumption of statements in the event of OOMs caused by suddenly increased memory
usage.
Root cause: Huge intermediate results during query processing.
Required Actions: Enable memory tracking by setting the following parameters to on in the global.ini le
resource_tracking section.
● enable_tracking = on
● memory_tracking = on
Enable the Expensive Statement Trace by setting the status to Active.
18
P U B L I C
SAP HANA Troubleshooting and Performance Analysis Guide
Analyzing Generic Symptoms

Then, check the memory consumption of statements using M_EXPENSIVE_STATEMENTS.MEMORY_SIZE.
After your analysis you can optimize any problematic queries that were found.
2.2.3.2 Out of Memory Caused by Continuously Increased
Memory Usage
Check if many statements trigger an Out Of Memory in a system where used memory is continuously
increased.
Root cause: Commit/rollback within stored procedure can lead to memory leakages. Do not use
exec(“commit”) or exec(“rollback”) within a stored procedure. If this syntax is used, the system cannot reclaim
the memory used for query execution because its related transactions are left hanging.
Required Actions: Remove exec(“commit”) or exec(“rollback”). If you would like to use commit/rollback within
stored procedure, see SAP HANA SQLScript Reference for more information.
Root cause: Due to memory leakage caused by a programming error
Required Action: Check the Performance Monitor in SAP HANA cockpit Overview Memory Usage to
determine whether used memory continuously increases without a signicant increase in data size. If you nd
a suspicious component which keeps allocating memory, create a support ticket attaching a full system dump,
mm trace, and the output of _SYS_STATISTICS.HOST_HEAP_ALLOCATORS_BASE.
Related Information
SAP HANA SQLScript Reference
2.2.3.3 Out of Memory While High Usage Of Column Store
Components' Allocators
If a system is undersized, Out Of Memory (OOM) can happen frequently.
Root cause: Undersized memory
Required Action:
1. Check top allocators in [MEMORY_OOM] section of OOM dump to see whether they are for column store
components as described in section 13 of KBA 1999997 - FAQ: SAP HANA Memory.
2. Check the unload trace whether frequent unloading of tables took place.
3. Reduce the amount of data in column store or increase physical memory.
SAP HANA Troubleshooting and Performance Analysis Guide
Analyzing Generic Symptoms
P U B L I C 19

Related Information
SAP Note 1999997
2.2.3.4 Out of Memory Caused by Large Memory Usage of
Statistics Server
This case can happen if the majority of memory used by the statisticsserver is due to many alerts or
undersized memory.
Root cause: Due to big STATISTICS_ALERTS_BASE table size, an OOM can occur.
Required Action: Check table size of _SYS_STATISTICS.STATISTICS_ALERTS_BASE and truncate
STATISTICS_ALERTS_BASE from hdbsql based on solution from SAP Note 2170779 - SAP HANA DB: Big
statistics server table leads to performance impact on the system.
Root cause: Big Pool/Statistics allocator size
Required Action: Check SAP Note 2147247 - FAQ: SAP HANA Statistics Server rst.
Related Information
SAP Note 2170779
SAP Note 2147247
2.2.3.5 Out of Memory Occurs due to High Usage of Shared
Memory
Shared memory is space where system information and row store tables are stored.
Check the following if the used amount of shared memory is high.
Root cause: Severely fragmented row store tables
Required action:
1. Check whether SHARED_MEMORY in [MEMORY_OOM] -> IPMM short info of OOM dump is unusally high.
2. Apply SAP Note 1813245 - SAP HANA DB: Row store reorganization.
Root cause: Memory shortage is caused by high usage of memory of row store tables in an SAP Business
Warehouse (BW) system
Required action: In an SAP Business Warehouse system the used amount of shared memory is high and SAP
Note 1813245 doesn't recommend row store reorganization, rst apply SAP Note 706478 - Preventing Basis
tables from increasing considerably, then apply SAP Note 1813245 - SAP HANA DB: Row store reorganization
again.
20
P U B L I C
SAP HANA Troubleshooting and Performance Analysis Guide
Analyzing Generic Symptoms

Root cause: Memory shortage is caused by high usage of memory of row store tables in non-SAP Business
Warehouse (BW) systems
Required Action: Check if you can convert some row store tables into column store tables or archive old data
to reduce the memory size, or else increase the system memory.
Related Information
SAP Note 1813245
SAP Note 706478
SAP HANA Troubleshooting and Performance Analysis Guide
Analyzing Generic Symptoms
P U B L I C 21

3 Root Causes and Solutions
This section provides detailed information on the root causes of problems and their solutions.
System alerts are a good indicator for the underlying problem. The SAP Notes you will be directed to are a
source of background information, explanations, alternative options, FAQs or useful SQL statements, for
example. Detailed monitoring and administration of the SAP HANA databases is possible via the SAP HANA
cockpit and the SAP HANA database explorer.
3.1 Memory Problems
This section discusses the analysis steps that are required to identify and resolve memory related issues in the
SAP HANA database.
For more general information on SAP HANA memory management, see the whitepaper SAP HANA Memory
Usage Explained which discusses the memory concept in more detail. It also explains the correlation between
Linux indicators (virtual and resident memory) and the key memory usage indicators used by SAP HANA.
Alerts related to memory problems and corresponding SAP Notes are documented in the Alerts reference table
(see category 'Memory'). SAP Note 1840954 – Alerts related to HANA memory consumption includes
information on how to analyze out-of-memory (OOM) dump les.
The SAP HANA Administration Guide gives details on using the tool SAP HANA cockpit to analyze memory
problems.
In order to understand the current and historic SAP HANA memory consumption you can use the following
tools and approaches:
● Memory information in SAP HANA cockpit
● Memory information from logs and traces
● Memory information from SQL commands
● Memory information from other tools (see the tools overview in the SAP HANA Administration Guide).
Related Information
SAP HANA Memory Usage Explained
SAP Note 1840954
SAP HANA Administration Guide
22
P U B L I C
SAP HANA Troubleshooting and Performance Analysis Guide
Root Causes and Solutions
3.1.1 Memory Information in SAP HANA Cockpit
There are a number of sources of information in SAP HANA cockpit that can assist you in understanding
memory utilization.
● Open the Manage Services page from the Overall Database Status tile for high-level information about
physical memory, allocation limit, and used memory for each service.
● To get a graphical overview about physical memory, allocation limit, used memory, and resident memory
open the Performance Monitor from the Memory Usage tile.
● Open the Memory Analysis app from the Memory Usage tile for details about memory utilization as well as
history information. For example, click the Components tab in the Memory Analysis app to view the used
memory grouped by dierent components like "Statement Execution & Intermediate Results" or "Column
Store Tables". When you choose a component, the corresponding historic information of memory usage is
displayed by a graph.
3.1.2 Memory Information from Logs and Traces
In case of critical memory issues you can often nd more detailed information in logs and trace les.
● Try to identify memory-related errors in the alert trace les in the SAP HANA database explorer (accessible
via the View trace and diagnostic les link). Search for the strings “memory”, “allocat”, or “OOM” (case-
insensitive).
● Check if an out-of-memory (OOM) trace le was created.
● Investigate error messages seen on the application side that occurred at times of high memory usage. If
the application is an SAP NetWeaver system, good starting points for analysis are System Log (SM21),
ABAP Runtime Error (ST22), and Job Selection (SM37).
If help from SAP Customer Support is needed to perform an in-depth analysis, the following information is
valuable and should be added to the ticket:
● Diagnosis information (full system info dump). To collect this information, see section Diagnosis
Information.
● Performance trace provides detail information on the system behavior, including statement execution
details. To enable this trace, see section Performance Trace.
The trace output is written to a trace le perftrace.tpt, which must be sent to SAP Customer Support. If
specic SAP HANA system components need deeper investigation, SAP Customer Support can ask you to
raise the corresponding trace levels to INFO or DEBUG, rerun the query and then send the indexserver trace
les to SAP Customer Support.
To do so choose Trace Conguration in the SAP HANA database explorer and launch the Database Trace wizard.
The following illustration shows the example of enabling the join engine trace (join_eval). You can enter a
search string and then select the component in the indexserver.ini le and change the System Trace Level
to the appropriate value. Some trace components (such as debug trace details for join engine) can create
many megabytes of trace information and may also require an increase of the values maxfiles and
maxfilesize in the [trace] section of the global.ini le (see also SAP Note 2629103 - SQL Traces Stop
Writing When it Exceeds the Maximum Filesize).
SAP HANA Troubleshooting and Performance Analysis Guide
Root Causes and Solutions
P U B L I C 23
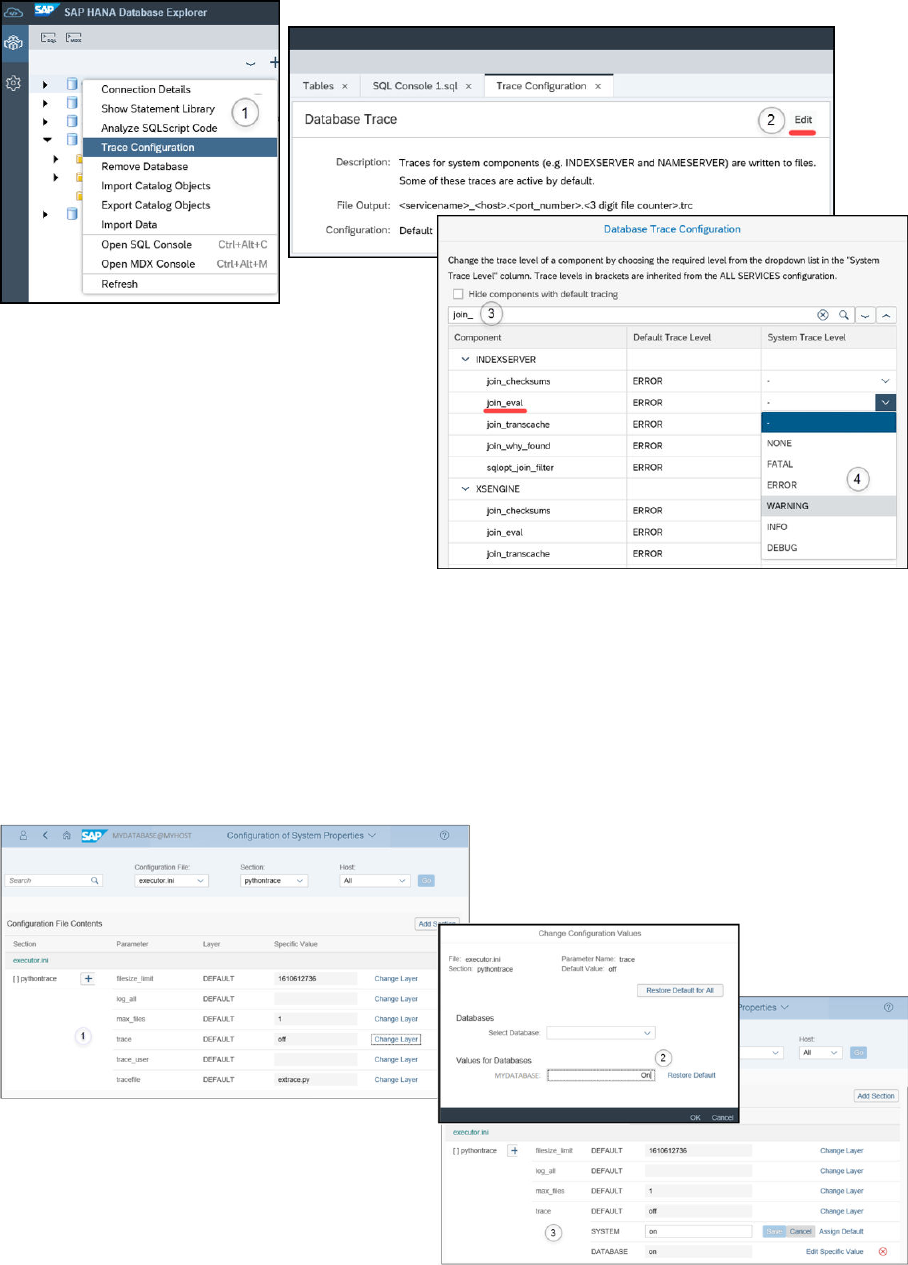
Internal details about SQL statement execution can be collected by enabling the Executor Trace; this provides
the highest level of detail and should only be activated for the short time of query execution. After capturing the
trace details you can upload the trace le (extrace.py) to SAP Customer Support. This trace is enabled by
activating a conguration parameter as described and illustrated here.
Open the Conguration of System Properties view, edit the parameter trace in the [pythontrace] section of the
executor.ini le, and change its value to on. When you change the default value, you have the option to set
values at each specic layer. The trace parameter is o by default. Click Change Layer to turn the parameter
on. You can then change the conguration value for a selected database and for a selected layer:
24
P U B L I C
SAP HANA Troubleshooting and Performance Analysis Guide
Root Causes and Solutions

Related Information
Diagnosis Information [page 234]
Performance Trace [page 231]
SAP Note 2629103
3.1.3 Memory Information from SQL Commands
There are a number of ways to analyze memory usage based on pre-dened and modiable SQL queries.
The Statement Library of SAP HANA database explorer provides a set of tabular views to display the memory
consumption of loaded tables based on pre-dened SQL queries:
● The view Component Memory Usage shows the aggregated memory consumption in bytes for dierent
heap memory service components, services, and ports. Order by the used memory size column and nd
the largest consumers. The following heap memory service components are available: 1) Column Store
Tables, 2) Row Store Tables, 3) Statement Execution & Intermediate Results, 4) Monitoring & Statistical
Data, 5) Caches, 6) System, 7) Code Size, 8) Stack Size.
● The view Schema Size of Loaded Tables displays the aggregated memory consumption of loaded tables in
MB for dierent database schemas. The aggregation comprises both column store and row store tables.
Order by the schema size column and nd the largest consumers.
● The view Used Memory by Tables shows two values: the total memory consumption of all column store
tables in MB and the total memory consumption of all row store tables in MB.
Note
You can nd this and other information in the Memory Analysis app of the SAP HANA cockpit. For more
information, see Analyze Memory Statistics in the SAP HANA Administration Guide.
SAP Note 1969700 – SQL Statement Collection for SAP HANA contains several commands that are useful to
analyze memory-related issues. Based on your needs you can congure restrictions and parameters in the
sections marked with /* Modification section */.
Some of the memory-related statements which you may nd useful are described here.
HANA_Memory_Overview
This query gives an overview of current memory information showing key values in the following columns:
● NAME: Description
● TOTAL_GB: Total size (GB)
● DETAIL_GB: Size on detail level (GB) – this is shown at two levels with a breakdown at a second level – see
the following table:
NAME
TOTAL_GB DETAIL_GB DETAIL2_GB
User-dened global allocation limit not set
License memory limit 256
License usage 143 124 (2014/03/01-2014/03/31)
SAP HANA Troubleshooting and Performance Analysis Guide
Root Causes and Solutions
P U B L I C 25

NAME TOTAL_GB DETAIL_GB DETAIL2_GB
143 (2014/04/01-2014/04/30)
113 (2014/05/01-2014/05/09)
Physical memory 256 256 (vhbshk0sdb)
HANA instance memory
(allocated)
113 113 (vhbshk0sdb)
HANA instance memory (used) 85 85 (vhbshk0sdb)
HANA shared memory 23 23 (vhbshk0sdb)
HANA heap memory (used) 52 52 (vhbshk0sdb) 10 (Pool/NameIdMapping/
RoDict)
HANA_Memory_TopConsumers_History
This query displays areas with the highest historical memory requirements (column store and row store tables,
heap, code, stack). The following columns contain the key values:
● SAMPLE_TIME: Timestamp
● KEY_FIGURE: Memory key gure
● VALUE_TOTAL: Total value of memory key gure
● DETAIL_<n>: Top <n> detail area related to memory key gure
● VALUE_<n>: Memory key gure value of top <n> detail area
● PCT_<n>: Fraction of overall value occupied by top <n> detail area (%)
SAMPLE_TIME
KEY_FIGURE
VALUE_TOT
AL DETAIL_1 VALUE_1 PCT_1
2014/04/22(TUE) Space used (GB) 408.55 Pool/PersistenceManager/
PersistentSpace(0)/DefaultLPA/Page
85.94 21
2014/04/21(MON) Space used (GB) 382.82 Pool/PersistenceManager/
PersistentSpace(0)/DefaultLPA/Page
90.44 24
2014/04/20(SUN) Space used (GB) 437.76 Pool/PersistenceManager/
PersistentSpace(0)/DefaultLPA/Page
126.20 29
2014/04/19(SAT) Space used (GB) 513.70 Pool/PersistenceManager/
PersistentSpace(0)/DefaultLPA/Page
133.29 26
2014/04/18(FRI) Space used (GB) 445.53 Pool/PersistenceManager/
PersistentSpace(0)/DefaultLPA/Page
112.35 25
2014/04/17(THU) Space used (GB) 363.30 Pool/RowEngine/QueryExecution 72.54 20
2014/04/16(WED) Space used (GB) 487.59 Pool/RowEngine/QueryExecution 104.39 21
2014/04/15(TUE) Space used (GB) 588.56 Pool/PersistenceManager/
PersistentSpace(0)/DefaultLPA/Page
168.21 29
26 P U B L I C
SAP HANA Troubleshooting and Performance Analysis Guide
Root Causes and Solutions

SAMPLE_TIME KEY_FIGURE
VALUE_TOT
AL DETAIL_1 VALUE_1 PCT_1
2014/04/14(MON) Space used (GB) 3484.97 Pool/JoinEvaluator/
JERequestedAttributes/Results
2795.20 80
2014/04/13(SUN) Space used (GB) 572.90 Pool/PersistenceManager/
PersistentSpace(0)/DefaultLPA/Page
175.60 31
2014/04/12(SAT) Space used (GB) 477.98 Pool/PersistenceManager/
PersistentSpace(0)/DefaultLPA/Page
111.76 23
2014/04/11(FRI) Space used (GB) 491.72 Pool/PersistenceManager/
PersistentSpace(0)/DefaultLPA/Page
119.74 24
2014/04/10(THU) Space used (GB) 463.47 Pool/PersistenceManager/
PersistentSpace(0)/DefaultLPA/Page
100.82 22
HANA_Tables_LargestTables
This query provides an overview of current memory allocation by tables. The following list explains the columns
displayed in the table:
● OWNER: Name of the table owner
● TABLE_NAME: Name of the table
● S: Table store ('R' for row store, 'C' for column store)
● HOST: Host name ('various' in case of partitions on multiple hosts)
● U: 'X' if at least one unique index exists for the table
● POS: Position of table in top list
● COLS: Number of table columns
● RECORDS: Number of table records
● SUM_DISK_GB: Total size on disk (in GB, table + indexes + LOB segments)
● SUM_MEM_GB: Total potential maximum size in memory (in GB, table + indexes + LOB segments)
OWNER
TABLE_NAME S HOST U POS COLS RECORDS
SUM_DIS
K_GB
SUM_ME
M_GB
SAPSR3 /BIC/AZOCEUO0500 C various X 1 16 877829360 63.90 76.15
SAPSR3 /BIC/AZOCZZO0400 C various X 2 33 965035392 63.45 70.10
SAPSR3 RSMONMESS R erslha33 X 3 19 170801504 27.92 54.21
SAPSR3 /BIC/AZFIGLO1300 C various X 4 60 652633189 47.20 53.23
SAPSR3 /BIC/AZSCXXO4400 C various X 5 26 1251448665 47.78 53.04
SAPSR3 /BIC/AZOCEUO0800 C various X 6 17 911830438 37.86 52.42
SAPSR3 /BIC/AZOCZZO2000 C various X 7 34 1200422292 46.50 50.08
SAP HANA Troubleshooting and Performance Analysis Guide
Root Causes and Solutions
P U B L I C 27

OWNER TABLE_NAME S HOST U POS COLS RECORDS
SUM_DIS
K_GB
SUM_ME
M_GB
SAPSR3 RSWR_DATA R erslha33 X 8 10 20471 36.88 36.88
SAPSR3 RSRWBSTORE C erslha33 X 9 5 14483956 36.18 36.20
SAPSR3 /BIC/AZMIEUO0200 C various X 10 52 403915330 28.58 33.05
SAPSR3 /BIC/AZSCXXO2900 C various X 11 275 183029330 30.82 29.26
SAPSR3 /BIC/AZSCXXO4700 C various X 12 42 648103462 27.38 28.83
SAPSR3 /BIC/FZRREUC16B C erslha35 13 122 258261262 26.43 24.99
SAPSR3 /BIC/AZOCEUO9000 C various X 14 16 251896248 20.53 23.71
SAPSR3 RSBMNODES R erslha33 X 15 12 130344869 13.67 20.25
SAPSR3 /BIC/AZSCXXO1400 C various X 16 279 164509638 18.49 19.82
SAPSR3 /BIC/AZOCEUO0300 C various X 17 27 577787981 17.95 19.60
SAPSR3 EDI40 R erslha33 X 18 7 5733625 18.26 18.40
SAPSR3 /BIC/FZOCZZC20 C various 19 34 1427403108 18.97 17.80
SAPSR3 /BIC/AZSCXXO2600 C various X 20 306 95251083 16.65 16.97
SAPSR3 /BIC/AZSCXXO0800 C various X 21 266 120598787 18.76 15.62
SAPSR3 /BIC/AZSPXXO0200 C various X 22 48 270975902 12.63 15.30
SAPSR3 /BIC/AZOCZZO5000 C various X 23 33 215732874 14.16 14.92
SAPSR3 /BIC/AZSPXXO0300 C various X 24 56 275036362 13.09 14.77
SAPSR3 /BIC/AZOCEUO0600 C various X 25 16 663581081 12.29 14.34
SAPSR3 /BIC/AZOCZZO0700 C various X 26 41 350819182 15.00 14.32
SAPSR3 /BIC/FZRREUC16D C erslha40 27 122 146620284 15.39 14.06
SAPSR3 /BIC/AZMDEUO0800 C various X 28 246 151145647 15.39 14.00
SAPSR3 /BIC/AZMIEUO1300 C various X 29 16 406548712 11.52 13.35
SAPSR3 /BIC/AZRREUO0100 C various X 30 167 202422848 15.36 13.24
HANA_Memory_SharedMemory
28
P U B L I C
SAP HANA Troubleshooting and Performance Analysis Guide
Root Causes and Solutions

This query shows currently used and allocated shared memory per host and service. The following list explains
the columns displayed in the table:
● HOST: Host name
● PORT: Port name
● SERVICE_NAME: Service name
● SHM_ALLOC_GB: Allocated shared memory (GB)
● SHM_USED_GB: Used shared memory (GB)
● SHM_USED_PCT: Percentage of allocated memory used
HOST
PORT SERVICE_NAME SHM_ALLOC_GB SHM_USED_GB SHM_USED_PCT
MyHost01 31001 nameserver 0.13 0.02 18.64
MyHost01 31002 preprocessor 0.00 0.00 0.00
MyHost01 31003 indexserver 24.50 11.21 45.76
MyHost01 31005 statisticsserver 0.14 0.03 22.98
MyHost01 31006 webdispatcher 0.00 0.00 0.00
MyHost01 31007 xsengine 0.14 0.03 22.96
MyHost01 31010 compileserver 0.00 0.00 0.00
Related Information
SAP Note 1969700
Analyze Memory Statistics
3.1.4 Memory Information from Other Tools
Other tools are also available to analyze high memory consumption and out-of-memory situations.
A number of SAP Notes and 'How-to' documents are available to provide help with some of the most common
questions and diculties related to memory. The tool hdbcons provides expert functionality to analyze
memory issues. You can use this tool (typically with guidance from the SAP Customer Support team) to create
runtime dump les and analyze the details of memory consumption. If necessary, dump les can be sent to
Customer Support for further analysis.
The following SAP Notes may be helpful in solving some problems and when analyzing memory issues with
hdbcons.
Tip
Guided Answers is a support tool for troubleshooting problems using decision trees. A guided answer is
available for How to troubleshoot HANA High Memory Consumption.
SAP HANA Troubleshooting and Performance Analysis Guide
Root Causes and Solutions
P U B L I C 29

Related Information
SAP Note 1999997
SAP Note 2400007
SAP Note 2222218
SAP Note 1786918
SAP Note 1813020
SAP Note 1984422
How to troubleshoot HANA High Memory Consumption (Guided Answer)
3.1.5 Root Causes of Memory Problems
Once you have completed your initial analysis, you have the information required to start the next phase of your
analysis.
Based on the results from the analysis approaches you are now able to answer the following questions:
● Is it a permanent or a sporadic problem?
● Is the memory consumption steadily growing over time?
● Are there areas with critical memory consumption in heap, row store or column store?
● Is there a big dierence between used memory and allocated memory?
In the following you can nd typical root causes and possible solutions for the dierent scenarios.
3.1.5.1 Signicant External Memory Consumption
If the database resident memory of all SAP HANA databases on the same host is signicantly smaller than the
total resident memory, you have to check which processes outside of the SAP HANA databases are responsible
for the additional memory requirements.
Typical memory consumers are:
● Operating system (for example, caches, mapping structures)
● Third party tools (for example, backup, virus scanner)
How to identify top memory consumers from non-SAP HANA processes is out of scope of this guide. However,
when you are able to identify the reason for the increased memory consumption of the external program, you
can check if it is possible to optimize its conguration.
3.1.5.2 Space Consumed by Large Tables
If particularly large tables consume signicant amounts of space in the row store or column store, you should
check if the amount of data can be reduced.
The following references will be helpful:
30
P U B L I C
SAP HANA Troubleshooting and Performance Analysis Guide
Root Causes and Solutions

● SAP Note 2388483 - How To: Data Management for Technical Tables describes archiving and deletion
strategies for typical SAP tables with a technical background; for example, tables required for
communication, logging or administration.
● General recommendations for managing data can be found on the Information Lifecycle Management page.
For more information on memory management for resident table data, see Managing Tables in the SAP HANA
Administration Guide and the following SAP Notes:
● SAP Note 2222277 - FAQ: SAP HANA Column Store and Row Store
● SAP Note 2220627 - FAQ: SAP HANA LOBs
● SAP Note 2388483 - How-To: Data Management for Technical Tables
Related Information
https://www.sap.com/products/information-lifecycle-management.html
Managing Tables
SAP Note 2222277
SAP Note 2220627
SAP Note 2388483
3.1.5.3 Internal Columns in the Column Store
For several reasons, SAP HANA creates internal columns in the column store. Some column store tables are
automatically loaded into memory.
Internal Columns
You may be able to optimize or remove internal columns in order to reduce memory usage. In some situations a
cleanup is possible, for example, in the case of CONCAT attribute columns that were created in order to
support joins. For more information see SAP Note 1986747: How-To: Analyzing Internal Columns in SAP HANA
Column Store.
Column Store Table Loads and Unloads
The SAP HANA system dynamically loads column store tables into memory during system restart and when
required by the application. You may be able to optimize the number of pre-loaded tables. For more
information, see SAP Note 2127458: FAQ: SAP HANA Loads and Unloads.
Related Information
SAP Note 2127458
SAP Note 1986747
SAP HANA Troubleshooting and Performance Analysis Guide
Root Causes and Solutions
P U B L I C 31

3.1.5.4 Memory Leaks
A memory leak is a memory area (typically a heap allocator) that grows over time without any apparent reason.
If you have identied a suspicious area, proceed as follows:
● Check for SAP Notes that describe the memory leak and provide a solution.
● Check if the problem is reproducible with a recent SAP HANA revision.
● If you can’t resolve the problem yourself, open an SAP customer message and use the component HAN-
DB.
3.1.5.5 Large Heap Areas
Some heap areas can be larger than necessary without being a memory leak.
SAP Note 1840954 – Alerts related to HANA memory consumption contains an overview of heap allocators with
a potentially large memory consumption and possible resolutions.
Related Information
SAP Note 1840954
3.1.5.6 Expensive SQL Statements
SQL statements processing a high amount of data or using inecient processing strategies can be responsible
for increased memory requirements.
See SQL Statement Analysis for information on how to analyze expensive SQL statements during times of peak
memory requirements.
Related Information
SQL Statement Analysis [page 180]
Setting a Memory Limit for SQL Statements [page 35]
Analyzing Expensive Statements Traces [page 185]
32
P U B L I C
SAP HANA Troubleshooting and Performance Analysis Guide
Root Causes and Solutions
3.1.5.7 Transactional Problems
High memory consumption can be caused by problems with transactions.
In some cases, high memory consumption is caused by wait situations, which can have dierent reasons:
● Long-running or unclosed cursors,
● Blocked transactions,
● Hanging threads.
As one of the negative impacts, used memory is not released any more. In particular, the number of table
versions can grow up to more than 8,000,000 which is considered the amount where an action is required.
For more information, see Transactional Problems.
Related Information
Transactional Problems [page 33]
3.1.5.8 Used Space Much Smaller than Allocated Space
In order to optimize performance by minimizing the memory management overhead or due to fragmentation,
SAP HANA may allocate additional memory rather than reusing free space within the already allocated
memory.
This can lead to undesired eects that the SAP HANA memory footprint increases without apparent need.
The SAP HANA license checks against allocated space, so from a licensing perspective it is important to keep
the allocated space below the license limit.
In order to limit the amount of allocated space, you can set the parameter global_allocation_limit to a
value not larger than the maximum memory that should be allocated.
See Set the global_allocation_limit Parameter in the SAP HANA Administration Guide.
Related Information
Change the Global Memory Allocation Limit
3.1.5.9 Fragmentation
Fragmentation eects are responsible for ineciently used memory. They can occur in dierent areas.
In order to minimize fragmentation of row store tables you can proceed as follows:
SAP HANA Troubleshooting and Performance Analysis Guide
Root Causes and Solutions
P U B L I C 33

● If the fragmentation of row store tables in the shared memory segments of indexserver processes reaches
30% and the allocated memory size is greater than 10GB, a table redistribution operation is needed.
SAP Note 1813245 - SAP HANA DB: Row Store reorganization describes how to determine fragmentation and
perform a table redistribution.
Related Information
SAP Note 1813245
3.1.5.10 Large Memory LOBs
LOB (Large Object) columns can be responsible for signicant memory allocation in the row store and column
store if they are dened as memory LOBs.
To check for memory LOBs and switch to hybrid LOBs see SAP Note 1994962 – Activation of Hybrid LOBs in
SAP HANA.
Related Information
SAP Note 1994962
3.1.5.11 Large Delta Store
The delta store can allocate a signicant portion of the column store memory.
You can identify the current size of the delta store by running the SQL command:
HANA_Tables_ColumnStore_Overview (SAP Note 1969700 – SQL Statement Collection for SAP HANA). If
the delta store size is larger than expected, proceed as described in the section
Delta Merge.
Related Information
SAP Note 1969700
Delta Merge [page 68]
34
P U B L I C
SAP HANA Troubleshooting and Performance Analysis Guide
Root Causes and Solutions
3.1.5.12 Undersized SAP HANA Memory
If a detailed analysis of the SAP HANA memory consumption didn’t reveal any root cause of increased memory
requirements, it is possible that the available memory is not sucient for the current utilization of the SAP
HANA database.
In this case you should perform a sizing verication and make sure that sucient memory is installed on the
SAP HANA hosts.
3.1.5.13 Setting a Memory Limit for SQL Statements
You can set a statement memory limit to prevent single statements from consuming too much memory.
Prerequisites
To apply these settings you must have the system privilege INIFILE ADMIN.
For these options, enable_tracking and memory_tracking must rst be enabled in the global.ini le.
Additionally, resource_tracking must be enabled in this le if you wish to apply dierent settings for
individual users (see Procedure below).
Context
You can protect an SAP HANA system from uncontrolled queries consuming excessive memory by limiting the
amount of memory used by single statement executions per host. By default, there is no limit set on statement
memory usage, but if a limit is applied, statement executions that require more memory will be aborted when
they reach the limit. To avoid canceling statements unnecessarily you can also apply a percentage threshold
value which considers the current statement allocation as a proportion of the global memory currently
available. Using this parameter, statements which have exceeded the hard-coded limit may still be executed if
the memory allocated for the statement is within the percentage threshold. The percentage threshold setting is
also eective for workload classes where a statement memory limit can also be dened.
You can also create exceptions to these limits for individual users (for example, to ensure an administrator is
not prevented from doing a backup) by setting a dierent statement memory limit for each individual.
These limits only apply to single SQL statements, not the system as a whole. Tables which require much more
memory than the limit applied here may be loaded into memory. The parameter global_allocation_limit
limits the maximum memory allocation limit for the system as a whole.
You can view the (peak) memory consumption of a statement in
M_EXPENSIVE_STATEMENTS.MEMORY_SIZE.
SAP HANA Troubleshooting and Performance Analysis Guide
Root Causes and Solutions
P U B L I C 35
Procedure
1. Enable statement memory tracking.
In the global.ini le, expand the resource_tracking section and set the following parameters to on:
○ enable_tracking = on
○ memory_tracking = on
2. statement_memory_limit - denes the maximum memory allocation per statement in GB. The default
value is 0 (no limit).
○ In the global.ini le, expand the memorymanager section and locate the parameter. Set an integer
value in GB between 0 (no limit) and the value of the global allocation limit. Values that are too small
can block the system from performing critical tasks.
○ When the statement memory limit is reached, a dump le is created with 'compositelimit_oom' in the
name. The statement is aborted, but otherwise the system is not aected. By default only one dump
le is written every 24 hours. If a second limit hits in that interval, no dump le is written. The interval
can be congured in the memorymanager section of the global.ini le using the
oom_dump_time_delta parameter, which sets the minimum time dierence (in seconds) between
two dumps of the same kind (and the same process).
○ The value dened for this parameter can be overridden by the corresponding workload class property
STATEMENT_MEMORY_LIMIT.
After setting this parameter, statements that exceed the limit you have set on a host are stopped by
running out of memory.
3. statement_memory_limit_threshold - denes the maximum memory allocation per statement as a
percentage of the global allocation limit. The default value is 0% (the statement_memory_limit is always
respected).
○ In the global.ini le, expand the memorymanager section and set the parameter as a percentage of
the global allocation limit.
○ This parameter provides a means of controlling when the statement_memory_limit is applied. If
this parameter is set, when a statement is issued the system will determine if the amount of memory it
consumes exceeds the dened percentage value of the overall global_allocation_limit
parameter setting. The statement memory limit is only applied if the current SAP HANA memory
consumption exceeds this statement memory limit threshold as a percentage of the global allocation
limit.
○ This is a way of determining if a particular statement consumes an inordinate amount of memory
compared to the overall system memory available. If so, to preserve memory for other tasks, the
statement memory limit is applied and the statement fails with an exception.
○ Note that the value dened for this parameter also applies to the workload class property
STATEMENT_MEMORY_LIMIT.
4. total_statement_memory_limit - a value in gigabytes to dene the maximum memory available to all
statements running on the system. The default value is 0 (no limit).
○ This limit does not apply to users with the administrator role SESSION ADMIN or WORKLOAD ADMIN
who need unrestricted access to the system. However, a check of the user's privileges allowing the
administrator to by-pass the limit is only made for the rst request when a connection is made. The
privileged user would have to reconnect to be able to bypass the statement memory limit again (see
also Admission Control).
○ The value dened for this parameter cannot be overridden by the corresponding workload class
property TOTAL_STATEMENT_MEMORY_LIMIT.
36
P U B L I C
SAP HANA Troubleshooting and Performance Analysis Guide
Root Causes and Solutions

○ There is a corresponding parameter for use with system replication on an Active/Active (read enabled)
secondary server. This is required to ensure that enough memory is always available for essential log
shipping activity. See also sr_total_statement_memory_limit in section Memory Management.
5. User parameters can limit memory for statements. For further information, refer to Setting User
Parameters for Workload.
Results
The following example and scenarios show the eect of applying these settings:
Example showing statement memory parameters
Parameter
Value
Physical memory 128 GB
global_allocation_limit
The unit used by this parameter is MB. The default value is: 90% of the
rst 64 GB of available physical memory on the host plus 97% of each
further GB; or, in the case of small physical memory, physical memory
minus 1 GB.
statement_memory_limit
1 GB (the unit used by this parameter is GB.)
statement_memory_limit_threshold
60%
Scenario 1:
A statement allocates 2GB of memory and the current used memory size in SAP HANA is 50GB.
● 0,9 * 128GB = 115,2 (global allocation limit)
● 0,6 * 115,2 = 69,12 (threshold in GB)
● 50 GB < 69,12 GB (threshold not reached)
The statement is executed, even though it exceeds the 1GB statement_memory_limit.
Scenario 2:
A statement allocates 2GB and the current used memory size in SAP HANA is 70GB
● 70 GB > 69,12 GB (threshold is exceeded)
The statement is cancelled, as the threshold is exceeded, the statement_memory_limit is applied.
Related Information
Change the Global Memory Allocation Limit
Memory Management
Setting User Parameters for Workload
Managing Peak Load (Admission Control)
SAP HANA Troubleshooting and Performance Analysis Guide
Root Causes and Solutions
P U B L I C 37

3.1.6 Transparent Huge Pages on Linux
The use of transparent huge pages on Linux can cause the SAP HANA database to appear to hang and they
should be disabled.
Symptoms where the HANA database doesn't respond to requests, or where it is not possible to connect to the
database may be caused by transparent huge pages (THP). Alert 116 will indicate with a warning if transparent
huge pages are enabled.
The use of THP is a Linux kernel level issue and they can be disabled on the HANA system. You can run the
following command to check the kernel settings and verify if these pages are enabled:
cat /sys/kernel/mm/transparent_hugepage/enabled
This returns a string showing which state is currently applied as shown in this example (the bracketed value is
current):
[always] madvise never
The madvise value will enable hugepages only inside MADV_HUGPAGE madvise regions. Enter the following
command, which can be executed at runtime, to set this parameter to never:
echo never > /sys/kernel/mm/transparent_hugepage/enabled
This setting is then valid until the next system start; you can also integrate this command within your system
boot scripts to ensure that it is always applied.
Alternatively, you can run the system procedure CHECK_PLATFORM on SYSTEMDB which returns the current
status value:
CALL CHECK_PLATFORM("CHECK_THP")
SAP Note 2031375 provides further information: SAP HANA: Transparent HugePages (THP) setting on Linux.
See also SAP HANA DB: Recommended OS Settings for SLES 11 in SAP Notes 1824819 and 1954788.
Related Information
SAP Note 2031375
SAP Note 1824819
SAP Note 1954788
38
P U B L I C
SAP HANA Troubleshooting and Performance Analysis Guide
Root Causes and Solutions
3.2 CPU Related Root Causes and Solutions
This section covers the troubleshooting of high CPU consumption on the system.
A constantly high CPU consumption will lead to a considerably slower system as no more requests can be
processed. From an end user perspective, the application behaves slowly, is unresponsive or can even seem to
hang.
Note that a proper CPU utilization is actually desired behavior for SAP HANA, so this should be nothing to
worry about unless the CPU becomes the bottleneck. SAP HANA is optimized to consume all memory and CPU
available. More concretely, the software will parallelize queries as much as possible in order to provide optimal
performance. So if the CPU usage is near 100% for a query execution, it does not always mean there is an
issue. It also does not automatically indicate a performance issue.
3.2.1 Indicators of CPU Related Issues
CPU related issues are indicated by alerts issued or in views in the SAP HANA cockpit.
The following alerts may indicate CPU resource problems:
● Host CPU Usage (Alert 5)
● Most recent savepoint operation (Alert 28)
● Savepoint duration (Alert 54)
You notice very high CPU consumption on your SAP HANA database from one of the following:
● Alert 5 (Host CPU Usage) is raised for current or past CPU usage
● The CPU usage displayed in the CPU Usage tile on the Overview screen
● The Performance Monitor shows high current or past CPU consumption. Furthermore, the CPU usage of
the host as well as the individual servers is displayed.
3.2.2 Analysis of CPU Related Issues
The following section describes how to analyze high CPU consumption using tools in the SAP HANA cockpit.
When analyzing high CPU consumption, you need to distinguish between the CPU resources consumed by
HANA itself and by other, non-SAP HANA processes on the host. While the CPU consumption of SAP HANA will
be addressed here in detail, the CPU consumption of other processes running on the same host is not covered.
Such situations are often caused by additional programs running concurrently on the SAP HANA appliance
such as anti-virus and backup software. For more information see SAP Note 1730928.
A good starting point for the analysis is the Overview page in the SAP HANA cockpit. It contains a tile that
displays CPU usage. If you click on that tile, the Performance Monitor opens and you can view the SAP HANA
CPU usage versus total CPU usage. If SAP HANA CPU usage is low while total CPU usage is high, the issue is
most likely related to a non-SAP HANA process.
SAP HANA Troubleshooting and Performance Analysis Guide
Root Causes and Solutions
P U B L I C 39

To nd out what is happening in more detail, open the Threads tile (see Thread Monitoring). In order to prepare
it for CPU time analysis, perform the following steps:
● To switch on resource tracking open the Conguration of System Properties monitor and in the
resource_tracking section of the global.ini le set the following parameters to on. See Memory
Information from Logs and Traces.
○ cpu_time_measurement_mode
○ enable_tracking
● Display the CPU Time column in the Thread Monitor.
The Thread Monitor shows the CPU time of each thread running in SAP HANA in microseconds. A high CPU
time of related threads is an indicator that an operation is causing the increased CPU consumption.
In order to identify expensive statements causing high resource consumption, turn on the Expensive Statement
Trace and specify a reasonable runtime (see Expensive Statements Trace). If possible, add further restrictive
criteria such as database user or application user to narrow down the amount of information traced. Note that
the CPU time for each statement is shown in the column CPU_TIME if resource_tracking is activated.
Another tool to analyze high CPU consumption is the Kernel Proler. More information about this tool can be
found in Kernel Proler. Note that setting a maximum duration or memory limit for proling is good practice
and should be used if appropriate values can be estimated.
To capture the current state of the system for later analysis you can use Full System Info Dump. However,
taking a Full System Info Dump requires resources itself and may therefore worsen the situation. To get a Full
System Info Dump, open Diagnosis Files via the link Manage full system information dumps under Alerting &
Diagnostics and choose either a zip le from the list or create a new one via Collect Diagnostics.
Tip
Guided Answers is a support tool for troubleshooting problems using decision trees. A guided answer is
available for How to troubleshoot HANA High CPU Utilization.
Related Information
SAP Note 1730928
Thread Monitoring [page 174]
Memory Information from Logs and Traces [page 23]
Expensive Statements Trace [page 186]
Kernel Proler [page 233]
Collect and Download Diagnosis Information with the Cockpit
How to troubleshoot HANA High CPU Utilization (Guided Answer)
40
P U B L I C
SAP HANA Troubleshooting and Performance Analysis Guide
Root Causes and Solutions
3.2.3 Resolving CPU Related Issues
The rst priority in resolving CPU related issues is to return the system to a normal operating state, which may
complicate identifying the root cause.
Issue resolution should aim to bring the system back to a sane state by stopping the operation that causes the
high CPU consumption. However, after resolving the situation it might not be possible to nd out the actual
root cause. Therefore please consider recording the state of the system under high load for later analysis by
collecting a Full System Info Dump (see Analysis of CPU Related Issues).
Actually stopping the operation causing the high CPU consumption can be done via the Threads monitor (see
Thread Monitoring). With the columns Client Host, Client IP, Client PID and Application User it is possible to
identify the user that triggered the operation. In order to resolve the situation contact him and clarify the
actions he is currently performing.
As soon as this is claried and you agree on resolving the situation, two options are available:
● On the client side, end the process calling the aected threads
● Cancel the operation that is related to the aected threads. To do so, click on the thread in the Threads
monitor and choose Cancel Operations.
For further analysis on the root cause, please open a ticket to SAP HANA Development Support and attach the
Full System Info Dump, if available.
Related Information
Analysis of CPU Related Issues [page 39]
Thread Monitoring [page 174]
3.2.4 Retrospective Analysis of CPU Related Issues
There are a number of options available to analyze what the root cause of an issue was after it has been
resolved.
A retrospective analysis of high CPU consumption should start by checking the Performance Monitor and the
Alerts tile. Using the alert time or the graph in the Performance Monitor, determine the time frame of the high
CPU consumption. If you are not able to determine the time frame because the issue happened too long ago,
check the following statistics server table which includes historical host resource information up to 30 days:
HOST_RESOURCE_UTILIZATION_STATISTICS (_SYS_STATISTICS schema)
With this information, search through the trace les of the responsible process. Be careful to choose the
correct host when SAP HANA runs on a scale-out landscape. The information contained in the trace les will
give indications on the threads or queries that were running during the aected time frame.
If the phenomenon is recurrent due to a scheduled batch job or data loading processes, turn on the Expensive
Statement Trace during that time to record all involved statements (see Expensive Statements Trace ).
Furthermore, check for concurrently running background jobs like backups and Delta Merge that may cause a
SAP HANA Troubleshooting and Performance Analysis Guide
Root Causes and Solutions
P U B L I C 41

resource shortage when run in parallel. Historical information about such background jobs can be obtained
from the system views:
● M_BACKUP_CATALOG
● M_DELTA_MERGE_STATISTICS
● A longer history can be found in the statistics server table HOST_DELTA_MERGE_STATISTICS
(_SYS_STATISTICS schema).
Related Information
Expensive Statements Trace [page 186]
M_BACKUP_CATALOG
M_DELTA_MERGE_STATISTICS
HOST_DELTA_MERGE_STATISTICS
3.2.5 Controlling Parallel Execution of SQL Statements
You can apply ini le settings to control the two thread pools SqlExecutor and JobExecutor that control the
parallelism of statement execution.
Caution
The settings described here should only be modied when other tuning techniques like remodeling,
repartitioning, and query tuning have been applied. Modifying the parallelism settings requires a thorough
understanding of the actual workload since they have impact on the overall system behavior. Modify the
settings iteratively by testing each adjustment. For more information, see Understand your Workload.
On systems with highly concurrent workload, too much parallelism of single statements may lead to sub-
optimal performance. Note also that partitioning tables inuences the degree of parallelism for statement
execution; in general, adding partitions tends to increase parallelism. You can use the parameters described in
this section to adjust the CPU utilization in the system.
Two thread pools control the parallelism of the statement execution. Generally, target thread numbers applied
to these pools are soft limits, meaning that additional available threads can be used if necessary and deleted
when no longer required:
● SqlExecutor
This thread pool handles incoming client requests and executes simple statements. For each statement
execution, an SqlExecutor thread from a thread pool processes the statement. For simple OLTP-like
statements against column store as well as for most statements against row store, this will be the only type
of thread involved. With OLTP we mean short running statements that consume relatively little resources,
however, even OLTP-systems like SAP Business Suite may generate complex statements.
● JobExecutor
The JobExecutor is a job dispatching subsystem. Almost all remaining parallel tasks are dispatched to the
JobExecutor and its associated JobWorker threads.
In addition to OLAP workload the JobExecutor also executes operations like table updates, backups,
memory garbage collection, and savepoint writes.
42
P U B L I C
SAP HANA Troubleshooting and Performance Analysis Guide
Root Causes and Solutions

You can set a limit for both SqlExecutor and JobExecutor to dene the maximum number of threads. You can
use this for example on a system where OLAP workload would normally consume too many CPU resources to
apply a maximum value to the JobExecutor to reserve resources for OLTP workload.
Caution
Lowering the value of these parameters can have a drastic eect on the parallel processing of the servers
and reduce the performance of the overall system. Adapt with caution by iteratively making modications
and testing. For more information, see Understand your Workload and SAP Note 2222250 - FAQ SAP HANA
Workload Management which contains more details of the workload conguration parameters.
A further option to manage statement execution is to apply a limit to an individual user prole for all
statements in the current connection using ‘THREADLIMIT’ parameter. This option is described in Setting User
Parameters.
Parameters for SqlExecutor
The following SqlExecutor parameters are in the sql section of the indexserver.ini le.
sql_executors - sets a soft limit on the target number of logical cores for the SqlExecutor pool.
● This parameter sets the target number of threads that are immediately available to accept incoming
requests. Additional threads will be created if needed and deleted if not needed any more.
● The parameter is initially not set (0); the default value is the number of logical cores in a system. As each
thread allocates a particular amount of main memory for the stack, reducing the value of this parameter
can help to avoid memory footprint.
max_sql_executors - sets a hard limit on the maximum number of logical cores that can be used.
● In normal operation new threads are created to handle incoming requests. If a limit is applied here, SAP
HANA will reject new incoming requests with an error message if the limit is exceeded.
● The parameter is initially not set (0) so no limit is applied.
Caution
SAP HANA will not accept new incoming requests if the limit is exceeded. Use this parameter with extreme
care.
Parameters for JobExecutor
The following JobExecutor parameters are in the execution section of the global.ini or
indexserver.ini.
max_concurrency - sets the target number of logical cores for the JobExecutor pool.
● This parameter sets the size of the thread pool used by the JobExecutor used to parallelize execution of
database operations. Additional threads will be created if needed and deleted if not needed any more. You
can use this to limit resources available for JobExecutor threads, thereby saving capacity for SqlExecutors.
SAP HANA Troubleshooting and Performance Analysis Guide
Root Causes and Solutions
P U B L I C 43

● The parameter is initially not set (0); the default value is the number of logical cores in a system. Especially
on systems with at least 8 sockets consider setting this parameter to a reasonable value between the
number of logical cores per CPU up to the overall number of logical cores in the system. In a system that
supports tenant databases, a reasonable value is the number of cores divided by the number of tenant
databases.
max_concurrency_hint - limits the number of logical cores for job workers even if more active job workers
would be available.
● This parameter denes the number of jobs to create for an individual parallelized operation. The
JobExecutor proposes the number of jobs to create for parallel processing based on the recent load on the
system. Multiple parallelization steps may result in far more jobs being created for a statement (and hence
higher concurrency) than this parameter.
● The default is 0 (no limit is applied but the hint value is never greater than the value for
max_concurrency). On large systems (that is more than 4 sockets) setting this parameter to the number
of logical cores of one socket may result in better performance but testing is necessary to conrm this.
default_statement_concurrency_limit - restricts the actual degree of parallel execution per connection
within a statement.
● This parameter controls the maximum overall parallelism for a single database request. Set this to a
reasonable value (a number of logical cores) between 1 and max_concurrency but greater or equal to the
value set for max_concurrency_hint.
● The default setting is 0; no limit is applied.
Related Information
Understand your Workload
Example Workload Management Scenarios
SAP Note 2222250
Setting User Parameters for Workload
3.2.6 Controlling CPU Consumption
If the physical hardware on a host is shared between several processes you can use CPU anity settings to
assign a set of logical cores to a specic SAP HANA process. These settings are coarse-grained and apply on
the OS and process-level.
Prerequisites
You can use the affinity conguration parameter to restrict CPU usage of SAP HANA server processes to
certain CPUs or ranges of CPUs.
Using the conguration option, we rstly analyze how the system CPUs are congured and then, based on the
information returned, apply anity settings in daemon.ini to bind specic processes to logical CPU cores.
44
P U B L I C
SAP HANA Troubleshooting and Performance Analysis Guide
Root Causes and Solutions

Processes must be restarted before the changes become eective. This approach applies primarily to the use
cases of SAP HANA tenant databases and multiple SAP HANA instances on one server; you can use this, for
example, to partition the CPU resources of the system by tenant database.
Tip
As an alternative to applying CPU anity settings you can achieve similar performance gains by changing
the parameter [execution] max_concurrency in the global.ini conguration le. This may be more
convenient and does not require the system to be oine.
To make the changes described here you require access to the operating system of the SAP HANA instance to
run the Linux lscpu command and you require the privilege INIFILE ADMIN.
Information about the SAP HANA system topology is also available from SAP HANA monitoring views as
described in a following subsection SAP HANA Monitoring Views for CPU Topology Details. Use of the NUMA
NODE clause for SQL statements is described in the following topic. Further information can also be found in
KBA 2470289: FAQ: SAP HANA Non-Uniform Memory Access (NUMA).
Context
For Xen and VMware, the users in the VM guest system see what is congured in the VM host. So the quality of
the reported information depends on the conguration of the VM guest. Therefore SAP cannot give any
performance guarantees in this case.
Procedure
1. Firstly, to conrm the physical and logical details of your CPU architecture, analyze the system using the
lscpu command. This command returns a listing of details of the system architecture. The table which
follows gives a commentary on the most useful values based on an example system with 2 physical chips
(sockets) each containing 8 physical cores. These are hyperthreaded to give a total of 32 logical cores.
#
Feature Example Value
1 Architecture x86_64
2 CPU op-mode(s) 32-bit, 64-bit
3 Byte Order LittleEndian
4 CPUs 32
5 On-line CPU(s) list 0-31
6 Thread(s) per core 2
7 Core(s) per socket 8
SAP HANA Troubleshooting and Performance Analysis Guide
Root Causes and Solutions
P U B L I C 45

# Feature Example Value
8 Socket(s) 2
9 NUMA node(s) 2
21 NUMA node0 CPU(s) 0-7,16-23
22 NUMA node1 CPU(s) 8-15,24-31
○ 4-5: This example server has 32 logical cores numbered 0 - 31
○ 6-8: Logical cores ("threads") are assigned to physical cores. Where multiple threads are assigned to a
single physical core this is referred to as 'hyperthreading'. In this example, there are 2 sockets, each
socket contains 8 physical cores (total 16). Two logical cores are assigned to each physical core, thus,
each core exposes two execution contexts for the independent and concurrent execution of two
threads.
○ 9: In this example there are 2 NUMA (Non-uniform memory access) nodes, one for each socket. Other
systems may have multiple NUMA nodes per socket.
○ 21-22: The 32 logical cores are numbered and specically assigned to one of the two NUMA nodes.
Note
Even on a system with 32 logical cores and two sockets the assignment of logical cores to physical
CPUs and sockets can be dierent. It is important to collect the assignment in advance before making
changes. A more detailed analysis is possible using the system commands described in the next step.
These provide detailed information for each core including how CPU cores are grouped as siblings.
2. In addition to the lscpu command you can use the set of system commands in the /sys/devices/
system/cpu/ directory tree. For each logical core there is a numbered subdirectory beneath this node (/
cpu12/ in the following examples). The examples show how to retrieve this information and the table gives
details of some of the most useful commands available:
Example
cat /sys/devices/system/cpu/present
cat /sys/devices/system/cpu/cpu12/topology/thread_siblings_list
Command
Example Output Commentary
present 0-15 The number of logical cores available for scheduling.
cpu12/topology/core_siblings_list 4-7, 12-15 The cores on the same socket.
cpu12/topology/thread_siblings_list 4, 12 The logical cores assigned to the same physical core
(hyperthreading).
cpu12/topology/physical_package_id 1 The socket of the current core - in this case cpu12.
Other Linux commands which are relevant here are sched_setaffinity and numactl.
sched_setaffinity limits the set of CPU cores available (by applying a CPU anity mask) for execution
46
P U B L I C
SAP HANA Troubleshooting and Performance Analysis Guide
Root Causes and Solutions

of a specic process (this could be used, for example, to isolate tenants) and numactl controls NUMA
policy for processes or shared memory.
3. Based on the results returned you can use the affinity setting to restrict CPU usage of SAP HANA
server processes to certain CPUs or ranges of CPUs. You can do this for the following servers: nameserver,
indexserver, compileserver, preprocessor, and xsengine (each server has a section in the daemon.ini le).
The anity setting is applied by the TrexDaemon when it starts the other HANA processes using the
command
sched_setaffinity. Changes to the anity settings take eect only after restarting the
HANA process. The examples and commentary below show the syntax for the ALTER SYSTEM
CONFIGURATION commands required.
Example
To restrict the nameserver to two logical cores of the rst CPU of socket 0 (see line 21 in the example
above), use the following anity setting:
ALTER SYSTEM ALTER CONFIGURATION ('daemon.ini', 'SYSTEM') SET
('nameserver', 'affinity') = '0,16'
Example
To restrict the preprocessor and the compileserver to all remaining cores (that is, all except 0 and 16)
on socket 0 (see line 21 in the example above), use the following anity settings:
ALTER SYSTEM ALTER CONFIGURATION ('daemon.ini', 'SYSTEM') SET
('preprocessor', 'affinity') = '1-7,17-23'
ALTER SYSTEM ALTER CONFIGURATION ('daemon.ini', 'SYSTEM') SET
('compileserver', 'affinity') = '1-7,17-23'
Example
To restrict the indexserver to all cores on socket 1 (see line 22 in the example above), use the following
anity settings:
ALTER SYSTEM ALTER CONFIGURATION ('daemon.ini', 'SYSTEM') SET
('indexserver', 'affinity') = '8-15,24-31'
4. You can assign anities to dierent tenants of a multi-tenant database on the same host as shown here.
Run these SQL statements on the SYSTEMDB.
Example
In this scenario tenant NM1 already exists, here we add another tenant NM2:
CREATE DATABASE NM2 ADD AT LOCATION 'host:30040' SYSTEM USER PASSWORD
Manager1;
Set the conguration parameter to bind CPUs to specic NUMA nodes on each tenant can use the
following notation with a dot to identify the specic tenant:
ALTER SYSTEM ALTER CONFIGURATION ('daemon.ini','SYSTEM') SET
('indexserver.NM1', 'affinity') ='0-7,16-23';
ALTER SYSTEM ALTER CONFIGURATION ('daemon.ini','SYSTEM') SET
('indexserver.NM2', 'affinity') ='8-15,24-31';
SAP HANA Troubleshooting and Performance Analysis Guide
Root Causes and Solutions
P U B L I C 47

5. To assign anities to multiple indexservers of the same tenant on the same host execute the following SQL
statements on the SYSTEMDB to apply the instance_affinity[port] conguration parameter:
Example
In this scenario an indexserver is already running on tenant NM1 on port 30003, here we add another
indexserver on a dierent port:
ALTER DATABASE NM1 ADD 'indexserver' AT LOCATION 'host:30040';
Set the dierent instances of the instance_affinity[port] conguration parameter to bind CPUs
to specic NUMA nodes on each indexserver. The conguration parameter has a 1-2 digit sux to
identify the nal signicant digits of the port number, in this example 30003 and 30040:
ALTER SYSTEM ALTER CONFIGURATION ('daemon.ini','SYSTEM') SET
('indexserver.NM1', 'instance_affinity[3]')='0-7,16-23';
ALTER SYSTEM ALTER CONFIGURATION ('daemon.ini','SYSTEM') SET
('indexserver.NM1', 'instance_affinity[40]')='8-15,24-31';
Restart the indexserver processes to make the anity settings eective.
6. You can test the settings either in SQL or using hdbcons as shown here:
Run this query on the tenant or SystemDB:
select * from M_NUMA_NODES;
Using hdbcons the process ID of the indexserver process is required as a parameter:
hdbcons -p <PID> "jexec info"
Related Information
Conguring Memory and CPU Usage for Tenant Databases
SAP HANA Monitoring Views for CPU Topology Details
SQL Statements to Apply NUMA Location Preferences
SAP Note 2470289
3.3 Disk Related Root Causes and Solutions
This section discusses issues related to hard disks and lack of free space.
48
P U B L I C
SAP HANA Troubleshooting and Performance Analysis Guide
Root Causes and Solutions

Low Disk Space
This problem is usually reported by alert 2 which is triggered whenever one of the disk volumes used for data,
log, backup or trace les reaches a critical size.
Use the following tools in the SAP HANA cockpit to examine the situation and try to free some disk space:
● Via Alerts tile
● Via Disk Usage tile
● On the Disk Volume Monitor
For high log volume utilizations, refer to SAP KBA 2083715 - Analyzing log volume full situations. For data
volume exhaustions which cannot be explained by the size of the catalog objects (tables etc.) there are a few
more mechanisms which utilize the persistency layer (data volume) such as:
● Disk LOBs
● Table Sizes on Disk
● MVCC Mechanism
● Database Snapshots
The following sections will assist you in analyzing these possible problem areas step by step.
Disk LOBs
Large binary objects are usually not optimally compressible in SAP HANA, thus tables with large LOB les may
also indicate large memory footprints in SAP HANA. Since SAP HANA also oers the concept of hybrid LOBs
(as of SAP HANA SPS07), the majority of the LOB data – larger than a specic threshold - is automatically
outsourced to the physical persistence on disk instead. This can lead to the situation that you have a table
which is small in memory but large on disk level. The SQL statement HANA_Tables_DiskSize_1.00.120+, which
you can nd in the SAP Note 1969700 - SQL Statement Collection for SAP HANA, may provide further insights
on the disk and memory footprint of the largest tables with LOB columns. In the following example, you see
tables which utilize large amounts of disk space but eectively no memory due to the nature of the data itself
(LOBs):
For further information on handling LOBs, refer to:
● SAP Note 2220627 - FAQ: SAP HANA LOBs
● SAP Note 1994962 - How-To: Activation of Hybrid LOBs in SAP HANA
If you cannot narrow down the issue to LOBs, check the virtual le containers on persistency level in more
detail.
SAP HANA Troubleshooting and Performance Analysis Guide
Root Causes and Solutions
P U B L I C 49

Table Sizes on Disk
A rst insight on whether the virtual le containers of the column store tables are responsible for the data
volume utilization can be gained by running the following statement:
SELECT host, port, sum(physical_size) FROM M_TABLE_VIRTUAL_FILES GROUP BY port,
host
This will return the sum of the physical size of all virtual le containers on disk level, representing the total size
of the catalog objects on disk level. If this deviates drastically from the data volume utilization you observe,
there are objects utilizing the data volume other than database tables and indices.
If the sum of the virtual le containers does not match the disk utilization observed on OS level for the data
volume, further checks are necessary.
MVCC Mechanism
A blocked garbage collection may also over-utilize the SAP HANA data volume of the indexserver. Proceed as
outlined in:
● Multiversion Concurrency Control (MVCC) Issues
● SAP KBA 2169283 - FAQ: SAP HANA Garbage Collection
Run the following query to make sure there are no excessive amounts of undo cleanup les:
SELECT SUM(page_count) FROM M_UNDO_CLEANUP_FILES
Undo les contain information needed for transaction rollback and these les are removed when the
transaction completes.
Cleanup les contain deleted information which is kept because of MVCC isolation requirements. When the
transaction completes garbage collection uses the cleanup les to nally remove data.
For more information, refer to M_UNDO_CLEANUP_FILES System View in the SAP HANA SQL and System
Views Reference guide.
Database Snapshots
In specic cases, for example, if data backups have failed in the past, database snapshots for these backups
are not cleaned up. This can be evaluated by the following SQL statements:
SELECT page_sizeclass AS "Page Size-class", page_size*used_block_count/
(1024*1024*1024) AS "Disk Utilization in GB" FROM M_DATA_VOLUME_PAGE_STATISTICS
WHERE volume_id = <volume_id>
50
P U B L I C
SAP HANA Troubleshooting and Performance Analysis Guide
Root Causes and Solutions

This statement may show a result like:
This leads to the conclusion that the main contributor to the disk utilization are 16MB pages which are mainly
used for the main fragment of the column store. To conrm this, check whether snapshots exist which have
been created for backups:
SELECT * FROM M_SNAPSHOTS
In this case, "dangling" database snapshots which are no longer required should be dropped. This happens
automatically after a database restart.
Related Information
I/O Related Root Causes and Solutions [page 55]
SAP Note 1900643
SAP Note 2083715
SAP Note 1969700
SAP Note 2220627
SAP Note 1994962
Multiversion Concurrency Control (MVCC) Issues [page 116]
SAP Note 2169283
M_UNDO_CLEANUP_FILES System View
SAP HANA Troubleshooting and Performance Analysis Guide
Root Causes and Solutions
P U B L I C 51

3.3.1 Reclaiming Disk Space
Defragmentation can be carried out as a routine housekeeping operation or to recover disk space in response
to a disk full event.
General Information
Reclaiming disk space is necessary because the size allocated to a data le is automatically increased as more
space is required, but it is not automatically decreased when less space is required. This may create a
dierence between allocated size and used size.
For more information on data and log volumes refer to:
● Persistent Data Storage in the SAP HANA Database in the SAP HANA Administration Guide.
● SAP Note 1870858 - HANA Alerts related to le system utilization.
For routine monitoring of disk usage the following scripts from SAP Note 1969700 – SQL Statement Collection
for SAP HANA
may be helpful:
● HANA_Disks_Overview
● HANA_Disks_SuperblockStatistics
● HANA_Tables_ColumnStore_TableSize
● HANA_Tables_TopGrowingTables_Size_History
Reclaiming Disk Space
The RECLAIM DATAVOLUME statement is described in detail in the SAP HANA SQL and System Views
Reference. The following example illustrates the usage:
alter system reclaim datavolume 'myhost:30003' 120 defragment
The example shows a reasonable payload percentage of 120, that is, an overhead of 20% fragmentation is
acceptable. Smaller payload percentage values can signicantly increase the defragmentation runtime.
The following example lines from the SuperblockStatistics report show a comparison of disk usage before and
after defragmentation:
-------------------------------------------------------------------------------
|HOST |PORT |SB_SIZE_MB|USED_SB_COUNT|TOT_SB_COUNT|USED_GB|ALLOC_GB|FRAG_PCT|
|saphana1|30003| 64.00| 8945| 11514| 559| 720| 28.71|
-------------------------------------------------------------------------------
After defragmentation the values for used and allocated disk size are much closer together, the total block
count is reduced and the fragmentation percentage is much lower:
-------------------------------------------------------------------------------
|HOST |PORT |SB_SIZE_MB|USED_SB_COUNT|TOT_SB_COUNT|USED_GB|ALLOC_GB|FRAG_PCT|
|saphana1|30003| 64.00| 8146| 8604| 509| 538| 5.62|
-------------------------------------------------------------------------------
52
P U B L I C
SAP HANA Troubleshooting and Performance Analysis Guide
Root Causes and Solutions

Monitoring the Reclaim Process
No monitoring tool is available to check the progress of the RECLAIM command. The following options may be
helpful:
1. Check for savepoint activity to verify that the RECLAIM process is running. This will conrm that
savepoints are consistently being written:
select * from m_savepoints
2. Enable the indexserver trace to get information about the operation and estimate the job progress:
set trace "pageaccess = info"
Reasons Why Reclaim May Fail
In some situations where snapshots are being created RECLAIM may fail:
1. In a high availability scenario RECLAIM may not work because data snapshots which are part of the
replication process may conict with the RECLAIM datavolume command. SAP Note 2332284 - Data
volume reclaim failed because of snapshot pages gives details of how to temporarily stop the creation of
snapshots to avoid this problem.
2. Snapshots related to backups may also prevent RECLAIM from working. SAP Note 2592369 - HANA
DataVolume Full describes steps to investigate the age of snapshots by querying the M_SNAPSHOTS view
and, if necessary, to manually delete snapshots using the hdbcons command. It may then be possible to
rerun the RECLAIM process.
Related Information
SAP Note 1870858
SAP Note 2332284
SAP Note 2592369
3.3.2 Analyze and Resolve Internal Disk-Full Event (Alert 30)
When it is no longer possible to write to one of the disk volumes used for data, log, backup or trace les, the
database is suspended, an internal event is triggered, and alert 30 is generated. A disk-full event must be
resolved before the database can resume.
Context
If the disks on which the database data and log volumes are located run full, space on the volumes must be
freed or additional space added before the database can resume. In the SAP HANA cockpit, potential disk-full
events are displayed in the alerts app.
SAP HANA Troubleshooting and Performance Analysis Guide
Root Causes and Solutions
P U B L I C 53
However, running out of disk space is not the only reason that SAP HANA may be prevented from writing to
disk. Other possible causes, all of which lead to a disk-full event and alert 30, include:
● File system quota is exceeded
● File system runs out of inodes
● File system errors (bugs)
Note
A number of SAP Notes are available to give troubleshooting advice in specic scenarios. For a log volume
full scenario refer rst to the note 1679938 - DiskFullEvent on Log Volume to resolve the issue and bring the
HANA database back online. Then refer to note 2083715 - Analyzing log volume full situations for root cause
analysis to prevent the scenario from happening again. For log volume full in a replication context refer to
LogReplay: Managing the Size of the Log File in this document.
● SAP Note 1898460 - How to Handle Alert 30 ‘Internal disk-full event’.
● SAP Note 1870858 - HANA Alerts related to le system utilization.
● SAP Note 1679938 - DiskFullEvent on Log Volume.
● SAP Note 2083715 - Analyzing log volume full situations.
Procedure
1. Analyze disk space usage using the standard administration tools in SAP HANA cockpit: Alerts, Disk Usage,
Disk Volume Monitor.
2. Optional: Perform the following steps if helpful:
Note
You must execute the commands from the command line on the SAP HANA server.
a. Determine the le system type:
df -T
b. Check for disk space using le system specic commands:
Option
Description
XFS/NFS
df
GPFS
mmfscheckquota
c. Check if the system is running out of inodes (NFS):
df -i
d. Check quota:
Option
Description
XFS/NFS
quota -v
54 P U B L I C
SAP HANA Troubleshooting and Performance Analysis Guide
Root Causes and Solutions

Option Description
GPFS
mmfscheckquota
Next Steps
The most serious system events (including the disk-full event) are logged as internal database events in the
table M_EVENTS (see also Alert 21 which is also triggered when an internal event occurs). They are initially
logged with a status of ‘NEW’ and, once the issue has been resolved (in this case, free up disk space), the event
must be set to ‘HANDLED’ to be able to continue. You can do this by executing the following SQL statements:
● ALTER SYSTEM SET EVENT ACKNOWLEDGED '<host>:<port>' <id>
● ALTER SYSTEM SET EVENT HANDLED '<host>:<port>' <id>
If you cannot track down the root cause of the alert, contact SAP Support.
Related Information
SAP Note 1870858
SAP Note 2083715
SAP Note 1898460
SAP Note 1679938
LogReplay: Managing the Size of the Log File [page 158]
3.4 I/O Related Root Causes and Solutions
This section covers troubleshooting of I/O performance problems. Although SAP HANA is an in-memory
database, I/O still plays a critical role for the performance of the system.
From an end user perspective, an application or the system as a whole runs slowly, is unresponsive or can even
seem to hang if there are issues with I/O performance. In the Disk Volume Monitor available in the Disk Usage
tile in SAP HANA cockpit you can see the attached volumes and which services use which volumes. For details
of the attached volumes, such as les and I/O statistics, select a row.
In certain scenarios data is read from or written to disk, for example during the transaction commit. Most of the
time this is done asynchronously but at certain points in time synchronous I/O is done. Even during
asynchronous I/O it may be that important data structures are locked.
Examples are included in the following table.
SAP HANA Troubleshooting and Performance Analysis Guide
Root Causes and Solutions
P U B L I C 55

Scenario Description
Savepoint A savepoint ensures that all changed persistent data since the last savepoint gets written to
disk. The SAP HANA database triggers savepoints in 5 minutes intervals by default. Data is
automatically saved from memory to the data volume located on disk. Depending on the
type of data the block sizes vary between 4 KB and 16 MB. Savepoints run asynchronously
to SAP HANA update operations. Database update transactions only wait at the critical
phase of the savepoint, which is usually taking some microseconds.
Snapshot
The SAP HANA database snapshots are used by certain operations like backup and system
copy. They are created by triggering a system wide consistent savepoint. The system keeps
the blocks belonging to the snapshot at least until the drop of the snapshot. Detailed infor
mation about snapshots can be found in the
SAP HANA Administration Guide.
Delta Merge
The delta merge itself takes place in memory. Updates on column store tables are stored in
the delta storage. During the delta merge these changes are applied to the main storage,
where they are stored read optimized and compressed. Right after the delta merge, the new
main storage is persisted in the data volume, that is, written to disk. The delta merge does
not block parallel read and update transactions.
Write Transactions
All changes to persistent data are captured in the redo log. SAP HANA asynchronously
writes the redo log with I/O orders of 4 KB to 1 MB size into log segments. Transactions writ
ing a commit into the redo log wait until the buer containing the commit has been written
to the log volume.
Database restart
At database startup the services load their persistence including catalog and row store ta
bles into memory, that is, the persistence is read from the storage. Additionally the redo log
entries written after the last savepoint have to be read from the log volume and replayed in
the data area in memory. When this is nished the database is accessible. The bigger the
row store is, the longer it takes until the system is available for operations again.
Failover (Host Auto-Fail
over)
On the standby host the services are running in idle mode. Upon failover, the data and log
volumes of the failed host are automatically assigned to the standby host, which then has
read and write access to the les of the failed active host. Row as well as column store tables
(the latter on demand) must be loaded into memory. The log entries have to be replayed.
Takeover (System Replica
tion)
The secondary system is already running, that is the services are active but cannot accept
SQL and thus are not usable by the application. Just like in the database restart (see above)
the row store tables need to be loaded into memory from persistent storage. If table preload
is used, then most of the column store tables are already in memory. During takeover the
replicated redo logs that were shipped since the last data transport from primary to secon
dary have to be replayed.
Data Backup
For a data backup the current payload of the data volumes is read and copied to the backup
storage. For writing a data backup it is essential that on the I/O connection there are no col
lisions with other transactional operations running against the database.
Log Backup Log backups store the content of a closed log segment. They are automatically and asyn
chronously created by reading the payload from the log segments and writing them to the
backup area.
Database Recovery The restore of a data backup reads the backup content from the backup device and writes it
to the SAP HANA data volumes. The I/O write orders of the data recovery have a size of 64
MB. Also the redo log can be replayed during a database recovery, that is the log backups
are read from the backup device and the log entries get replayed.
56 P U B L I C
SAP HANA Troubleshooting and Performance Analysis Guide
Root Causes and Solutions

In the following table the I/O operations are listed which are executed by the above-mentioned scenarios,
including the block sizes that are read or written:
I/O pattern Data Volume Log Volume (redo log) Backup Medium
Savepoint,
Snapshot,
Delta merge
WRITE
4 KB – 16 MB asynchronous
bulk writes, up to 64 MB (clus
tered Row Store super blocks)
Write transactions
WRITE
OLTP – mostly 4 KB log write
I/O performance is relevant
OLAP – writes with larger I/O
order sizes
Table load:
DB Restart,
Failover,
Takeover
READ
4 KB – 16 MB blocks, up to 64
MB (clustered Row Store super
blocks)
READ
Data Backup
READ
4 KB – 16 MB blocks, up to 64
MB (clustered Row Store super
blocks) are asynchronously
copied to “[data] backup buf
fer” of 512 MB
WRITE
in up to 64 MB blocks from
“[data] backup buer”
Log Backup
READ
asynchronously copied to
“[data] backup buer” of 128
MB
WRITE
in up to 64 MB blocks from
“[data] backup buer”
Database Recovery
WRITE
4 KB – 16 MB blocks, up to 64
MB (clustered Row Store super
blocks)
READ
Read block sizes from backup
le headers and copy blocks
into “[data] backup buer” of
size 512 MB
READ
Read block sizes from backup
le headers and copy blocks
into “[data] backup buer” of
size 128 MB
SAP HANA Troubleshooting and Performance Analysis Guide
Root Causes and Solutions
P U B L I C 57

3.4.1 Analyzing I/O Throughput and Latency
When analyzing I/O, the focus is on throughput and latency (time taken). A set of system views (with names
beginning M_VOLUME_IO_*) is available to help you analyze throughput and examples are given here to
illustrate how they can be used.
You can use the following example query to read I/O statistics data which will help you to analyze the
throughput of the system (in this example the index server). The result of this query presents a set of columns
including throughput in MB and trigger ratios (the relationship between trigger time and I/O time) for both read
and write operations:
select v.host, v.port, v.service_name, s.type,
round(s.total_read_size / 1024 / 1024, 3) as "Reads in MB",
round(s.total_read_size / case s.total_read_time when 0 then -1 else
s.total_read_time end, 3) as "Read Throughput in MB",
round(s.total_read_time / 1000 / 1000, 3) as "Read Time in Sec",
trigger_read_ratio as "Read Ratio",
round(s.total_write_size / 1024 / 1024, 3) as "Writes in MB",
round(s.total_write_size / case s.total_write_time when 0 then -1 else
s.total_write_time end, 3) as "Write Throughput in MB",
round(s.total_write_time / 1000 / 1000, 3) as "Write Time in Sec" ,
trigger_write_ratio as "Write Ratio"
from "PUBLIC"."M_VOLUME_IO_TOTAL_STATISTICS_RESET" s, PUBLIC.M_VOLUMES v
where s.volume_id = v.volume_id
and type not in ( 'TRACE' )
and v.volume_id in (select volume_id from m_volumes where service_name =
'indexserver')
order by type, service_name, s.volume_id;
Note that some of the system views for I/O can be used with a resettable counter so that you can gather data
for just the most recent period since the counter was set. This example is based on the
M_VOLUME_IO_TOTAL_STATISTICS system view but uses the ‘reset’ version of the view.
You can reset the statistics counter to analyze the I/O throughput for a certain time frame by running the
following reset command:
alter system reset monitoring view M_VOLUME_IO_TOTAL_STATISTICS_RESET;
Multitier and Replication Scenarios
In a system using replication between primary and secondary sites it is possible to analyze throughput of the
secondary remotely by running these queries on the primary site. This method uses the proxy schema of the
secondary system on the primary and can be used in a 2-tier system replication setup as well as for multitier
landscapes.
The proxy schema follows the naming convention _SYS_SR_SITE_<siteName>, where <siteName> is the name
of the secondary site (case-sensitive). In the FROM clause of the example query given above the schema
PUBLIC is used. In a system replication landscape replace this with the proxy schema as shown in the following
example for a secondary with site name 'SiteB':
from "_SYS_SR_SITE_SiteB"."M_VOLUME_IO_TOTAL_STATISTICS_RESET" s,
"_SYS_SR_SITE_SiteB"."M_VOLUMES" v
Trigger Ratios
I/O calls are executed asynchronously, that is, the thread does not wait for the order to return. The trigger-ratio
of asynchronous reads and writes measures the trigger time divided by the I/O time. A ratio close to 0 shows
58
P U B L I C
SAP HANA Troubleshooting and Performance Analysis Guide
Root Causes and Solutions

good performance; it indicates that the thread does not wait at all. A ratio close to 1 means that the thread
waits until the I/O request is completed.
Refer to SAP Note 1930979 and SAP Notes for Alerts 60 and 61 for more information about the signicance of
the trigger ratio values.
Latency
The latency values are important for LOG devices. To analyze the latency, use the following example query
which returns the log write wait time (for data of type LOG) with various buer sizes written by the index server.
The time values returned are the number of microseconds between enqueueing and nishing a request.
select host, port type,
round(max_io_buffer_size / 1024, 3) "Maximum buffer size in KB",
trigger_async_write_count,
avg_trigger_async_write_time as "Avg Trigger Async Write Time in
Microsecond",
max_trigger_async_write_time as "Max Trigger Async Write Time in
Microsecond",
write_count, avg_write_time as "Avg Write Time in Microsecond",
max_write_time as "Max Write Time in Microsecond"
from "PUBLIC"."M_VOLUME_IO_DETAILED_STATISTICS_RESET"
where type = 'LOG'
and volume_id in (select volume_id from m_volumes where service_name =
'indexserver')
and (write_count <> 0 or avg_trigger_async_write_time <> 0);
Related Information
SAP Note 1930979
M_VOLUME_IO_TOTAL_STATISTICS_RESET System View
Reference: Alerts [page 243]
3.4.2 Savepoint Performance
To perform a savepoint write operation, SAP HANA needs to take a global database lock. This period is called
the “critical phase” of a savepoint. While SAP HANA was designed to keep this time period as short as possible,
poor I/O performance can extend it to a length that causes a considerable performance impact.
Savepoints are used to implement backup and disaster recovery in SAP HANA. If the state of SAP HANA has to
be recovered, the database log from the last savepoint will be replayed.
You can analyze the savepoint performance with this SQL statement:
select start_time, volume_id,
round(duration / 1000000) as "Duration in Seconds",
round(critical_phase_duration / 1000000) as "Critical Phase Duration in
Seconds",
round(total_size / 1024 / 1024) as "Size in MB",
round(total_size / duration) as "Appro. MB/sec",
round (flushed_rowstore_size / 1024 / 1024) as "Row Store Part MB"
from m_savepoints
SAP HANA Troubleshooting and Performance Analysis Guide
Root Causes and Solutions
P U B L I C 59

where volume_id in ( select volume_id from m_volumes where service_name =
'indexserver') ;
This statement shows how long the last and the current savepoint writes took/are taking. Especially the critical
phase duration, in which savepoints need to take a global database lock, must be observed carefully.
The critical phase duration should not be longer than a second. In the example below the times are signicantly
higher due to I/O problems.
Savepoints
The following SQL shows a histogram on the critical phase duration:
select
to_char(SERVER_TIMESTAMP,'yyyy.mm.dd') as "time",
sum(case when (critical_phase_duration <= 1000000) then 1 else 0
end) as "<= 1 s",
sum(case when (critical_phase_duration > 1000000 and critical_phase_duration
<=2000000) then 1 else 0
end) as "<= 2 s",
sum(case when (critical_phase_duration > 2000000 and critical_phase_duration
<=3000000) then 1 else 0
end) as "<= 3 s",
sum(case when (critical_phase_duration > 3000000 and critical_phase_duration
<=4000000) then 1 else 0
end) as "<= 4 s",
sum(case when (critical_phase_duration > 4000000 and critical_phase_duration
<=5000000) then 1 else 0
end) as "<= 5 s",
sum(case when (critical_phase_duration > 5000000 and critical_phase_duration
<=10000000) then 1 else 0
end) as "<= 10 s",
sum(case when (critical_phase_duration > 10000000 and critical_phase_duration
<=20000000) then 1 else 0
end) as "<= 20 s",
sum(case when (critical_phase_duration > 20000000 and critical_phase_duration
<=40000000) then 1 else 0
end) as "<= 40 s",
sum(case when (critical_phase_duration > 40000000 and critical_phase_duration
<=60000000) then 1 else 0
end) as "<= 60 s",
sum(case when (critical_phase_duration > 60000000 ) then 1 else 0
end) as "> 60 s",
count(critical_phase_duration) as "ALL"
from "_SYS_STATISTICS"."HOST_SAVEPOINTS"
where volume_id in (select volume_id from m_volumes where service_name =
'indexserver')
and weekday (server_timestamp) not in (5, 6)
group by to_char(SERVER_TIMESTAMP,'yyyy.mm.dd')
order by to_char(SERVER_TIMESTAMP,'yyyy.mm.dd') desc;
60
P U B L I C
SAP HANA Troubleshooting and Performance Analysis Guide
Root Causes and Solutions

Savepoint Histogram
The performance of the backup can be analyzed with this statement:
select mbc.backup_id,
SECONDS_BETWEEN (mbc.sys_start_time, mbc.sys_end_time) seconds,
round(sum(backup_size) / 1024 / 1024 / 1024,2) size_gb,
round(sum(backup_size) / SECONDS_BETWEEN (mbc.sys_start_time, mbc.sys_end_time) /
1024 / 1024, 2) speed_mbs
from m_backup_catalog_files mbcf , m_backup_catalog mbc
where mbc.entry_type_name = 'complete data backup'
and mbc.state_name = 'successful'
and mbcf.backup_id = mbc.backup_id
group by mbc.backup_id, mbc.sys_end_time, mbc.sys_start_time order by
mbc.sys_start_time
3.5 Conguration Parameter Issues
The SAP HANA database creates alerts if it detects an incorrect setting for any of the most critical
conguration parameters.
The following table lists the monitored parameters and related alerts.
SAP HANA Troubleshooting and Performance Analysis Guide
Root Causes and Solutions
P U B L I C 61

Alerts related to conguration
Alert ID Alert Name Parameter Further Information
10 Delta merge (mergedog)
conguration
Indexserver.ini – mergedog - active Delta Merge
16 Lock wait timeout cong-
uration
Indexserver.ini – transaction –
lock_wait_timeout
Transactional Problems
32 Log mode legacy Global.ini – persistence – log_mode Issues with Conguration Parameter
log_mode (Alert 32 and 33)
33 Log mode overwrite Global.ini – persistence – log_mode Issues with Conguration Parameter
log_mode (Alert 32 and 33)
To check for parameters that are not according to the default settings, the following SQL statement can be
used.
select a.file_name, b.layer_name, b.tenant_name, b.host, b.section, b.key,
a.value as defaultvalue, b.currentvalue from sys.m_inifile_contents a
join ( select file_name, layer_name, tenant_name, host, section, key,
value as currentvalue from sys.m_inifile_contents b where layer_name
<> 'DEFAULT' )
b on a.file_name = b.file_name and a.section = b.section and a.key = b.key
and a.value <> b.currentvalue
Note
Default values of parameters may change when updating the SAP HANA database with a new revision.
Custom values on the system level and on the host level will not be aected by such updates.
Correcting Parameter Settings
You can change conguration parameters using the SAP HANA cockpit or the ALTER SYSTEM ALTER
CONFIGURATION statement.
All conguration parameters are dened in table CONFIGURATION_PARAMETER_PROPERTIES. You can look
up parameter details either in the system using for example SAP HANA cockpit or by referring to the
Conguration Parameter Guide in the SAP Help Portal. In addition to basic properties such as data type, unit
and a default value the denition includes a ag to indicate if a system restart is required before a changed
value becomes eective.
Usually alerts on incorrect parameter settings include information about correct setting of the parameter. So,
unless you have received a specic recommendation from SAP to change the parameter to another value, you
can x the issue by changing the parameter from the Conguration of System Properties monitor of SAP HANA
cockpit. You can search for a specic parameter by ltering on the parameter name. In most cases the
suggested correct value will be the default value. Most of the parameters can be changed online and do not
require any further action; exceptions for common parameters are noted in the reference document referred to
above. For more information about how to change parameters, see Memory Information from Logs and Traces.
Note
Make sure that you change the parameter in the correct ini-le and section, since the parameter name
itself may be not unique.
62
P U B L I C
SAP HANA Troubleshooting and Performance Analysis Guide
Root Causes and Solutions

Related Information
Delta Merge [page 68]
Transactional Problems [page 111]
Issues with Conguration Parameter log_mode (Alert 32 and 33) [page 63]
Memory Information from Logs and Traces [page 23]
3.5.1 Issues with Conguration Parameter log_mode (Alert
32 and 33)
Alerts 32 and 33 are raised whenever the write mode to the database log is not set correctly for use in
production.
Context
To ensure point-in-time recovery of the database the log_mode parameter must be set to ‘normal’ and a data
backup is required.
The following steps are recommended when facing this alert:
Procedure
1. Change the value of the parameter log_mode in SAP HANA cockpit to normal
2. Schedule an initial data backup
3. Test successful completion of the backup
4. Restart the database
5. Backup the database conguration
For information on how to perform a backup of database conguration les see SAP Note 1651055 -
Scheduling SAP HANA Database Backups in Linux.
6. Schedule a regular data backup
Related Information
SAP Note 1651055
SAP Note 1900296
SAP Note 1900267
SAP HANA Troubleshooting and Performance Analysis Guide
Root Causes and Solutions
P U B L I C 63

3.6 Backup And Recovery
This section discusses issues related to backup and recovery and how to troubleshoot them.
Back and Recovery: Resources
For detailed information on how to perform a backup or recovery of an SAP HANA database please refer to
section SAP HANA Database Backup and Recovery of the SAP HANA Administration Guide.
Note
Following the conguration information, prerequisites and requirements for your HANA release and
revision as documented in the SAP HANA Administration Guide can avoid the most common issues faced
by customers when performing a backup or recovery.
Backup and Recovery can be done in SAP HANA studio or in SAP HANA cockpit; refer to the documentation for
these administration tools for details.
Videos demonstrating backup and recovery can be found on the SAP HANA Academy YouTube channel:
https://www.youtube.com/user/saphanaacademy
The following links to the SAP HANA Support Wiki provide a step-by-step description with detailed screenshots
of how Backup and Recovery can be executed from SAP HANA studio:
● How to Perform a Backup
● Recovery
In addition to the SAP Notes and Knowledge Base Articles referred to in this section, the following may also be
useful:
● SAP Note 1642148 - FAQ: SAP HANA Database Backup & Recovery
● SAP Note 2116157 - FAQ: SAP HANA Consistency Checks and Corruptions
● SAP KBA 2101244 - FAQ: SAP HANA Multitenant Database Containers (MDC)
● SAP Note 2096000 - SAP HANA multitenant database containers - Additional Information
● SAP KBA 2486224 - Tenant DB recovery to another system Tenant DB
● SAP Note 2093572 - SAP HANA Migration from Multi-Node to Single-Node
● SAP Note 1730932 - Using backup tools with Backint for HANA
● SAP Note 1651055 - Scheduling SAP HANA Database Backups in Linux
● SAP Note 2044438 - HANA: Backup fails for Out Of Memory error
● SAP Note 2123153 - HANA Recovery Failing with 'recovery strategy could not be determined'
● SAP Note 2063454 - Long running log backups
● SAP KBA 2495074 - Recovery failed with data backup le of higher HANA revision
● SAP KBA 1990971 - HANA backup failed with 'Wrong Checksum' error
● SAP Note 2605215 - Replay of Logs Hanging During Point in Time Recovery or Operations on System
Replication Secondary Site
64
P U B L I C
SAP HANA Troubleshooting and Performance Analysis Guide
Root Causes and Solutions

Logs and Trace Files
In most cases for both backup and recovery issues a relevant error message will be written to the following SAP
HANA database log or trace les:
● backup.log
● namesever.trc
● backint.log (if using backint and 3rd party tool)
These log and trace les (diagnostic les) can be found using SAP HANA studio, DBA Cockpit, and SAP HANA
Database Explorer. The default location for the les is:
/usr/sap/<SID>/HDB<Instance#>/<host>/trace
You can search for either backup or recovery tasks which generate an error in the backup.log le by referring to
the task type and the date and time that the issue occurred:
2018-09-26T06:58:11+00:00 16614abbef0 INFO BACKUP SAVE DATA started
2018-08-29T09:45:52+00:00 1658510b5bb ERROR BACKUP SAVE DATA finished with
error: [447] backup could not be completed ….rc=28: No space left
2018-08-29T09:45:52+00:00 1658510b5bb INFO BACKUP state of service…
With the error code and error message you can search for SAP Notes and Knowledge Base Articles in the SAP
Knowledge Base using
SAP ONE Support Launchpad
Increasing the trace level
Although in most cases it should not be necessary to use the debug trace level to nd the relevant error
message, if the standard trace level for the backup.log le does not return a meaningful error message you can
temporarily set the level to 'debug' using the following commands:
Enable the trace:
ALTER SYSTEM ALTER CONFIGURATION ('global.ini', 'SYSTEM') SET ('backup',
'trace') = 'debug' with reconfigure;
Disable the trace:
ALTER SYSTEM ALTER CONFIGURATION ('global.ini', 'SYSTEM') UNSET ('backup',
'trace') with reconfigure;
Common Issues Related to Backup and Recovery
Some of the most common issues are described here.
Log Volume Full
The symptoms of a log volume full are:
● Alert #2 is generated, for example: "Alert disk usage" for "storage type: LOG".
● The database cannot be started or does not accept new requests.
● The database trace le of a service contains rc=24 no space left on device errors for the
basepath_logvolumes or basepath_logbackup.
SAP HANA Troubleshooting and Performance Analysis Guide
Root Causes and Solutions
P U B L I C 65

Note
Note that when a cluster le system like HP IBRIX or IBM GPFS is used, HANA Studio or OS commands like
df -h might not detect a problem. In this case use the lesystem specic commands like mmdf/
mmrepquota for IBM GPFS.
In this situation reasons for data and log backups failing may include:
● Backup location for data and log backup is the same location as data and log volumes and space runs out
● Automatic log backup parameter is not enabled (enable_auto_log_backup). If automatic log backup is
disabled, the log area grows until the le system is full. If the le system is full, the database will remain
frozen until the situation is resolved.
See the following SAP Notes for troubleshooting details in this case:
● 2083715 - Analyzing log volume full situations.
● 1679938 - Disk Full Event on Log Volume.
Large Size of Log Backup Files
The backup catalog stores information about the data and log backups that were executed for a database and
the catalog is backed up as part of the log backups. If you do not ensure that old backups are deleted in
accordance with backup and recovery strategy the log backups can become increasingly large over time.
For information on the clean-up of the backup catalog see the following:
● 'Housekeeping for Backup Catalog and Backup Storage' in the SAP HANA Administration Guide
● KBA 2096851 - Backup Catalog Housekeeping within HANA DB
● KBA 2505218 - Large Log Backups due to large backup catalog
Regular manual consistency check of backups required for SAP HANA Database Recovery
Although HANA has automatic checks that take place while data and log backups are performed you should
manually re-check the integrity of any backup if it is copied or moved to another location or if you need to use
the backup les for HANA database recovery. This manual check can be done using hdbbackupcheck.
For information on the usage of the hdbbackupcheck command see the KBA 1869119 - Checking backups with
'hdbbackupcheck'
Problems With Backint and 3rd Party Backup Tools
SAP HANA comes with native functionality for backup and recovery but using 3rd party backup tools is an
alternative to using the native functionality. SAP HANA database provides a backup interface called Backint
which enables 3rd-party backup tool vendors to connect their product to the backup and recovery capabilities
of the SAP HANA database. Backint is fully integrated into the SAP HANA database, that is, data and log
backups can be individually congured to be created and recovered using the 3rd-party backup tool. Backups
are transferred via pipe from the SAP HANA database to the 3rd party backup agent, which runs on the SAP
HANA database server and then sends the backups to the 3rd party backup server.
For more information on SAP HANA backup and recovery and the integration of 3rd party backup tools with
SAP HANA, please refer to:
● The SAP HANA Administration Guide
● The installation documentation for 3rd party backup tools provided by the tool vendor
● SAP Note 2031547 - Overview of SAP-certied 3rd party backup tools and associated support process
66
P U B L I C
SAP HANA Troubleshooting and Performance Analysis Guide
Root Causes and Solutions

If you face an issue with a 3rd party backup tool check SAP Note 2031547 to conrm that the backup tool is
supported. If the tool is supported the next step is to check for error messages in the backint.log le as
described above. Follow the appropriate support process for the tool as described in the SAP note 2031547.
As a workaround for a problem with a 3rd party backup tool, and if you have the required disk space, you could
use the SAP HANA native functionality for backup.
HANA BACKUP and Recovery Performance
In many cases, problems with backup and recovery performance are related to non-optimal system I/O or the
backup catalog size.
To check the HANA I/O performance refer to the Knowledge Base article 1999930 - FAQ: SAP HANA I/O
Analysis. Regarding the backup catalog refer to the subsection above Large size of Log Backup les.
To analyze performance problems related to backup and recovery you can also refer to the guided answer
Troubleshooting Performance Issues in SAP HANA, if the guided answer does not provide a solution for further
analysis SAP Support would require the information in the SAP Note 1835075 - Analyze backup and recovery
performance issues.
Related Information
SAP Note 1642148
SAP Note 1651055
SAP Note 1679938
SAP Note 1730932
SAP Note 1835075
SAP Note 1869119
SAP Note 1990971
SAP Note 1999930
SAP Note 2031547
SAP Note 2044438
SAP Note 2063454
SAP Note 2083715
SAP Note 2093572
SAP Note 2096000
SAP Note 2096851
SAP Note 2101244
SAP Note 2116157
SAP Note 2123153
SAP Note 2486224
SAP Note 2495074
SAP Note 2505218
SAP HANA Troubleshooting and Performance Analysis Guide
Root Causes and Solutions
P U B L I C 67

SAP Note 2605215
3.7 Delta Merge
This section covers troubleshooting of delta merge problems.
The column store uses ecient compression algorithms to keep relevant application data in memory. Write
operations on the compressed data are costly as they require reorganizing the storage structure and
recalculating the compression. Therefore write operations in column store do not directly modify the
compressed data structure in the so called main storage. Instead, all changes are at rst written into a separate
data structure called the delta storage and at a later point in time synchronized with the main storage. This
synchronization operation is called delta merge.
From an end user perspective, performance issues may occur if the amount of data in the delta storage is large,
because read times from delta storage are considerably slower than reads from main storage.
In addition the merge operation on a large data volume may cause bottleneck situations, since the data to be
merged is held twice in memory during the merge operation.
The following alerts indicate an issue with delta merges:
● Delta merge (mergedog) conguration (Alert 10)
● Size of delta storage of column store tables (Alert 29)
Related Information
SAP Note 1909641
SAP Note 1977314
3.7.1 Inactive Delta Merge
In case the delta merge is set to inactive, Alert 10 Delta merge (mergedog) conguration is raised. In a
production system this alert needs to be handled with very high priority in order to avoid performance issues.
Context
Whenever issues with delta merge are suspected, this alert should be checked rst. You can do that from the
Alerts tile or the Alert Checker Conguration app. An inactive delta merge has a severe performance impact on
database operations.
68
P U B L I C
SAP HANA Troubleshooting and Performance Analysis Guide
Root Causes and Solutions

Procedure
1. Check the current parameter value in the Conguration of System Properties page of SAP HANA cockpit
and lter for mergedog.
Check the value of active in the mergedog section of the indexserver.ini le.
2. To correct the value, click Change Layer and choose Restore Default.
This will delete all custom values on system and host level and restore the default value system-wide.
Note
Depending on the check frequency (default frequency: 15 minutes) the alert will stay in the Alert inbox
until the new value is recognized the next time the check is run.
Related Information
SAP Note 1909641
Memory Information from Logs and Traces [page 23]
3.7.1.1 Retrospective Analysis of Inactive Delta Merge
Retrospective analysis of the root cause of the parameter change that led to the conguration alert requires the
activation of an audit policy in SAP HANA that tracks conguration changes.
Other sources of information are external tools (for example, SAP Solution Manager) that create a snapshot of
conguration settings at regular intervals.
For details about conguring security auditing and for analyzing audit logs, refer to the SAP HANA Security
Guide.
Related Information
SAP HANA Security Guide
SAP HANA Troubleshooting and Performance Analysis Guide
Root Causes and Solutions
P U B L I C 69

3.7.2 Indicator for Large Delta Storage of Column Store
Tables
If the delta storage of a table gets too large, read operations on the table will slow down. This usually results in
degraded performance of queries reading from the aected table.
When the delta storage of a table gets too large, the Alert Size of delta storage of column-store tables (Alert 29)
can be raised.
Alert 29 is raised when the amount of memory consumed by the delta storage exceeds the congured
thresholds. The thresholds can be customized in the SAP HANA cockpit to take into account the congured
size of the delta storage. Note that if the alerts are not congured properly, the symptoms can occur without
raising an alert, or there may be no symptoms, even though an alert is raised. For each aected table a
separate alert is created.
Usually this problem occurs because of mass write operations (insert, update, delete) on a column table. If the
total count of records (record count * column count) in the delta storage exceeds the threshold of this alert
before the next delta merge, this alert will be triggered.
Corrective action needs to be taken in one of the following areas:
● Change of an application
● Changed partitioning of the table
● Conguration of delta merge
Related Information
SAP Note 1977314
3.7.2.1 Analyze Large Delta Storage of Column Store
Tables
Analyze and interpret issues related to delta storage with help from alerts in SAP HANA cockpit.
Procedure
1. If an alert was raised, go to the Alerts tile in the SAP HANA cockpit, click Show all and lter for "delta
storage".
Check if the alert is raised for a small number of tables or for many tables. Focus on tables where the alert
has high priority. Alerts raised with low or medium priority usually don’t need immediate action, but should
be taken as one indicator for checking the sizing. Also these alerts should be taken into account when
specic performance issues with end-user operations on these tables are reported, since read-access on
delta storage may be one reason for slow performance.
70
P U B L I C
SAP HANA Troubleshooting and Performance Analysis Guide
Root Causes and Solutions

2. Click on an alert and check the alert details about its previous occurrences visible in the graph.
a. If the alert occurred several times, check since when this started. To monitor a longer period of time,
use the drop-down menu on the right.
b. Check whether it occurs regularly at a certain time.
This may indicate a specic usage pattern from application side that might have room for optimization.
For example, when many inserts and deletes are performed during a load process, it might be possible
to replace these operations with a suitable lter in the source system. You can employ the data in the
Expensive Statement Trace and the Performance Monitor to determine the usage of the table by
applications.
3. Check the timestamp of the alert if it is current, then start with checking current attributes of this table.
Information regarding the delta merge operation on specic tables can be obtained from the system view
M_CS_TABLES.
SELECT * FROM SYS.M_CS_TABLES where table_name='mytable' and
schema_name='myschema';
If no alert was raised, you can check for the tables with the most records in the delta.
SELECT * FROM SYS.M_CS_TABLES where record_count>0 order by
raw_record_count_in_delta desc;
4. Check the following attributes:
○ LAST_MERGE_TIME
○ MERGE_COUNT
○ READ_COUNT, WRITE_COUNT
○ RECORD_COUNT
○ RAW_RECORD_COUNT_IN_MAIN
○ RAW_RECORD_COUNT_IN_DELTA
○ MEMORY_SIZE_IN_MAIN
○ MEMORY_SIZE_IN_DELTA
a. If MERGE_COUNT is high then this is an indicator that the delta merge works properly, while a low
MERGE_COUNT suggests a need for corrective action.
A large dierence between RAW_RECORD_COUNT_IN_MAIN and RECORD_COUNT suggests that the
table has not been compressed properly. Note that compression is not triggered when a merge is
triggered from an SQLScript, but only in case of Auto, Smart or Critical Merge.
A high WRITE_COUNT suggests that many insert, update and delete operations occur. If the
occurrence of the delta merge problem is rare, then it usually will be sucient to trigger the merge for
this table manually. See Perform a Manual Delta Merge Operation in the SAP HANA Administration
Guide.
b. If there are many deleted records, you can trigger a compress of the table with the following command:
UPDATE mytable WITH PARAMETERS('OPTIMIZE_COMPRESSION'='YES');
c. Conrm the delta merge operation has succeeded in the following ways:
○ LAST_MERGE_TIME
○ MERGE_COUNT
○ RAW_RECORD_COUNT_IN_DELTA
SAP HANA Troubleshooting and Performance Analysis Guide
Root Causes and Solutions
P U B L I C 71

○ LAST_COMPRESSED_RECORD_COUNT
5. If problems with the delta storage re-occur frequently for a specic table, check the merge statistics for
this table. You can do this in the SAP HANA database explorer by executing the Merge Statistics statement
in the Statement Library. You can lter by table name and schema name.
Alternatively you can run the following SQL statement and perform the following checks:
SELECT * FROM SYS.M_DELTA_MERGE_STATISTICS where table_name='mytable' and
schema_name='myschema';
a. Check column SUCCESS for records with value other than TRUE.
b. Check the column LAST_ERROR for records with value other than 0. A typical error is 2048 and
ERROR_DESCRIPTION shows error 2484 which indicates that there was not enough memory to
compress the table after the merge.
For other error codes please refer to the SAP HANA Administration Guide.
c. Check the columns START_TIME, EXECUTION_TIME, MOTIVATION and MERGED_DELTA_RECORDS.
For cases where MERGED_DELTA_RECORDS becomes excessively large the trigger function for the
MOTIVATION type should be reviewed and the LOAD should be analyzed for that time frame
( Performance Monitor ). A value of MERGED_DELTA_RECORDS = -1 suggests that no records were
merged but that a compression optimization was performed.
6. If you need to analyze the delta merge statistics for a longer period, use the equivalent select on table
HOST_DELTA_MERGE_STATISTICS of the statistics server:
SELECT * FROM _SYS_STATISTICS.HOST_DELTA_MERGE_STATISTICS where
table_name='mytable' and schema_name='myschema';
You can check the delta merge conguration in SAP HANA cockpit by opening Conguration of System
Properties indexserver.ini mergedog .
Since the default value for the frequency of delta merges is already 1 minute (check_interval = 60.000
ms), optimization with regards to memory consumption can only be done by adjusting the decision
function of the corresponding merge type and the corresponding priority function. However, changes
should be done very carefully and always with involvement of experts from SAP. Parameters of the
functions are documented in the SAP HANA Administration Guide.
Related Information
M_CS_TABLES
Work with Alerts
Inactive Delta Merge [page 68]
Use the Statement Library to Administer Your Database
Memory Information from Logs and Traces [page 23]
72
P U B L I C
SAP HANA Troubleshooting and Performance Analysis Guide
Root Causes and Solutions

3.7.3 Failed Delta Merge
If many cases are identied where auto merge has failed, the error codes need to be analyzed in more detail.
Note that the merge only failed if SUCCESS is not TRUE. In any other case the error code describes a non-
critical condition during a successful merge.
To analyze the error codes, you should increase the trace level to INFO for the components mergedog and
mergemonitor in the INDEXSERVER section of the Database Trace.
To change the trace conguration choose Trace Conguration from the database context menu in the SAP
HANA database explorer and change the conguration of the Database Trace.
The following table lists error codes and typical corrective actions.
Error Codes
Error
Description Recommended Action
1999 General error (no further information available) Check the indexserver trace for more errors regarding
the exception
2450 Error during merge of delta index occurred Check in diagnostic les for an Out-Of-Memory dump
that occurred during the delta merge operation
2458 Table delta merge aborted as cancel was manually re
quested by a kill session call.
No action required.
2480 The table in question is already being merged. No action required.
2481 There are already other smart merge requests for this
table in the queue.
No action required.
2482 The delta storage is empty or the evaluation of the
smart merge cost function indicated that a merge is
not necessary.
No further action required if this occurs occasionally.
If it happens frequently:
Check M_DELTA_MERGE_STATISTICS and review
smart merge cost function with SAP experts.
(parameter smart_merge_decision_func)
2483
Smart merge is not active (parameter
smart_merge_enabled=no)
Change the parameter
smart_merge_enabled=yes)
SAP HANA Troubleshooting and Performance Analysis Guide
Root Causes and Solutions
P U B L I C 73

Error Description Recommended Action
2484 Memory required to optimize table exceeds heap limit
(for failed compression optimization operations,
TYPE=SPARSE, SUCCESS=FALSE).
No further action required if this occurs occasionally.
If it happens frequently:
A) Analyze change operations on the table and con
sider table partitioning to minimize the size of the
delta storage. If no knowledge about application is
available, Hash Partitioning with a size of 500.000.00
records is a good initial choice.
B) Analyze change operations on the table and con
sider adjusting the parameter
auto_merge_decision_func
C) Increase delta storage
D) Review sizing
6900
Attribute engine failed Internal error. Check the indexserver trace for more
errors regarding the exception.
29020 ltt::exception caught while operating on $STORA
GEOBJECT$
Internal error. Check the indexserver trace for more
errors regarding the exception.
Related Information
Memory Information from Logs and Traces [page 23]
3.7.4 Delta Storage Optimization
Table partitioning allows you to optimize the size of tables in memory and their memory consumption as each
partition has its own delta storage.
The memory consumption of a table in memory during a merge operation depends on the number of records,
the number and memory size of columns and the memory size of the table. While the number of records can be
kept low by triggering a smart merge from the application, optimization with regards to the size of the table can
be achieved by table partitioning. This is due to the fact that each partition holds a separate delta storage.
When a merge is performed, the data from the main storage has to be loaded into memory which is a
considerably less amount when only a single partition is handled rather than the full table.
When considering partitioning it is recommended to analyze the typical usage of this table. Partitions should be
created in a way that avoids as much as possible that single statements need to access multiple partitions. If
no application knowledge is available, then hash partitioning with a partition size of about 500.000.000 records
is a good initial choice.
See, Table Partitioning in the SAP HANA Database in the SAP HANA Administration Guide.
74
P U B L I C
SAP HANA Troubleshooting and Performance Analysis Guide
Root Causes and Solutions

Related Information
Table Partitioning
3.8 SAP Web IDE
This section covers problems related to SAP Web IDE.
The SAP Web Integrated Development Environment (formerly known as Web Application Toolkit) is a powerful,
extensible, web-based tool that simplies both the development of end-to-end SAP Fiori apps and the full-
stack (UI, business logic and database) application lifecycle. It covers development, modeling, debugging,
building, testing, extending and deployment of role-based consumer-grade apps. Resources to support rapid
development include wizards, templates, samples, code and graphical editors, modelers, and more.
3.8.1 Post-Installation Problems with Web IDE
This section identies some common post-installation issues which you may encounter when working with
WebIDE.
Logging in to Space Enablement UI
Issue:
Logging into space enablement UI gives a 'Forbidden' error.
Cause: Missing authorizations.
Resolution:
Ensure that the user logging into the di-space-enablement-ui app has the proper
authorizations as follows:
● The role collection XS_CONTROLLER_USER
● A manually-created role collection containing WebIDE_Administrator and/or
WebIDE_Developer role.
● SpaceDeveloper role and/or SpaceManager role.
More Information: For more information see the following documents (depending on your SAP HANA version):
● For SAP HANA version below HANA 2 SPS3 see 'Post-Installation Administration Tasks' in
SAP Web IDE for SAP HANA - Installation and Upgrade Guide
● For HANA 2 SPS3 and above see 'Roles and Permissions for Administration and
Development' in: SAP HANA Developer Guide for SAP HANA XS Advanced Model .
SAP HANA Troubleshooting and Performance Analysis Guide
Root Causes and Solutions
P U B L I C 75
Logging into Web IDE
Issue: Logging into WebIDE gives an internal server error or shows a blank page.
Cause: Missing authorizations
Resolution: Ensure the WebIDE User has the correct role collections and is part of space as
SpaceDeveloper (role).
More Information: For more information see 'Roles and Permissions for Administration and Development' in the
SAP HANA Developer Guide for SAP HANA XS Advanced Model.
Unable to access di-local-npm-registry
Issue:
When trying to access the URL for di-local-npm-registry to check if a given node
module is present and check if the versions are available, the following error message appears:
"Error: web interface is disabled in the config file"
Cause:
Access to the web interface of di-local-npm-registry is disabled for security reasons.
Resolution: 1. Run the following command:
xs env di-local-npm-registry.
2. Copy the path shown in the 'storage-path'. It should look similar to this example:
/usr/sap/hana/shared/XSA/xs/controller_data/fss/
a44ae1be-8fa5-4470-b08a-db0begfs8f9f
3. Run your command-line session as root user and change directory to the storage path you
retrieved from the registry.
4. Search the SAP storage directory by rst changing directory again and then using the find
command:
cd storage/@sap
find
Related Information
SAP Web IDE for SAP HANA - Installation and Upgrade Guide
SAP HANA Developer Guide for SAP HANA XS Advanced Model
76
P U B L I C
SAP HANA Troubleshooting and Performance Analysis Guide
Root Causes and Solutions

3.8.2 Web IDE Common Issues with Modeling
This section gives details of some problems you may encounter when modeling with Web IDE.
Project Build Fails (Conguration Issue)
Issue: When building a Multi-Target Application (MTA) with multiple tenants available and with the
Database ID dened in the mta.yaml le, the project build fails with the error:
Failed to select a database for instance no database
'<DB_SID>' mapped to organization.
Cause: The tenant’s GUID, not the SID must be entered in the mta.yaml le.
Resolution: Find the tenant GUID by running the following command as an admin user (XSA_ADMIN) in the
XSA command line interface:
xs tenant-databases –guids
Once you have the GUID, enter this value in the cong parameter "database_id” in the mta.yaml
le.
Project Build Fails (Authorization Issue)
Issue:
When building an HDB module with synonyms to access objects in an external schema of HANA
DB (that is, the classical schema), you have dened the users, privileges and schemas correctly,
but the build fails. You see the error:
Error: com.sap.hana.di.synonym: The container's object owner
"HDB_HDI_DB_1#OO"
is not authorized to access the "SYSTEM.MATERIAL_D" synonym
target.
This user needs to be granted "SELECT" ("EXECUTE" for
procedures) privileges
on the target object. [8250505].
Cause:
When accessing objects from a classical schema, not only the provided database user needs
access to the objects, the object owner of the HDI container
(<ProjectName>_<HDIname>##OO) also needs access to these objects.
Resolution: You can provide access directly to the (<ProjectName>_<HDIname>##OO) user through, for
example, HANA Studio -> Security -> Users. It is better, however, to set up authorizations
properly. This is done by creating roles in HANA that give access to objects and the HDB Grants
le in the XSA Project which the #OO user can use to grant those privileges to other users if
needed.
SAP HANA Troubleshooting and Performance Analysis Guide
Root Causes and Solutions
P U B L I C 77

More Information ‘See Enable Access to Objects in a Remote Classic Schema’ in the SAP HANA Developer Guide
for SAP HANA XS Advanced Model.
Calculation View (Synonyms missing)
Issue: When creating a calculation view, you want to add data sources into one of the nodes in the view
and you cannot see any data sources from the HANA schema (synonyms, tables etc).
Cause: 1) You cannot see HANA Classical schema objects since you have not dened synonyms in your
project. In XSA (HDI Containers), you cannot directly access Classical HANA objects. You need to
create synonyms to access these objects.
2) You have congured synonyms and the mta.yaml le properly as per the documentation, but
you still cannot nd synonym objects when adding data sources in the calculation view. Although
you did dene the synonyms, the changes are still not saved and compiled.
Resolution:
For details of creating synonyms see ‘Database Synonyms in XS Advanced’ in the SAP HANA
Developer Guide for SAP HANA XS Advanced Model.
After conguring users, privileges, and schemas with the correct conguration parameters (as
described in the documentation), you need to build the HDB module to compile the changes.
They will then be visible in your project/DB Explorer.
Calculation View (Authorization Issue)
Issue:
When you try to data preview a calculation view in your Web IDE project that uses synonyms to
access external objects (HDI or HANA), you get the insucient privilege error.
Cause: The local HDI Containers object owner user (##OO) has the Select privilege on external object(s)
but does not have the Grant option. In the indexserver trace le, you also see an error such as:
User <Project)name>_<HDI_name>#OO is not allowed
to grant privilege SELECT for VIEW <CV_in_Question>
Resolution: Provide the object owner Select access to all the external objects with Grant option.
Or you can set up roles and HDB Grants as described in the SAP HANA Developer Guide for SAP
HANA XS Advanced Model. Refer to the following topics as appropriate:
‘Enable Access to Objects in a Remote Classic Schema’
‘Enable Access to Objects in Another HDI Container’
78 P U B L I C
SAP HANA Troubleshooting and Performance Analysis Guide
Root Causes and Solutions

Calculation View (Known Bug HANA 2 SPS 03)
Issue: When you try to access a calculation view with joins in your project, you see the error:
Cannot read property 'name' of undefined
Cause: One possible cause of this is a known bug in HANA 2 SPS 03 which corrupts the calculation view
le.
If this is the cause, when you look at the denition of the calculation view, you can see missing
mappings for the join condition, for example:
<mapping xsi:type="Calculation:AttributeMapping"
target="_<Target>"/> //
<-- source is missing
</input>
<joinAttribute name="_<Att_name>"/>
Workaround
Edit the calculation view in the code editor and manually correct the mappings that contain
target and source columns:
<mapping xsi:type="Calculation:AttributeMapping"
target="<Target>" source="<Source>"/>
Resolution: The permanent solution is to upgrade to HANA 2 SP 04.
Related Information
SAP HANA Developer Guide for SAP HANA XS Advanced Model (Access to Objects)
SAP HANA Developer Guide for SAP HANA XS Advanced Model (Database Synonyms)
SAP HANA Developer Guide for SAP HANA XS Advanced Model (Access to Objects in Other Container)
3.9 Troubleshooting BW on HANA
This section identies some of the common problem areas for users of Business Warehouse on HANA and
points to existing information sources which will help to resolve the issues.
Documentation
All public documentation related to BW on HANA can be found in the SAP Help Portal on the SAP Business
Warehouse product page. In the SAP Community Network (SCN) you can nd a complete end-to-end
collection of detailed BW on HANA related information including presentations, blogs, discussions, how-to
SAP HANA Troubleshooting and Performance Analysis Guide
Root Causes and Solutions
P U B L I C 79

guides, release information, videos, roadmap and so on. An internal WIKI page is also available with additional
information on BW on HANA troubleshooting.
● SAP Help Portal: SAP Business Warehouse, powered by SAP HANA.
● SAP Support Community: SAP Business Warehouse on SAP HANA and HANA SQL-based Data
Warehousing.
● WIKI: BW on HANA Documentation and Troubleshooting
This section refers to the transaction codes which are used to access each BW function, such as RSRT for the
Report Monitor and RSRV for Analysis and Repair of BW Objects. RSA1 is the Data Warehousing Workbench
which is the central cockpit used for the administration of almost the entire BW system. A list of the most
commonly-used transaction codes is given in a table at the end of this topic: Frequently-used Transaction
Codes.
Table Redistribution
BW on HANA Table Redistribution ensures that the tables of a BW system are partitioned correctly according
to the SAP recommendations and, in the case of a scale-out system, are dened on the correct database
nodes. This is important for the optimal performance of the system.
Refer to the following for details of how to congure table redistribution:
● SAP Note 1908075 - BW on SAP HANA: Table placement and landscape redistribution.
● KBA: 2517621 - After landscape redistribution data does not appear evenly distributed between the
slave nodes in terms of memory usage per a HANA node.
● Guided answer with step-by-step description of how to congure the table redistribution: How to carry out
preparations for a table redistribution for BW .
If the table placement and table redistribution are done correctly there should be no requirement to make
manual changes to the partitioning for BW tables. The expected partitioning for BW objects and associated
tables is described in the KBA 2044468 - FAQ: SAP HANA Partitioning (question 17. How should tables be
partitioned in BW environments?) and in the SAP Note 2019973 - Handling Very Large Data Volumes in SAP
BW on SAP HANA.
● KBA 2044468 - FAQ: SAP HANA Partitioning
● SAP Note 2019973 - Handling Very Large Data Volumes in SAP BW on SAP HANA
Two Billion Record Limit
Tip
It is not possible to partition BW master data SID tables. Irrespective of the underlying database, SID tables
of master data InfoObjects already have the upper limit value of 2 billion records imposed by the datatype
of the SIDs (INT4). A detailed explanation on this topic and what can be done to avoid this limitation is
available in the SAP Note 1331403 - SIDs, Number Ranges and BW InfoObjects
It is possible to proactively monitor the 2 billion table or partition limit on HANA using the SAP EarlyWatch Alert
Workspace in the SAP ONE Support Launchpad. Using this application, you get an overview of which tables are
approaching the limit including a prediction when the limit is reached, broken down into a mean, best-case and
worst-case scenario. By default, the forecast is based on all previous measurements.
80
P U B L I C
SAP HANA Troubleshooting and Performance Analysis Guide
Root Causes and Solutions

Further information is available in the Blog post The New 2 Billion Record Limit in the SAP EarlyWatch Alert
Workspace .
Checking Consistency with RSDU_TABLE_CONSISTENCY
You can use the ABAP report RSDU_TABLE_CONSISTENCY to check that the table placement is correct and
that the BW objects are located on the correct HANA nodes. A user document for the report is attached to the
SAP Note 1937062 - Usage of RSDU_TABLE_CONSISTENCY.
A practical example of where this report can be useful is around DSO activation performance issues. If the DSO
activation is in a distributed HANA environment and it takes longer than expected, you should check if the
partitioning of DSO tables (Active Data, Activation Queue and Change Log tables) is consistent, that is, same
partitioning and same hosts for the related partitions.
The RSDU_TABLE_CONSISTENCY report is only available in BW on HANA systems and not in the next-
generation data warehouse product BW/4HANA where most of the checks made by the report are obsolete.
Some checks made by the report that are still required will move to transaction RSRV see following section and
see also Analysis and Repair Environment in the NetWeaver section of the SAP Help Portal.
Consistency Checks With RSRV Transaction
RSRV consistency checks (Analysis and Repair Environment) are part of the BW application. In the analysis
and repair environment, you can perform consistency checks on the data and metadata stored in a BW system.
The main purpose of this is to test the foreign key relationships between the individual tables of the enhanced
star schema of the BW system. These checks can be useful to solve problems in BW on HANA environments if
you are getting unexpected data results. It can happen as well that BW application inconsistencies can cause
errors when Converting Standard InfoCubes to SAP HANA-Optimized InfoCubes, the RSRV checks can be used
to nd and resolve these inconsistencies.
See SAP Netweaver Modeling documentation: Converting Standard InfoCubes to SAP HANA-Optimized
InfoCubes.
Delta Merge
The implementation and operation of a SAP BW on HANA system requires a solid understanding of the delta
merge process in the database. Understanding this will allow administrators to optimize data loading and can in
some cases help improve the performance of BW on HANA queries. Delta merge processing can consume a
signicant amount of system resources especially for large tables and therefore needs to be understood to
manage any system powered by SAP HANA.
For more information please see:
● For detailed information on delta merge conguration for BW: How To Delta Merge for SAP HANA and SAP
BW powered by SAP HANA .
● For information on troubleshooting delta merge: KBA 2057046 - FAQ: SAP HANA Delta Merges
SAP HANA Troubleshooting and Performance Analysis Guide
Root Causes and Solutions
P U B L I C 81

Query execution modes (RSRT)
For query execution BW always checks if optimized operations can be pushed down to the HANA database, the
four available execution modes can be seen in RSRT from the query properties:
In some cases, especially where there is no support for push down of BW functionality to HANA Database or
where you get an error or have performance problem with HANA operation modes (TREXOPS=6 or
TREXOPS=7 or TREXOPS=8) it can make sense to use operation mode 0 (No optimized operations in SAP
HANA/no BWA) at least as a workaround to execute the query.
Not all BW queries will benet from the HANA operation modes that push down BW functionality to the HANA
Database. The benet depends on the exact query denition and the data in the providers. Therefore, it is
necessary to test the impact of this feature on the performance of every single query (where the runtime of the
query is critical) and then choose the proper query operation mode.
82
P U B L I C
SAP HANA Troubleshooting and Performance Analysis Guide
Root Causes and Solutions

For more information please see:
● For information on the operation modes: Netweaver Generic Tools and Services documentation Operations
in SAP HANA / BWA
● For more detail on the process logic: the SAP Blog BW-on-HANA and the Query Execution Mode .
● For a list of the functionality that is currently pushed down to HANA, refer to the SAP Note 2063449 -
Push down of BW OLAP functionalities to SAP HANA.
● For information on testing the benets of pushdown: 2365030 - Bex Query slower with HANA
pushdown
Performance issues
There is often the expectation after a BW on HANA migration from another database that all BW queries should
be much faster. Of course, if the query was slow already before database migration to HANA due to some
calculations happening on the BW application server and these calculations cannot be pushed down to HANA
DB then HANA cannot help for these use cases; a redesign of the BW query will be necessary.
The query run time component that we can expect to see signicantly improved with HANA is the database
time, this is the Event ID 9000 (Data Manager Time) in the BW Query run time statistics. What we can possibly
improve with HANA apart from the database time is the time spent in the analytic Manager. The analytic
manager in BW (previously known as the OLAP engine) is the brain of BW when it comes to BW query
processing, so it is responsible for navigation, ltering and aggregation among other things in the query
execution.
For additional information here please refer to the KBA 2122535 - How to determine if a BW on HANA query
performance problem is HANA database related.
Before starting performance troubleshooting on HANA, we rst need to identify if there is a general
performance problem for the BW on HANA system or if the problem is just for one BW query or report.
For information on the steps to verify this, troubleshoot the issue and collect the required logs and traces refer
to the HANA WIKI Troubleshooting HANA Performance issues .
Plan Viz Trace generated in RSRT
RSRT can be used to check Business Explorer (BEx) queries. The benet of using RSRT to check a BW query is
that it is independent of the client frontend, so you can eliminate the client frontend tool (Bex, BI frontend tool
etc) from the problem analysis. If the issue can be reproduced in RSRT then the issue is not related to the client
frontend.
Transaction RSRT provides several debug features that are helpful when analyzing a BW query. With BW on
HANA queries are usually executed on the HANA database using stored procedure TrexViaDbsl or
TrexViaDbslWithParameter. The call of procedure TrexViaDbsl(withParameter) can be displayed in RSRT if the
Debugag Python Trace or Plan/Performance Trace is set on BW740 systems or Generate Plan Viz File on
BW750 systems. You can copy this call and use it in SAP HANA Studio to execute Plan Viz to check the
execution plan.
Prerequisites: at least BW 740 SP13 and HANA 1.0 SPS 11
SAP HANA Troubleshooting and Performance Analysis Guide
Root Causes and Solutions
P U B L I C 83

Refer to the Wiki as follows:
● For basic information on transaction RSRT: Query Monitor .
● For the detailed steps on how to do this: BWonHana: PlanViz Trace generated in RSRT .
It is often the case that performance issues for individual BW queries can be resolved with HANA hints. For
details of hints refer to the KBA 2142945 - FAQ: SAP HANA Hints.:
● Question 4. What are important hints related to SAP HANA?
● Question 3 How can hints be specied? (describes how the hints can be set on the BW application level).
Composite Provider
One of the most used InfoProviders for BW on HANA reporting is the composite provider which can be created
using the BW Modeling tools.
● Refer to the blog SAP BW Modeling tools: Three things to know when using the BW modeling tools in
Eclipse
A Composite Provider is an InfoProvider in which you can combine data from BW InfoProviders such as
InfoObjects, DataStore Objects, SPOs and InfoCubes, or SAP HANA views such as Analytical or Calculation
Views using join or union operations to make the data available for reporting.
To avoid performance issues with BW queries created on the composite provider, especially related to the use
of joins or navigation attributes, it is important that the composite provider is modeled based on the
information in the following SAP Notes:
● 2271658 - Design Considerations for Composite Provider
● 2103032 - Long runtimes in query on Composite Provider
Advanced DSO
The end goal for the advanced DSO (ADSO) is to be the central persistency object in BW-on-HANA replacing
the InfoCube, classic DSO, HybridProvider and PSA. While there are still some gaps to cover the complete
functionality, we recommend considering the advanced DSO for all new projects as the central (and only)
persistency object.
Additional information on the ADSO can be found in the following:
● SCN blog post The "advanced” DataStoreObject – renovating BW's persistency layer
● SAP Note 2070577 - (advanced) DataStore Object - availability in BW7.4 SP08, SP09 and SP10
To avoid data loading or reporting performance problems related to ADSO please implement the
recommendations and corrections from the below SAP Notes:
● 2185212 - ADSO: Recommendations and restrictions regarding reporting
● 2684950 - 750SP14: Performance problems during access of DTP with source as ADSO
● 2374652 - Handling very large data volumes with advanced DataStore objects in SAP BW on SAP HANA
and BW/4HANA
84
P U B L I C
SAP HANA Troubleshooting and Performance Analysis Guide
Root Causes and Solutions

Column Views
After you migrate a BW system to a BW on SAP HANA Database all InfoProviders and InfoObjects must have
so-called column views. These views are needed for reporting. In case a new BW InfoProvider or InfoObject is
created, the associated column view is generated during activation on the SAP HANA database. If column
views do not exist or are inconsistent, the associated BW queries based on the view may fail.
Problems with column views on SAP HANA can often be resolved by recreating the column view for the
associated InfoProvider, this can be done using the report RSDDB_LOGINDEX_CREATE. For further
information:
● KBA 2106851 - Column Store Error 2048 executing RSDDB_LOGINDEX_CREATE on Multiprovider - on
symptoms related to these issues and how to use the report to resolve them.
● SAP Note 1695112 - Activities in BW after migrating to the SAP HANA database for possible root causes
for HANA view inconsistencies especially after the database migration to HANA.
You can use the report RSDDB_INDEX_CREATE_MASS to generate views for more than one InfoProvider.
Further information can be found in the Wiki:
● BWonHANA: InfoProvider column views .
Authorization issues related to BW on HANA Generated views
To ensure that you have the required permissions to access views and data related to BW on HANA please
follow the conguration steps in the following:
● Help Portal: Authorizations for Generating SAP HANA Views.
● SAP Community: SAP FirstGuidance–SAPBW 7.4onSAPHANA-SAP HANA View Generation (contains
detailed steps to setup and congure access to BW on HANA Generated views)
● If after doing the above conguration you still get an authorization related error when accessing the BW
generated view on HANA you can nd the missing privilege(s) using the information in SAP Note: 1809199
- SAP HANA DB: Debugging user authorization errors.
Data loading, sizing and memory usage
After a BW on HANA migration if you experience high memory usage or OOM dumps on HANA during data
loading using Data Transfer Process or info package please check if the below SAP Notes are applicable in your
case and applied in your system if relevant:
● 2230080 - Consulting: DTP: Out of memory situation during 'SAP HANA Execution' and the 'Request by
Request' Extraction
● 2402503 - Increased memory requirement of BW objects in SAP HANA
● 2602477 - Considerations for packagewise extraction from HANA DataSource based on Calculation
Views
If you experience high loads and unloads of column store tables as described in the KBA 2127458 - FAQ: SAP
HANA Loads and Unloads the sizing of the system should be checked.
SAP HANA Troubleshooting and Performance Analysis Guide
Root Causes and Solutions
P U B L I C 85

You can use the program /SDF/HANA_BW_SIZING to size the system either before the database is migrated to
HANA to get an estimation of the required hardware and memory requirements, or after the migration when
the database is running on HANA to check if the sizing of the BW on HANA system is correct.
Further information on the usage of this program is available in the SAP Note 2296290 - New Sizing Report
for SAP BW/4HANA.
To get an overview of the current memory usage in the HANA system you can use the script
HANA_Memory_Overview_1.00.90+.txt from the KBA 1969700 - SQL Statement Collection for SAP HANA,
the script shows the size of the row and column store tables and also the size of the HANA memory HEAP
allocators.
If this script shows high memory usage for HANA HEAP allocator(s) you can use the information in question 13.
What can I do if a certain heap allocator is unusually large? from the KBA 1999997 - FAQ: SAP HANA
Memory to understand what the purpose of the HEAP allocator is and also to understand what can be done to
reduce the memory consumption for the HEAP allocator.
For information on how to do housekeeping for large BW on HANA row store tables refer to the information in
the KBA
2388483 - How-To: Data Management for Technical Tables.
Wrong Data
As a rst step to analyze wrong data or unexpected results, the issue should be checked from the BW
application side using the steps given in the BW application KBAs:
● 2271335 - Wrong Data is Read from a HANA InfoProvider,
● 2399752 - Dierent Results with Operations Mode in BWA/HANA (TREXOPS) in a BW Query
● 1508237 - First Steps to Check Wrong Number in BW Query (Transaction RSFC).
If the BW application KBAs don’t help you to nd the root cause of the problem all known reasons why the
HANA database could return wrong or unexpected results are explained in the KBA 2222121 - SAP HANA
Wrong Result Sets.
Frequently-used Transaction Codes
The following table lists (in alphabetical order) the most often used transaction codes when working in a BW on
HANA system:
Tcode
Description
AL11 SAP Directories, you can nd trans log under DIR_TRANS,
work process log under DIR_HOME, etc. It’s useful when you
don’t have authorization to run st11
DB01 Display blocked transactions, you can nd the same
information under DBACOCKPI->Diagnostics->Locks-
>Blocked Transactions
86 P U B L I C
SAP HANA Troubleshooting and Performance Analysis Guide
Root Causes and Solutions
Tcode Description
DB02 Display Consistency Check result, help you to nd out
missing objects in database, unknown objects in ABAP.
Index checks etc. It will display the same interface as
DBACOCKPIT/ST04->Diagnostics->Missing Tables and
Indexes
DBCO Maintain secondary Database connections
LISTCUBE List content of an Info Cube
OS01 LAN Check by Ping, can check the connectivity between DB
server and Application server
RS2HANA_CHECK Check all prerequisites for successful replication of BW
authorizations to SAP HANA, it can be used to check if the
BW users has authorization to run the HANA views
generated from the BW model
RS2HANA_ADMIN It can be used as a general entry point where all BW objects
with enabled "External SAP HANA View" are visible.
RSA1 Data Warehousing Workbench (>= BI 7.0) / Administrator
Workbench (< B I 7.0), The administrator workbench is the
central cockpit used for the administration of almost the
entire BW system. The RSA1 main screen can be divided
into three general areas. The extreme left area, allows us to
choose BW modelling components like Infoproviders,
InfoObjects, InfoSources and DataSources. Individual BW
components represented by dierent icons:
RSD1
Characteristic maintenance, For issues like InfoObjects
cannot be activated, you can use this tcode to activate the
infoObjects again to reproduce the issue.
SAP HANA Troubleshooting and Performance Analysis Guide
Root Causes and Solutions
P U B L I C 87

Tcode Description
RSDDB SAP HANA/BWA index maintenance,
RSLIMOBW Create/modify Composite Provider
RSPC Process Chain Maintenance, can be used to nd the process
chain job logs
RSRQ Data Load Monitor for a Request
RSRT Start of the report monitor, can be used to run Bex queries.
RSRV Analysis and Repair of BW Objects, can be used to check
BW Object consistency.
RSTT RS Trace Tool
RZ11 List ABAP prole parameters
SAINT SAP Add-on Installation Tool
SPAM SAP Patch Manager
SE01 Transport Organizer Tool, for issues related to BW
transports, can be used to nd the related transports and
nd the transport log
SE11 ABAP Dictionary, display the ABAP table/view denition,
can be used to nd the primary index denition as well
SE14 ABAP Dictionary Database Utility, can be used to check if
ABAP table exist on DB level, recreate table etc.
SE16 Display content of an ABAP table/view
SE38 ABAP Editor, can be used to display/run ABAP programs. If
only need to run the ABAP program, can use SA38 instead.
Useful ABAP program:
● RSDU_TABLE_CONSISTENCY
● RSDDB_LOGINDEX_CREATE
● RSDDB_MASS_INDEX_CREATE
● RS_BW_POST_MIGRATION
● RS2HANA_AUTH_RUN
● RSPFPAR – Display prole parameter
● ADBC_TEST_CONNECTION -- test if the DB connection
works
● RSDU_EXEC_SQL – if SQL editor is not available
through DBACOCKPIT
● RSBDCOS0 -- run an OS command
88 P U B L I C
SAP HANA Troubleshooting and Performance Analysis Guide
Root Causes and Solutions

Tcode Description
● RSTRC000 – lock a SAP work process for yourself, and
increase work process trace level
SLG1 Analyze Application log. It is useful to get the logs and
timestamps for errors on application side
SM04 Display all the current ABAP user sessions
SM12 Display and Delete Locks on ABAP level
SM21 Online System Log Analysis
SM37 Overview of BW scheduled jobs, for a failed job, you can
view the job log and from the job details you will be able to
nd which work process has been used to run the job.
SM50 Work Process Overview
SM51 List of SAP Systems, it’s useful to switch to dierent
application servers
SM59 RFC Destinations (Display/Maintain)
SM66 Global work process Monitor, list all the active work
processes on the system
SNOTE Check if SAP Note being implemented on the system or not
ST05 Enable SQL trace, which will help you to tell which query
cause the long running time.
ST06 Operating System Monitor
ST11 Check work process log
ST03 Work load monitor
ST04 DBACOCKPIT-> DB overview
ST12 Single Transaction analysis, only available if the SAP
ServiceTools has been installed(component ST-A/PI. SAP
Note 69455). It’s a combination of the standard
ABAP(SE30) and SQL trace(ST05) see SAP Note 755977
for step-by-step instructions
ST22 ABAP Runtime Error
SU01 User maintenance, display/Modify BW users
SAP HANA Troubleshooting and Performance Analysis Guide
Root Causes and Solutions
P U B L I C 89

3.10 Troubleshooting Multi-Dimensional Services Queries
This section describes how to execute, capture and analyze InA queries for SAP Analytics Cloud HANA Multi-
Dimensional Service.
Introduction
SAP Analytics Cloud’s query language is called InA (Information Access). InA queries are executed using HANA
Multi-Dimensional Service and the result set is returned to SAC front-end for rendering.
InA queries are expressed in JSON which is not designed for human consumption but it is a text format which
can at least be read by humans. To analyze an InA query for troubleshooting purposes you can record the query
execution using the browser’s development tools and save the query as a le. You can then execute the query in
isolation using the EXECUTE_MDS procedure call and analyze the execution plan using visualization tools.
A similar approach can be used for other applications such as Analysis Oce and Lumira Designer, but in these
cases the third-party tool Fiddler is required.
This section describes how to execute, capture and analyze InA queries in this way and includes an overview of
using Fiddler for Analysis Oce:
● How to capture InA queries
● How to execute InA queries and visualize the execution plan
● How to execute multiple InA queries in parallel
● Debugging Analysis Oce InA queries
More Information
For a general introduction to MDS and frequently-asked questions which may also help with troubleshooting,
refer to the SAP Note 2670064 - FAQ: SAP HANA Multi-Dimensional Services (MDS). For details of diagnosis
data required by SAP Support refer to SAP Note 2691501 - SAP HANA MDS: Information needed by
Development Support.
Other SAP Notes related to MDS include:
● 2550833 - HANA built-in procedure: EXECUTE_MDS
● 2773755 - Guideline for Controlling Server Load with InA/MDS Analytic Requests
How to Capture InA Queries
You can capture InA queries issued by SAC using the browser’s development tools, the following steps and
examples are illustrated using Google Chrome.
1. Start the Chrome debugging tool by one of the following methods:
○ From the Customize and Control Google menu, choose More tools Developer tools (shortcut key
Ctrl+Shift+I).
90
P U B L I C
SAP HANA Troubleshooting and Performance Analysis Guide
Root Causes and Solutions

○ From the menu bar select View Developer Developer tools (shortcut key F12).
2. From the panel and console which is opened select the Network tab.
3. Navigate to the problematic page in SAC and when the debug screen has loaded lter for GetResponse as
shown here:
To save the network capture:
1. Look for the Record button on the toolbar of the Network tab. It should be red. If it is gray, click it once to
start recording.
2. Check the Preserve log checkbox on the toolbar.
3. Click the Clear button to clear out any existing logs from the Network tab.
4. Now try to reproduce the issue that you want to analyze while the network requests are being recorded.
5. Once you have reproduced the issue, right click on a grid line with gray background on the grid of network
requests and select Save as HAR with Content, and save the le to your computer. This HAR le can be
reopened to analyze and replay the InA queries within.
SAP HANA Troubleshooting and Performance Analysis Guide
Root Causes and Solutions
P U B L I C 91

How to Execute and Visualize InA Queries
InA queries can be individually executed as described here. To execute an InA query the SAC user must have
the role INA_ROLE. If the customer is using a technical user to execute InA queries, then the role must also be
assigned to the user who wants to troubleshoot the issue.
1. Open the SQL Console in Web IDE (or any other console such as SAP HANA studio).
2. Call built-in stored procedure SYS.EXECUTE_MDS with the InA query that was previously captured as the
REQUEST parameter. Both REQUEST and RESPONSE are in JSON format (data type NCLOB):
CALL SYS.EXECUTE_MDS('Analytics'
,''
,''
,''
,''
,REQUEST=>'{"Analytics"…'
,RESPONSE=>?);
It is possible to render the RESPONSE into a tabular format, but it is not needed for performance analysis.
1. You can now visualize the execution plan of an InA query by invoking the menu actions shown below:
92
P U B L I C
SAP HANA Troubleshooting and Performance Analysis Guide
Root Causes and Solutions

The result of visualization depends on the query, but it resembles a SQL query visualization plan as shown
below:
The execution of each step of the plan is identied in this graph. If Execute Model is expanded, it will eventually
lead to column store operations that are used to fetch the data from source tables. This method can be used to
evaluate the performance of model with respect to the InA queries issued by SAC.
If most of the time is spent in Process Cube and/or Prepare Query, then it is possible that the bottleneck is in
MDS engine (see Troubleshooting Tips for the Calculation Engine). But if most of the execution time is spent in
Execute Model, then the bottleneck is most probably in the way the model is designed.
The use of workload classes to apply workload settings for your application may be one way of improving
performance. If, for example, a single execution of a query in isolation does not take a lot of resources, but there
is a degradation in performance in a production environment where many queries are executed
simultaneously, a workload class and mapping could be used to manage the allocation of resources. This could,
for example, apply a higher priority to the query or apply resource limitations on other queries.
How to Execute Multiple InA Queries in Parallel
SAC stories contain visualizations and each visualization requires at least one InA query. The InA queries in a
story are executed in parallel which will cause more load on a customer’s HANA machine and which may lead
to performance degradation.
SAP HANA Troubleshooting and Performance Analysis Guide
Root Causes and Solutions
P U B L I C 93

Customers can test their HANA machine and the model’s performance by opening multiple connections and
executing multiple InA queries at once using the EXECUTE_MDS procedure explained above.
Analysis Oce InA Queries
A similar approach to that described above for SAC can be used to collect InA queries for Analysis Oce and
Lumira Designer using Fiddler; Fiddler is a freely-available third-party troubleshooting tool that can trace web
trac activity. Once Fiddler is installed you can open the application where the issue occurs and reproduce the
problem. The query and response are then visible and, if necessary, you can save these and send them to SAP
Support for analysis. Refer to the following SAP Notes for more details:
● How to download, install and run Fiddler is described in SAP Note 1766704 How to use Fiddler to collect
HTTP and HTTPS traces.
● Details of the procedure to extract the query can be found in SAP Note 2839059 How To Extract Ina Json
Query and Response from Fiddler Traces.
Related Information
SAP Note 2691501
SAP Note 2550833
SAP Note 1766704
SAP Note 2839059
SAP Note 2773755
Troubleshooting Tips for the Calculation Engine [page 94]
3.11 Troubleshooting Tips for the Calculation Engine
This section gives details of potential problems related to the Calculation Engine and includes tips on modeling.
Calculation Views
The calculation engine is the common execution runtime for various design-time objects such as calculation
views, some SQL Script procedures, MDX queries, analytic InA queries and planning operations. It was
designed to improve performance and to support multi-dimensional reporting. Artifacts of these various
programming models are translated into a common representation called a calculation model which can then
be instantiated, optimized and executed by the calculation engine.
This functional area is in transition as graphical view modeling in HANA repository is replaced by native HANA
models in the new HANA Deployment Infrastructure (HDI) using the modeler in SAP Web IDE. Old repository
94
P U B L I C
SAP HANA Troubleshooting and Performance Analysis Guide
Root Causes and Solutions
artifacts attribute views and analytic views are deprecated and should be replaced by graphical calculation
views.
These transitions can lead to modeling incompatibilities and although the modeler and the calculation engine
provide settings, options and hints to steer the generation process, it is possible that results returned from a
query on a calculation view may not be as expected.
In general, native HANA modeling can be used to model complex OLAP business logic and it provides various
options to tune performance by, for example, helping to achieve complete unfolding of the query by the
calculation engine or modeling join cardinalities between two tables (that is, the number of matching entries
(1...n) between the tables) and optimizing join columns. For more information about modeling refer to the SAP
HANA Modeling Guide for SAP HANA XS Advanced.
Web IDE Performance (Deployment)
If performance is slow when building a calculation view in Web IDE you should review the structure of the
model. One possible cause of long build times is a large number of dependent hierarchy views. In general, try to
reduce the number of views that are based on the calculation view that you want to build.
For more information, refer to SAP Note 2821857 - Long build times in Web IDE due to many dependent
hierarchy views
Query Performance
For graphical calculation views where every node can be translated into SQL, you can use the advanced
modeler execution option Execute in SQL Engine to enforce execution by the SQL engine. This takes advantage
of improved optimization and should give better performance. You can then use the performance query
analysis tools (Explain Plan and Visualize Plan) to verify the performance benet.
For more information, refer to SAP Note 2223597 - Implicit SQL optimization of SAP HANA Calculation Views
If the model is designed to take advantage of union-pruning but the expected benets are not observed, this
may be due to the use of rank nodes in the hierarchy. For more information, refer to SAP Note 2752070 - Union-
pruning does not occur when placed below a rank node in a calculation scenario.
Unexpected Results (general):
The following SAP Notes all relate to unexpected query results:
● When mixing SQL and calculation view functionality, refer to SAP Note 2618790 - graphical view modeling
in SAP HANA - how to avoid unexpected results
● For modeling tips to avoid an empty result set, refer to SAP Note 1764662 - Select on a calculated attribute
returns empty result
● For details of graphical calculation models using the 'Execute in SQL Engine' property, refer to:
○ SAP Note 1857202 - SQL Execution of calculation views
SAP HANA Troubleshooting and Performance Analysis Guide
Root Causes and Solutions
P U B L I C 95

○ SAP Note 2491564 - Dierent Results When Switching the Execution Engine From or to SQL
Optimization
● When using graphical calculation views which cannot be expressed as relational SQL operations, the
requested columns on the calculation view can change because the SQL optimizer itself may determine
which columns to use, therefore returning correct, but unexpected, results. Refer to SAP Note 1958063 -
Unexpected results when mixing complex SQL functionalities with queries on Calculation Views
● For problems related to using input variables (where no default value has been dened) refer to SAP Note
2525644 - Input Variables are set to an Empty String When not Mapped in Top-Level Calculation Scenario.
Unexpected Results (HDI deployed calculation views):
For models that have been migrated from repository modeling to HDI modeling, you may be able to achieve
complete backwards compatibility by using the eld "XSC Compatibility Mode" which is available under the
Advanced View Properties of migrated views. For more details refer to the following SAP Notes:
● SAP Note 2647957 - Changes to Default Node behavior of old repository Calculation Views in HDI
Calculation Views that are relevant in reporting scenarios.
● SAP Note 2465027 - Deprecation of SAP HANA extended application services, classic model and SAP
HANA Repository.
● SAP Note 2396214 - Transition to SAP HANA Extended Services Advanced and SAP HANA Cockpit - Fading
out XS Classic and HANA Studio.
Related Information
SAP Note 2821857
SAP Note 2223597
SAP Note 2752070
SAP Note 2618790
SAP Note 1764662
SAP Note 1857202
SAP Note 2491564
SAP Note 1958063
SAP Note 2525644
SAP Note 2647957
SAP Note 2465027
SAP Note 2396214
Tracing for Calculation View Queries [page 223]
SAP HANA Modeling Guide for SAP HANA XS Advanced
Native HANA Models [page 97]
96
P U B L I C
SAP HANA Troubleshooting and Performance Analysis Guide
Root Causes and Solutions

3.11.1 Native HANA Models
Creating native HANA models can be one way to improve performance compared to development options
outside of the database, or in some cases also compared to pure SQL development.
Native HANA models can be developed in the new XS Advanced (XSA) development environment using SAP
Web IDE for SAP HANA. These models supersede older artifacts like Analytic and Attribute Views; these views
should now be replaced by graphical Calculation Views which can be used to model complex OLAP business
logic. Native HANA modeling provides various options to tune performance by, for example, helping to achieve
complete unfolding of the query by the calculation engine or modeling join cardinalities between two tables
(that is, the number of matching entries (1...n) between the tables) and optimizing join columns.
For more information about modeling graphical calculation views refer to the SAP HANA Modeling Guide for
SAP HANA XS Advanced.
A number of blogs are available about the details of modeling:
● https://blogs.sap.com/2017/09/01/overview-of-migration-of-sap-hana-graphical-view-models-into-the-
new-xsa-development-environment/ Overview: Migration of Models into the XSA Development
Environment
● https://blogs.sap.com/2017/10/27/join-cardinality-setting-in-calculation-views/ Join cardinality setting
in Calculation Views
● https://blogs.sap.com/2018/08/10/optimize-join-columns-ag/ Optimize Join Columns Flag
The following SAP Notes provide further background information:
● https://launchpad.support.sap.com/#/notes/2441054 2441054 - High query compilation times and
absence of plan cache entries for queries against calculation views.
● https://launchpad.support.sap.com/#/notes/2465027 2465027 - Deprecation of SAP HANA extended
application services, classic model and SAP HANA Repository.
Related Information
SAP HANA Modeling Guide for XS Advanced Model
3.12 License Issues
This section covers license-related issues.
Related Information
System Locked Due to Missing, Expired, or Invalid License [page 98]
License Problem Identication and Analysis [page 98]
SAP HANA Troubleshooting and Performance Analysis Guide
Root Causes and Solutions
P U B L I C 97

Resolution of License Issues [page 99]
3.12.1 System Locked Due to Missing, Expired, or Invalid
License
New installations of SAP HANA are equipped with a temporary license that expires after 90 days. To keep the
system functional after this period, you have to install a permanent license.
Improper licensing may lead to a lockdown of your SAP HANA system. In this case, the only allowed action is to
install a valid license.
The system goes into lockdown in the following situations:
● The permanent license key has expired and either:
○ You did not renew the subsequently installed temporary license key within 28 days, or
○ You did renew the subsequently installed temporary license key but the hardware key has changed
● The installed license key is an enforced license key and the current memory consumption exceeds the
licensed amount plus the tolerance.
● You deleted all license keys installed in your database.
For more information, see Managing SAP HANA Licenses in the SAP HANA Administration Guide.
Related Information
Managing SAP HANA Licenses
3.12.2 License Problem Identication and Analysis
The rst signs of problems related to licensing will be visible by Alert 31 or Alert 44 being issued.
You can check your current license using the SAP HANA cockpit: Choose the Manage system licenses link on
the Overview page.
Alternatively, you can retrieve the same information using SQL:
SELECT * FROM M_LICENSE;
Note
To be able to query license information, you must have the system privilege LICENSE ADMIN.
The M_LICENSE system view includes the following information:
● License data:
○ SID
98
P U B L I C
SAP HANA Troubleshooting and Performance Analysis Guide
Root Causes and Solutions

○ Hardware key
○ Installation number
○ System number
○ Product limit (licensed amount of memory)
○ Validity start date
○ Expiration date - See SAP Note 1899480 - How to handle HANA Alert 31: 'License expiry'
○ Last successful check date
● License status (permanent, valid, enforced, local) See SAP Note 1899511 - How to handle HANA Alert 44:
'Licensed Memory Usage'
Note that in case of system lockdown, only SID and hardware key are displayed. Information on previously
installed licenses is available.
SAP HANA licenses can be installed for the system database (global) or for a single tenant database (local).
Global licenses are for the system database and all tenants but a license installed in a tenant will govern only
the tenant. If the license is installed incorrectly at the local level you can remove the tenant-specic license key
to revert the license validity to the global license key installed in the system database.
Related Information
M_LICENSE System View
SAP Note 1899480
SAP Note 1899511
3.12.3 Resolution of License Issues
If your license becomes invalid, you need to install a new license.
You can install a new license either in the SAP HANA cockpit or using SQL.
Note
To install a license key, you need the LICENSE ADMIN system privilege.
You install a license key with the following SQL statement:
SET SYSTEM LICENSE '<license file content goes here, line breaks matter>';
Note
Line breaks are essential for interpretation of the license key text, hence they must not be removed. If you
use the command line tool SAP HANA HDBSQL to install the license, make sure to enable multi-line
statement support (command line option -m or \mu ON when within SAP HANA HDBSQL).
SAP HANA Troubleshooting and Performance Analysis Guide
Root Causes and Solutions
P U B L I C 99

The command will fail if the license key has a dierent installation number or system number than the current
ones in the database instance. If you have successfully installed a license but your system is still locked down,
check the following:
● The current system time is within the validity period of the license.
● Your installed license key is correct, in particular, the M_LICENSE view displays only one row with a valid
license for the product SAP HANA.
● The SAP Notes in the Related Links section.
For more detailed information about how to install a license key, see the SAP HANA Administration Guide.
Related Information
SAP Note 1704499
SAP Note 1634687
SAP Note 1699111
Managing SAP HANA Licenses
Run Long Commands in Multiple-Line Mode
3.13 Security-Related Issues
This section looks at issues related to authorization and authentication.
Related Information
Troubleshooting Authorization Problems [page 101]
Troubleshooting Problems with User Name/Password Authentication [page 106]
Troubleshooting Problems with User Authentication and SSO [page 108]
100
P U B L I C
SAP HANA Troubleshooting and Performance Analysis Guide
Root Causes and Solutions

3.13.1 Troubleshooting Authorization Problems
SAP HANA implements its authorization concept based on the entities user, privilege, and role.
General Analysis
The system view EFFECTIVE_PRIVILEGES is useful for checking the privileges of a specic user. It includes
information about all privileges granted to a specic user (both directly and indirectly through roles), as well as
how the privileges were obtained (GRANTOR and GRANTOR_TYPE column).
Output of Eective Privileges
For more information about using this view and other system views related to authorization, see System Views
for Verifying Users' Authorization.
For more information about the authorization concept in SAP HANA, see the SAP HANA Security Guide.
Related Information
System Views for Verifying Users' Authorization
EFFECTIVE_PRIVILEGES System View
SAP HANA Security Guide
SAP HANA Troubleshooting and Performance Analysis Guide
Root Causes and Solutions
P U B L I C 101

3.13.1.1 Display Information about an "Insucient Privilege"
Error
If an Insufficient privilege occurs, you can nd out more information about the missing privilege by
using the associated GUID.
Prerequisites
To identify the missing privilege using a GUID, you need execute privilege for the following procedure:
SYS.GET_INSUFFICIENT_PRIVILEGE_ERROR_DETAILS('<GUID>', ?)
Context
If you encounter the error Insufficient privilege, you should inform the system administrator. The
system administrator rst needs to nd out which privilege is needed by the user executing the statement.
Then, the system administrator can decide whether the missing privilege should be assigned to the user.
Procedure
1. Make a note of the GUID shown in the error message.
The following is an example of an error message:
insufficient privilege: Detailed info for this error can be found with guid
'3DFFF7D0CA291F4CA69B327067947BEE'
2. In SAP HANA cockpit, open the system with the missing privilege, and go to the System Overview.
3. In the Insucient Privilege Details, specify the GUID and choose Enter.
The missing privilege is displayed with the session user name and the checked user name. Optionally the
object name, schema name, and object type are displayed.
If the missing privilege is contained in one or more roles, the roles are displayed.
Note
If the missing privilege is an analytical privilege, neither the name of the privilege nor any roles can be
displayed.
For more information, see Resolve Insucient Privilege Errors in the SAP HANA Administration Guide
(Security Administration and User Management).
4. Decide whether to assign the missing privilege or a role to the user.
102
P U B L I C
SAP HANA Troubleshooting and Performance Analysis Guide
Root Causes and Solutions

Option Description
To assign the missing privilege to the user... Choose Assign Privilege....
You are prompted to select the privilege, and assign it us
ing the privilege editor.
To assign a role containing the missing privilege... Choose Assign Role.
This function is only available if the current user is able to
grant the role to the specied user.
Related Information
Congure Tracing in the SAP HANA Database Explorer
View Diagnostic Files in the SAP HANA Database Explorer
SAP HANA Administration Guide
Resolve Insucient Privilege Errors
3.13.1.2 Troubleshoot the Display of Unrestricted or Incorrect
Results for a View Secured with Analytic Privileges
If a user has unrestricted access to a view or sees results that he should not, even though he has been granted
an analytic privilege, you need to determine which privileges have been granted to the user and whether or not
they are correct.
Prerequisites
To troubleshoot this issue, you require the following system privileges:
● CATALOG READ
● TRACE ADMIN
Procedure
● Check which analytic privileges have been granted to the user using the system view
EFFECTIVE_PRIVILEGES.
Execute the following SQL statement:
SELECT * FROM EFFECTIVE_PRIVILEGES WHERE USER_NAME = 'myuser' AND OBJECT_TYPE
= 'ANALYTICALPRIVILEGE';
SAP HANA Troubleshooting and Performance Analysis Guide
Root Causes and Solutions
P U B L I C 103

In particular, verify that the user does not have the analytic privilege _SYS_BI_CP_ALL. This analytic
privilege potentially allows a user to access all the data in all activated views, regardless of any other
analytic privileges that apply. Usually, the user will have this analytic privilege through a role, for example,
MODELING.
Caution
The MODELING role is very privileged and should not be granted to users, particularly in production
systems. The MODELING role should only be used as a template.
● Identify wrong lters specied in the analytic privileges granted to the user.
Information about lter conditions generated from the relevant analytic privileges can be traced in the
indexserver trace le. This can help you to identify wrong lters specied in the analytic privileges granted
to the user.
In the Trace Conguration monitor of the SAP HANA database explorer, set the database trace level for the
component analyticprivilegehandler of the indexserver service to DEBUG.
Related Information
EFFECTIVE_PRIVILEGES System View
System Views for Verifying Users' Authorization
3.13.1.3 Troubleshoot the Error "Insucient privilege: Not
authorized" Although User Has Analytic Privileges
Even if a user has the correct analytic privileges for a view, he still may receive the error Insufficient
privilege: Not authorized if there is an issue with privileges at another level.
Prerequisites
To troubleshoot this issue, you require the following system privileges:
● CATALOG READ
● TRACE ADMIN
Procedure
● Verify that the _SYS_REPO user has all required privileges (for example, SELECT) with GRANT OPTION on
the base tables of the view.
104
P U B L I C
SAP HANA Troubleshooting and Performance Analysis Guide
Root Causes and Solutions

You can do this by selecting from the EFFECTIVE_PRIVILEGES system view:
SELECT * FROM EFFECTIVE_PRIVILEGES WHERE USER_NAME = '_SYS_REPO';
● Verify that the analytic privileges required for any underlying views have been granted to the user.
If the view is a top-level view (calculation view) with underlying views, the granted analytic privilege grants
access only to this top-level view. Analytic privileges are required for all underlying views. Note that analytic
privileges have to contain at least a view attribute with or without lter condition in order to grant access to
the view.
You can verify a user's privileges by selecting from the EFFECTIVE_PRIVILEGES system view:
SELECT * FROM EFFECTIVE_PRIVILEGES WHERE USER_NAME = '<user>' AND OBJECT_TYPE
= 'ANALYTICALPRIVILEGE';
● If the analytic privilege uses a database procedure to dene dynamic value lters at runtime, check for
errors in the execution of the underlying procedure.
To nd out the actual error during procedure execution for analytical privileges, check the
indexserver_alert_<host>.trc trace le (accessible in the SAP HANA database explorer via the View
trace and diagnostic les link in the SAP HANA cockpit).
3.13.1.4 Troubleshoot the Error "Invalidated View" During
SELECT Statement Execution
A user may receive the error Invalidated view when executing a SELECT statement against a view that was
activated from the repository. In addition, the data preview for an activated view does not show any data.
Prerequisites
To troubleshoot this issue, you require the following system privileges CATALOG READ.
Procedure
● Verify that the _SYS_REPO user has all required privileges (for example, SELECT) on all base objects (for
example, tables) of the view.
You can do this by selecting from the EFFECTIVE_PRIVILEGES system view:
SELECT * FROM EFFECTIVE_PRIVILEGES WHERE USER_NAME = '_SYS_REPO';
SAP HANA Troubleshooting and Performance Analysis Guide
Root Causes and Solutions
P U B L I C 105

3.13.2 Troubleshooting Problems with User Name/Password
Authentication
Common problems with regards to authentication are related to incorrect or expired passwords.
User administrators can change users' passwords on the Edit User monitor in the Cockpit Manager of the SAP
HANA cockpit.
For more information about managing users, see Security Administration and User Management and Reset the
SYSTEM User Password of a Tenant Database in the SAP HANA Administration Guide.
Related Information
Security Administration and User Management
Reset the SYSTEM User Password in a Tenant Database
3.13.2.1 Resetting the Password for the SYSTEM User
If the password of the SYSTEM user is irretrievably lost, it can be reset.
Follow the procedure as described in the SAP HANA Administration Guide.
Note
If you can log on as SYSTEM and you want to change the password, do not use the emergency reset
procedure. Simply change the password directly using the SAP HANA cockpit or the ALTER USER SQL
statement: ALTER USER SYSTEM PASSWORD new_password.
Related Information
Resetting the SYSTEM User Password
106
P U B L I C
SAP HANA Troubleshooting and Performance Analysis Guide
Root Causes and Solutions

3.13.2.2 Troubleshoot the Error "User is locked"
A user receives the error User is locked after too many failed log on attempts.
Prerequisites
You have system privilege USER ADMIN.
Context
An example of this error might look like:
Error "user is locked; try again later: lock time is 1440 minutes; user is locked
until 2014-05-28 21:42:24.12214212" (the time is given in UTC).
Most likely, the user logged on too many times with the wrong password. The default maximum number of
failed logon attempts is 6. This is dened by the password policy parameter
maximum_invalid_connect_attempts.
For more information about this and other password policy parameters, see Password Policy Conguration
Options in the SAP HANA Security Guide.
Procedure
Reset the invalid connect attempts with the following SQL statement:
ALTER USER <user> RESET CONNECT ATTEMPTS;
The user can now log on again.
Related Information
Password Policy Conguration Options
SAP HANA Troubleshooting and Performance Analysis Guide
Root Causes and Solutions
P U B L I C 107

3.13.3 Troubleshooting Problems with User Authentication
and SSO
Authentication problems manifest themselves as failed user logon. In many cases, the reason for the failure will
not be clear to the user. You need to analyze the database trace to determine the cause of the problem.
For security reasons, no information about error conditions are provided to a user directly after a failed logon
attempt, since this could be abused by attackers. In case of authentication problems, the aected user must
contact the system administrator, who will then analyze the database trace on the server side.
Tracing for SSO Issues
Logon information is available in the database trace, but by default, it does not log much. The rst step in
troubleshooting any SSO logon issue therefore is to increase the trace level of the authentication-related
components of the database trace. You can do this in the SAP HANA cockpit.
For problems with JDBC/ODBC-based logon, increase the trace level of the authentication for the index
sever to DEBUG.
For problems with HTTP-based logon via SAP HANA XS classic, increase the trace level of the
authentication, xssession, and xsauthentication components for the xsengine server to DEBUG.
Once you have increased tracing, reproduce the problematic logon. The traces will now contain more
descriptive error messages.
Remember
After completing troubleshooting, reduce the authentication trace level back to the default.
In some cases, especially for Kerberos and SPNEGO, it is necessary to use other sources of tracing, such as:
● JDBC, ODBC or SQLDB trace
● Windows event log
● Debugger of browser
● SAP Web dispatcher trace
● Network packet snier, for example, Wireshark
For more information about tracing in SAP HANA see the section on traces in the SAP HANA Administration
Guide and SAP Note 2119087.
Tip
Guided Answers is a support tool for troubleshooting problems using decision trees. A guided answer is
available for tracing SSO issues.
Related Information
Traces
Single Sign-On Integration
Kerberos-Related Authentication Issues [page 109]
108
P U B L I C
SAP HANA Troubleshooting and Performance Analysis Guide
Root Causes and Solutions

SAML Authentication [page 110]
Traces for SSO Troubleshooting (Guided Answer)
SAP Note 2119087
3.13.3.1 Kerberos-Related Authentication Issues
GSS API Errors
Kerberos authentication is implemented in the SAP HANA database using the Generic Security Services
Application Program Interface (GSS API). Since GSS API is an internet standard (RFC 4121), all Kerberos-
related errors are traced under the authentication trace component in the following generic way:
<SAP HANA DB error text> (<GSS major code>.<GSS minor code> - <GSS major text> <GSS
minor text>)
GSS API error texts are sometimes dicult to relate to the concrete problem. The following table contains
some hints for selected trace messages.
GSS API Error
Code Error Text Hint Solution
851968.252963
9142
Minor error text: Key version
number for principal
in key table is
incorrect
The service key table (keytab) in
use on the SAP HANA database
host does not match the one cre
ated on authentication server.
Re-export the keytab le from the
authentication server and re-im
port it into the host’s Kerberos in
stallation.
851968.397560
33
SAP HANA database error text:
Cannot get keytab
entry for host: <FQDN>
Minor error text: No
principal in keytab
matches desired name
Keytab actually used might be dif
ferent than expected
(default: /etc/krb5.keytab).
Check environment variable
KRB5_KTNAME.
851968.252963
9136
SAP HANA database error text:
Cannot get keytab
entry for host: <FQDN>
Minor error text:
Configuration file
does not specify
default realm
Kerberos conguration le ac
tually used might be dierent
than expected (default: /etc/
krb5.conf).
Check environment variable
KRB5_CONFIG.
Conguration
There are many potential problems setting up a Kerberos infrastructure that are not related to the SAP HANA
system in particular, but relevant for any Kerberos-based authentication. For further information, refer to the
documentation provided with MIT Kerberos or Microsoft Server/Active Directory.
SAP HANA Troubleshooting and Performance Analysis Guide
Root Causes and Solutions
P U B L I C 109

Useful SAP Notes
SAP Note Description
1837331
HOWTO HANA DB SSO Kerberos/ Active Directory
2354473
SSO troubleshooting for HANA and Analysis Oce (SPNEGO)
1813724
HANA SSO/Kerberos: create keytab and validate conf
2354556
Common errors when executing hdbkrbconf.py
Related Information
Single Sign-On Using Kerberos
3.13.3.2 SAML Authentication
User cannot connect with SAML assertion
If a user cannot connect to SAP HANA with a SAML assertion, the issuer and subject distinguished names
(DNs) in the SAML assertion do not match those congured in the identity provider. Investigate which issuer
and subject DNs were used in the SAML assertion. You will nd them in the trace le
indexserver_alert_<hostname>.trc. Compare these with those congured in the service provider.
Useful SAP Notes
SAP Note
Description
1766704
How to use Fiddler to collect HTTP and HTTPS traces
2284620
HOW-TO HANA DB SSO SAML and BI Platform 4.1 / AO 2.2
Tip
Guided Answers is a support tool for troubleshooting problems using decision trees. A guided answer is
available for SAML authentication with SAP HANA.
Related Information
Single Sign-On Using SAML 2.0
SAML Authentication for Single Sign-On (Guided Answer)
110
P U B L I C
SAP HANA Troubleshooting and Performance Analysis Guide
Root Causes and Solutions

3.14 Transactional Problems
This section covers troubleshooting of transaction problems. Symptoms seen from an end user perspective
may include an application running sluggishly, or not responding or even seeming to hang. These problems
may be caused by issues with uncommitted transactions, long-lived cursors blocking garbage collection, a high
number of active versions or blocked transactions.
Maximum Transaction Limit
The default system limit for the maximum number of transactions is 64000. If this limit is exceeded, an SQL
error message may be returned when submitting queries: "exceed maximum number of transactions". This
may be caused by application programs which are not correctly managing connections/transactions, or a bug
within the database engine. This scenario and possible workarounds are described in detail in SAP Note
2368981 - SAP HANA DB: Queries fail with error "exceed maximum number of transaction".
Related Information
SAP Note 2368981
3.14.1 Blocked Transactions
Blocked transactions are write transactions that are unable to be further processed because they need to
acquire transactional locks (record or table locks) which are currently held by another write transaction. Note
that transactions can also be blocked waiting for physical resources like network or disk. Those situations are
not covered in this section.
3.14.1.1 Identify and Assess Blocked Transaction Issues
The rst signs of blocked transactions are poor application response or alerts 49 or 59 are raised.
The initial indicators of blocked transactions are given by:
● Users reporting bad application responsiveness
● Alert 49 - Long-running blocking situations
● Alert 59 - Percentage of transactions blocked
SAP HANA Troubleshooting and Performance Analysis Guide
Root Causes and Solutions
P U B L I C 111
To conrm the database performance is harmed by blocked transactions, you should check the following SAP
HANA cockpit monitors:
Performance Monitor
The Blocked Transactions graph shows how many blocked transactions currently exist and existed in the past
to a certain extent.
Workload Analysis Monitor
To further track down the issue, look at the Background Jobs tab in the Workload Analysis monitor. It shows
currently running SAP HANA background processes like Delta Merge. Since the Delta Merge needs to lock
tables to proceed, it is a common cause for blocked transactions. Another job display by this monitor is the
savepoint write which needs to pull a global database lock in its critical phase. See Savepoint Performance.
Sessions Monitor
The Sessions monitor lists all currently opened SQL sessions (meaning user connections). In the context of
blocked transaction troubleshooting, the columns Blocked By Connection ID and Blocks No. Of Transactions are
of special interest. The rst tells you whether the session is blocked by another session and identies the ID of
the blocking one. The latter gives you the corresponding information if a session blocks other sessions, and
how many transactions are aected. See Session Monitoring.
112
P U B L I C
SAP HANA Troubleshooting and Performance Analysis Guide
Root Causes and Solutions

Blocked Transactions Monitor
The Blocked Transactions monitor is the next drill down step. It only lists those transactions that are currently
blocked. The ordering is done via a blocking/blocked relation. That means transactions that are blockers are
highlighted. Directly beneath the blocked transactions are displayed:
Blocked Transactions Monitor
In the gure above, you see transaction 46 blocking multiple other transactions. See Blocked Transaction
Monitoring.
Threads Monitor
The Threads monitor allows the most ne-grained view into the current situation by listing all threads in the
system. Note that it is usually not necessary to drill into that level of detail. See Thread Monitoring.
SAP HANA Troubleshooting and Performance Analysis Guide
Root Causes and Solutions
P U B L I C 113

Related Information
Load Monitoring [page 180]
Job Progress Monitoring [page 179]
Savepoint Performance [page 59]
Session Monitoring [page 178]
Blocked Transaction Monitoring [page 177]
Thread Monitoring [page 174]
SAP Note 2079396
SAP Note 2081856
3.14.1.2 Troubleshooting Blocked Transactions
When troubleshooting blocked transactions, it is helpful to dierentiate between situations where only single or
a few transactions are blocked from the situation where a high percentage of all transactions is blocked.
3.14.1.2.1 Single or Few Transactions are Blocked
If you identied only a single or a few blocking transactions, there is likely an issue on application side.
A usual pattern is a aw in the application coding that does not commit a write transaction. Such a transaction
will be a blocker for any other transaction that needs to access the same database object. To release the
situation you have to close the blocking transaction.
There are several possibilities to achieve this:
● Contact the Application User
You can identify the user of the application via the Sessions tile. This information is visible in the “Database
User” column or, in case the application has its own user management (for example, SAP BW), in the
“Application User” column. Contact the user and ask him whether he can close the application.
● Contact the Application Developer
As a follow-up, the author of the application should be contacted and asked whether such situations can be
avoided in the future by changing the application code.
3.14.1.2.1.1 Cancel the Session
If you are not able to contact the user to have them cancel the session, you can also cancel the session from
the list of sessions accessed via the Sessions tile. The current transaction will be rolled back.
The session cancellation may take some time to succeed.
114
P U B L I C
SAP HANA Troubleshooting and Performance Analysis Guide
Root Causes and Solutions
3.14.1.2.1.2 Kill the Client Application
In case the session cancellation takes too long or does not complete at all, you can kill the client process that
opened the session. This will terminate the blocking transaction as well.
As a prerequisite, you have to have access to the client machine. The information needed for this task can be
retrieved from the Sessions tile.
See columns “Client IP” and “Client Process ID” to determine the host and process to be killed. Note that killing
the client application is safe from a database consistency standpoint, the current transaction will be rolled back
gracefully.
3.14.1.2.2 Many Transactions are Blocked
In the case that a large amount of transactions are blocked, the troubleshooting should take a slightly dierent
approach.
First you need to determine whether there is a single or few blocking transactions that block a large amount of
other transactions. For this, open the Blocked Transactions monitor and check the amount of blocking
transactions. If you assess there are only a few blocking transactions, use the techniques described in Single of
Few Transactions are Blocked to resolve the situation.
If there are many transactions in a blocking state, you need to nd out whether a specic access pattern
causes the situation. In case that multiple transactions try to access the same database objects with write
operations, they block each other. To check if this situation exists, open the Blocked Transactions monitor and
analyze the “Waiting Schema Name”, “Waiting Object Name” and “Waiting Record Id” columns. If you nd a fair
amount of blocking transactions that block many other transactions you need to investigate if the following is
possible:
● Change the client applications to avoid the access pattern
● If a background job is running that issues many write transactions (for example, a data load job):
Reschedule to a period with a low user load
● Partition tables that are accessed frequently to avoid clashes. See the SAP HANA Administration Guide for
more details on partitioning.
In case you cannot identify specic transactions or specic database objects that lead to transactions being
blocked, you have to assume a problem with the database itself or its conguration. One example is an issue
with long savepoint durations. See Savepoint Performance for troubleshooting such issues.
Related Information
Single or Few Transactions are Blocked [page 114]
Savepoint Performance [page 59]
SAP HANA Troubleshooting and Performance Analysis Guide
Root Causes and Solutions
P U B L I C 115
3.14.2 Troubleshooting Blocked Transaction Issues that
Occurred in the Past
Finding the root cause of blocked transaction situations that you have resolved is more dicult than
troubleshooting issues that are currently happening. Tools such as the Performance Monitor, system views and
the SQL Plan Cache are available to help you.
First use the Performance Monitor to isolate the exact time frame where the issue happened. Using that
information, investigate what happened at this specic time frame. You should check the following monitoring
and StatisticServer views:
● _SYS_STATISTICS.HOST_BLOCKED_TRANSACTIONS: Analyze the columns “WAITING_SCHEMA_NAME”,
“WAITING_TABLE_NAME” and “WAITING_RECORD_ID” to identify the database objects that lead to
blocked transactions.
● SYS.M_DELTA_MERGE_STATISTICS: The column “START_TIME” and “EXECUTION_TIME” provide you
with the information if there was a Delta Table Merge running. A longer history can be found in the
StatisticServer table _SYS_STATISTICS.HOST_DELTA_MERGE_STATISTICS.
● SYS.SAVEPOINTS: Check if a savepoint was written during the time period. A longer history can be found in
_SYS_STATISTICS.HOST_SAVEPOINTS.
In addition the SAP HANA cockpit SQL Plan Cache monitor may be able to provide information about the
statements that were involved in the situation:
Only check entries that have “TOTAL_LOCK_WAIT_COUNT” > 0. For those entries, compare the column
“MAX_CURSOR_DURATION” against “AVG_CURSOR_DURATION”. If there is a signicant dierence, there was
at least one situation where the transactions took much longer than average. This can be an indication that it
was involved in the situation.
3.14.3 Multiversion Concurrency Control (MVCC) Issues
In this section you will learn how to troubleshoot issues arising from MVCC.
Multiversion Concurrency Control (MVCC) is a concept that ensures transactional data consistency by
isolating transactions that are accessing the same data at the same time.
To do so, multiple versions of a record are kept in parallel. Issues with MVCC are usually caused by a high
number of active versions. Old versions of data records are no longer needed if they are no longer part of a
snapshot that can be seen by any running transaction. These versions are obsolete and need to be removed
from time to time to free up memory.
This process is called Garbage Collection (GC) or Version Consolidation. It can happen that a transaction is
blocking the garbage collection. The consequence is a high number of active versions and that can lead to
system slowdown or out-of-memory issues.
116
P U B L I C
SAP HANA Troubleshooting and Performance Analysis Guide
Root Causes and Solutions

3.14.3.1 Row Store Tables
Garbage collection is triggered after a transaction is committed and also periodically (every hour by default).
A transaction that is currently committing can be identied in the Threads tile (see System Performance
Analysis). The Thread Type will be “SqlExecutor” and the Thread Method “commit”.
The periodic garbage collection can be identied by Thread Type ”MVCCGarbageCollector”.
Note that the periodic garbage collection interval can be congured in the indexserver.ini le transaction
section with the parameter gc_interval.
Related Information
System Performance Analysis [page 174]
3.14.3.2 MVCC Problem Identication
You can check for a number of indicators of MVCC problems.
Problems with a high number of active versions can be identied by
● users reporting an increase of response times
● the indexserver trace containing "There are too many un-collected versions. The transaction blocks the
garbage collection of HANA database."
● checking Active Versions in the Performance Monitor
Transactions blocking garbage collection can originate from:
● Long-running or unclosed cursors
● Long-running transactions with isolation mode “serializable” or ”repeatable read”
● Hanging threads
In order to validate there is a problem with MVCC, check the number of active versions in the Row StoreMVCC
manager monitoring view. Note that in a multihost environment, you have to check the master host.
select * from m_mvcc_tables where host='ld9989' and port='30003' and
(name='NUM_VERSIONS' or name='MAX_VERSIONS_PER_RECORD' or
name='TABLE_ID_OF_MAX_NUM_VERSIONS');
MVCC Information on a Healthy System
If the number of active versions (NUM_VERSIONS) is greater than eight million, it is considered a problem and
an overall slowdown of the system can be experienced. Similarly, if the maximum number of versions per
SAP HANA Troubleshooting and Performance Analysis Guide
Root Causes and Solutions
P U B L I C 117

record (MAX_VERSIONS_PER_RECORD) exceeds 8,000,000, this should be treated as a problem and a
slowdown of accesses to a specic table is expected. Use TABLE_ID_OF_MAX_NUM_VERSIONS and join it
against the SYS.TABLES system view to determine the table which is having the problem.
Related Information
Performance Trace [page 231]
3.14.3.3 Analysis of MVCC Issues
You have to nd out which transactions are blocking the garbage collection and to which connection they are
related.
The following queries will return the transaction that may block the garbage collection. You have to check both.
SELECT top 1 host, port, connection_id, transaction_id, update_transaction_id,
primary_transaction_id, transaction_type, isolation_level FROM M_TRANSACTIONS
WHERE
MIN_MVCC_SNAPSHOT_TIMESTAMP > 0 order by min_mvcc_snapshot_timestamp ASC;
SELECT top 1 host, port, connection_id, transaction_id, update_transaction_id,
primary_transaction_id, transaction_type, isolation_level FROM M_TRANSACTIONS
WHERE
MIN_MVCC_SNAPSHOT_TIMESTAMP = (SELECT MIN(VALUE) FROM M_MVCC_TABLES WHERE NAME =
'MIN_SNAPSHOT_TS') order by min_mvcc_snapshot_timestamp ASC;
User Transaction Possibly Blocking Garbage Collection
In case of a user transaction being the candidate (TRANSACTION_TYPE=’USER TRANSACTION’), you can
directly determine the connection ID the transaction belongs to (see an example in the gure above).
External Transaction Possibly Blocking Garbage Collection
If the candidate’s transaction type is ‘EXTERNAL TRANSACTION’, use the following query to nd out which
other transaction spawned the candidate and determine its connection ID.
SELECT t.connection_id AS "Kill this connection id",
t.transaction_id AS "Belonging to user transaction id",
e.transaction_id AS "To get rid of external transaction id"
FROM m_transactions t
JOIN m_transactions e ON
e.primary_transaction_id = t.transaction_id
AND e.volume_id = t.volume_id
WHERE e.transaction_type = 'EXTERNAL TRANSACTION' and e.transaction_id = <GC
blocker transaction id>;
118
P U B L I C
SAP HANA Troubleshooting and Performance Analysis Guide
Root Causes and Solutions

3.14.3.4 Solution of MVCC Issues
Solving MVCC issues is similar to solving blocked transaction issues. Use the following approaches in the given
order for transactions where you know the connection ID.
1. Contact the user to stop his activity.
2. Cancel the statement/cancel the internal transaction.
3. Cancel the connection.
4. Kill the client application.
Note
There is no guarantee that these measures will stop a transaction which blocks the garbage collection. If
necessary contact development support to get further help.
Related Information
Resolving CPU Related Issues [page 41]
3.14.4 Version Garbage Collection Issues
Alert 75 helps you to identify and resolve version space overow issues.
Context
The following steps allow you to check whether or not the issue you have is related to row store version space
skew, that is, whether the row store version chain is too long. If you use extended storage, a version space
overow may manifest as an out-of-space error for the delta dbspace, and will not trigger this alert. See Out of
Space Errors for Delta Dbspace in SAP HANA Dynamic Tiering: Administration Guide.
Procedure
1. The rst step is to check the alert.
2. Identify the statement and connection blocking garbage collection.
In the SAP HANA database explorer you can use the following set of predened statements to display
details of blocking connections; these are available in the Statement Library:
○ MVCC Blocker Connection shows connections that may be blocking garbage collection.
○ MVCC Blocker Statement shows statements that may be blocking garbage collection.
SAP HANA Troubleshooting and Performance Analysis Guide
Root Causes and Solutions
P U B L I C 119

○ MVCC Blocker Transaction shows transactions that may be blocking garbage collection.
a. Identify the connection or transaction that is blocking version garbage collection.
Run MVCC Blocker Statement to nd out which statement is blocking version garbage collection and
investigate what the blocker is doing. The following table shows a selection of example values which
may be returned by this query followed by some guidance about analyzing the results:
Example Values from MVCC Blocker Statement
Type
IDLE_TIME_SE
C CONNECTION_ID
START_MVCC_TI
MESTAMP
STATE
MENT_STRING INFO
GLOBAL 4000 200285 142113 SELECT * FROM
TEST1
Check VER
SION_COUNT in
M_MVCC_OVERVIEW
TABLE 5000 200375 142024 SELECT * FROM
TEST2 ORDER BY
A
Check VER
SION_COUNT in
M_MVCC_TA
BLE_SNAPSHOTS
TABLE
100 200478 142029 SELECT * FROM
TEST0 ORDER BY
A
Check VER
SION_COUNT in
M_MVCC_TA
BLE_SNAPSHOTS
If the TYPE column is GLOBAL, then it is a global version garbage collection blocker. If there is a global
garbage collection blocker whose idle time (IDLE_TIME_SEC) is greater than 3600 seconds (1 hour),
investigate what the statement is doing and take the necessary corrective action. See row 1 in the
above table.
If the TYPE is TABLE, then it is a blocker of the specic table. This is shown in the second row of the
table above where a table level garbage collection blocker has an idle time greater than 3600 seconds
(1 hour). In this case you can query the M_TABLE_SNAPSHOTS monitoring view to check how many
versions the related table has (in this example TEST2):
SELECT * FROM M_TABLE_SNAPSHOTS WHERE TABLE_NAME = 'TEST2' AND
START_MVCC_TIMESTAMP = 142024
If the result of the query shows that VERSION_COUNT is greater than 1 million, the blocking statement
can cause a performance drop for table updates. In this case, investigate what the statement is doing
and take the necessary corrective action. However, if VERSION_COUNT is less than 10,000, its impact
on performance is negligible.
b. If no blocker is shown by MVCC Blocker Statement, use MVCC Blocker Transaction to nd out which
transaction blocks global version garbage collection and investigate what the blocker is doing. The
blocker would most likely be an internal/external/serializable transaction; the lifetime value of the
transaction is shown in the column LIFE_TIME_SEC.
3. Kill the transaction and/or disconnect the connection that is blocking garbage collection.
a. Disconnect the connection.
To disconnect the blocking connection use: ALTER SYSTEM DISCONNECT SESSION
'CONNECTION_ID'
.
120
P U B L I C
SAP HANA Troubleshooting and Performance Analysis Guide
Root Causes and Solutions

b. If disconnecting the connection does not succeed or CONNECTION_ID does not exist, kill the
transaction.
In order to do that, look at Blocked Transactions in the Monitoring tile.
Related Information
SAP HANA Dynamic Tiering
3.15 Statement Performance Analysis
This section gives an overview of issues and solutions concerning SQL statement performance.
For more information about optimizing and ne-tuning queries refer to the SAP HANA Performance Guide for
Developers which includes sections such as:
Ongoing Development of SQL Query Processing Engines
Starting from HANA 2 SPS 02, two new processing engines to execute SQL queries are being phased in to SAP
HANA:
● Extended SQL Executor (ESX)
● HANA Execution Engine (HEX)
The functionality of the product remains the same but these engines oer better performance.
In the SPS 02 release these engines are active by default (no conguration is required) and are considered by
the SQL optimizer during query plan generation. In the SPS 02 release, the focus of the HEX engine is on
queries that are typical in OLTP scenarios. Queries that are not supported by HEX or where an execution is not
deemed benecial are automatically routed to the standard engine.
If necessary (for example, if recommended by SAP Support), you can set conguration parameters to
completely disable these engines. Each engine has a single parameter which can be switched to disable it:
File
Section Parameter Value Meaning
indexserver.ini sql esx_level Default 1, set to 0 to
disable.
Extended SQL executor enabled.
indexserver.ini sql hex_enabled Default True, set to
False to disable.
HANA execution engine enabled.
These engines should not be disabled permanently because they are being actively developed and improved in
each release.
SAP HANA Troubleshooting and Performance Analysis Guide
Root Causes and Solutions
P U B L I C 121

Query Hints
Further control of how these engines are used is available (from SPS 02.01) using hints with queries to
explicitly state which engine should be used to execute the query. For each engine two hint values are available
to either use or completely ignore the engine. The following table summarizes these and is followed by
examples:
Hint value Eect
USE_ESX_PLAN Guides the optimizer to prefer the ESX engine over the standard engine.
NO_USE_ESX_PLAN Guides the optimizer to avoid the ESX engine.
USE_HEX_PLAN Guides the optimizer to prefer the HEX engine over the standard engine.
NO_USE_HEX_PLAN Guides the optimizer to avoid the HEX engine.
Example
SELECT * FROM T1 WITH HINT(USE_ESX_PLAN);
SELECT * FROM T1 WITH HINT(NO_USE_HEX_PLAN);
Similar hints are available for the OLAP engine as described later in this section: Using Hints to Alter a Query
Plan.
Related Information
Using Hints to Alter a Query Plan
3.15.1 SQL Statement Optimization
This section provides an overview of tools, traces and SAP HANA cockpit areas that can be used to identify
critical SQL statements.
SQL statements that are not executed eciently can cause local and system-wide problems. The most critical
are the following areas:
● A long runtime can result in delays of the business activities
● A high CPU consumption can lead to system-wide CPU bottlenecks
● High memory consumption can be responsible for out-of-memory situations and performance penalties
due to unload of tables from memory
SQL statements consuming signicant resources are called expensive SQL statements.
122
P U B L I C
SAP HANA Troubleshooting and Performance Analysis Guide
Root Causes and Solutions

Identication of Critical SQL Statements
A key step in identifying the source of poor performance is to understand how much time is spent in the SAP
HANA engine for query execution. By analyzing SQL statements and calculating their response times, you can
better understand how the statements aect application and system performance.
Before you are able to analyze and optimize a SQL statement, you have to identify the critical SQL statements.
We can distinguish between the following scenarios:
● SQL statements that have caused problems in the past
● SQL statements that are currently causing problems
3.15.1.1 SQL Statements Responsible for Past Problems
Sometimes it is not possible to identify a critical SQL statement during runtime. In this case you can use the
following approaches to identify one or several SQL statements that can have contributed to the problem.
You can identify a SQL statement either by its SQL text (“statement string”) or by the related statement hash
that is uniquely linked to an individual SQL text. The mapping of the statement hash to the actual SQL text is
described later.
To determine SQL statements with a particularly high runtime you can check for the top SQL statements in
terms of TOTAL_EXECUTION_TIME on the SQL Plan Cache page in the SAP HANA cockpit.
To determine the top SQL statements that were executed during a dedicated time frame in the past, you can
check the SQL plan cache history (HOST_SQL_PLAN_CACHE). You can use the SQL statement:
“HANA_SQL_SQLCache” available from SAP Note 1969700 – SQL Statement Collection for SAP HANA in order
to check for top SQL statements during a specic time frame:
You have to specify a proper BEGIN_TIME / END_TIME interval and typically use ORDER_BY = ‘ELAPSED’, so
that the SQL statements with the highest elapsed time from SAP HANA are returned.
SQL Statements With Highest Elapsed Time
The thread sample history (tables M_SERVICE_THREAD_SAMPLES, HOST_SERVICE_THREAD_SAMPLES), if
available, can also be used to determine the top SQL statements. You can use the SQL statement:
“HANA_Threads_ThreadSamples_FilterAndAggregation” available from SAP Note 1969700 – SQL Statement
Collection for SAP HANA in order to check.
You have to specify a proper BEGIN_TIME / END_TIME interval and use AGGREGATE_BY =
‘STATEMENT_HASH’ to identify the top SQL statements during the time frame.
SAP HANA Troubleshooting and Performance Analysis Guide
Root Causes and Solutions
P U B L I C 123

SQL Example Output
In this case the SQL statement with hash 51f62795010e922370bf897325148783 is executed most often and so
the analysis should be started with it. Often you need to have a look at some more SQL statements, for
example the statements related to the next statement hashes fc7de6d7b8942251ee52a5d4e0af728f and
1f8299f6cb5099095ea71882f84e2cd4.
In cases where the M_SERVICE_THREAD_SAMPLES / HOST_SERVICE_THREAD_SAMPLES information is not
usable you can use the thrloop.sh script to regularly collect thread samples as described in SAP Note
1989031 – Scheduling of Shell script “thrloop.sh”.
In case of an out-of-memory (OOM) situation you can determine potentially responsible SQL statements by
analyzing the OOM dump le(s) as described in SAP Note 1984422 – Analysis of HANA Out-of-memory (OOM)
Dumps.
SAP HANA Alert 39 (“Long-running statements”) reports long-running SQL statements and records them in
the table _SYS_STATISTICS.HOST_LONG_RUNNING_STATEMENTS. Check the contents of this table to
determine details of the SQL statements that caused the alert. See also KBA 1849392 - HANA alerts related to
locks, hanging sessions and long runners.
Related Information
SAP Note 1969700
SAP Note 1989031
SAP Note 1984422
SAP Note 1849392
3.15.1.2 SQL Statements Responsible for Current Problems
If problems like high memory consumption, high CPU consumption or a high duration of individual database
requests are currently happening, you can determine the active SQL statements with the help of SAP HANA
cockpit.
Check for the currently running SQL statements in SAP HANA cockpit by clicking on the Threads tile.
124
P U B L I C
SAP HANA Troubleshooting and Performance Analysis Guide
Root Causes and Solutions
Tracing
You can also activate the following traces to capture more detailed information to help identify critical SQL
statements:
● SQL trace can be used to capture performance data for all SQL statements, you can use lter conditions to
limit the trace activities.
● Expensive statements trace captures all SQL statements with a runtime beyond a dened threshold.
Further details can be found in Tools and Tracing.
Related Information
Tools and Tracing [page 174]
3.15.2 Analysis of Critical SQL Statements
When you have identied the SQL text and the related statement hash based on the tools and traces, you can
collect more information about the SQL statement in order to identify the root cause of the performance
problem and optimize the statement. The available analysis approaches are described here.
From a technical perspective, analyzing query plans allows you to identify long running steps, understand how
much data is processed by the operators, and see whether data is processed in parallel.
However, if you understand the idea and purpose behind the query, you can also analyze query plans from a
logical perspective and consider the following questions to gain the insight you need:
● Does SAP HANA read data from multiple tables when only one is required?
● Does SAP HANA read all records when only one is required?
● Does SAP HANA start with one table even though another table has a much smaller result set?
The following tools can be used for a more detailed analysis:
● Plan Explanation - used to evaluate the execution plan;
● SQL analyzer - provides a detailed graphical execution plan with a timeline;
● Query optimizer (QO) Trace - an advanced tool that can be useful to understand the decisions of the query
optimizer and column searches;
● Join evaluation (JE) Trace - an advanced tool to analyze table join operations;
● Performance trace - this advanced tool should only be used in collaboration with SAP support, it gives low
level recording of key performance indicators for individual SQL statement processing steps;
● Kernel proler - this advanced tool should only be used in collaboration with SAP support, it performs
sample based proling of SAP HANA process activities.
SAP HANA Troubleshooting and Performance Analysis Guide
Root Causes and Solutions
P U B L I C 125
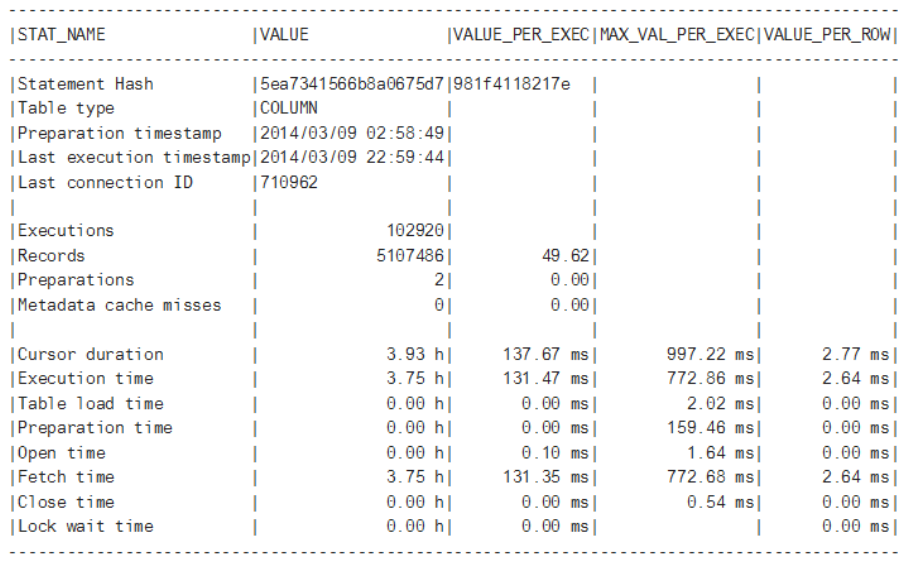
Related Information
Analyzing SQL Execution with the Plan Explanation [page 191]
Analyzing SQL Execution with the Plan Visualizer [page 195]
Analyzing Column Searches (qo trace) [page 224]
Analyzing Table Joins [page 226]
Performance Trace [page 231]
Kernel Proler [page 233]
3.15.2.1 SQL Plan Cache Analysis
The SAP HANA SQL plan cache can be evaluated in detail for a particular statement hash.
Various options are available for analyzing the plan cache for a statement. In SAP HANA cockpit the link for
SQL Plan Cache is available in the Monitoring tile. The two system views associated with the SQL plan cache are
M_SQL_PLAN_CACHE_OVERVIEW and M_SQL_PLAN_CACHE.
Alternatively, SQL statements for this are available in SAP Note 1969700 – SQL Statement Collection for SAP
HANA. You can use the “HANA_SQL_StatementHash_KeyFigures” script to check for the SQL plan cache
details of a specic SQL statement (the related STATEMENT_HASH has to be maintained as input parameter).
SQL PLAN Cache Example Output
The historic execution details for a particular SQL statement can be determined with the SQL statement:
“HANA_SQL_SQLCache”. Also here the appropriate STATEMENT_HASH has to be specied as input
parameter.
126
P U B L I C
SAP HANA Troubleshooting and Performance Analysis Guide
Root Causes and Solutions

Statement Hash Example output
Based on the results of this evaluation you can distinguish the following situations:
● If the value for Executions is unexpectedly high, further analysis should be done on the application side in
order to check if it is possible to reduce the number of executions.
● If the value for Records is unexpectedly high, further analysis should be done on the application side in
order to check if it is possible to reduce the number of selected records.
● If the value for Cursor duration is very high and at the same time signicantly higher than the value for
Execution time, you have to check which processing steps are executed on the application side between
the individual fetches. A high value for Cursor duration can negatively impact the database in general
because open changes may impact the MVCC mechanism.
● If the value for Preparation time is responsible for a signicant part of the Execution time value you have to
focus on optimizing the parsing (for example, sucient SQL plan cache size, reuse of already parsed SQL
statements).
● If Execution time is much higher than expected (that can be based on the statement complexity and the
number of processed rows), the SQL statement has to be checked more in detail on technical layer to
understand the reasons for the high runtime. See section Query Plan Analysis for more information.
Related Information
SAP Note 1969700
Query Plan Analysis [page 190]
Analyzing SQL Execution with the SQL Plan Cache [page 189]
SAP HANA Troubleshooting and Performance Analysis Guide
Root Causes and Solutions
P U B L I C 127

3.15.2.1.1 Example: Reading the SQL Plan Cache
These examples aim to show you how to gain useful insights by analyzing the SQL plan cache.
Execution in a Single-Host System
This example aims to show you how to interpret information about execution time. The following table is sorted
by TOTAL_EXECUTION_TIME.
USER_
NAME
STATEMENT_ STRING
TOTAL_ EXECUTION_
TIME
AVG_ EXECUTION_
TIME EXECUTION_ COUNT
SYSTEM
SELECT "REQUEST" ,
"DATAPAKID" , "PARTNO" ,
"RECORD" ,
"CALDAY" , ...
774,367,833
181,266 4,272
SYSTEM
SELECT * FROM "/BIC/
AZDSTGODO40" WHERE "SID"
= ?
726,672,877 60,556,073 12
SYSTEM
SELECT "JOBNAME" ,
"JOBCOUNT" ,
"JOBGROUP" ,
"INTREPORT" ,
"STEPCOUNT" ...
473,620,452
22,987 20,604
– <Further 6832 records> – – –
You could read these top 3 results as follows:
● Statement 1 takes the longest time overall but it is also executed frequently.
● Statement 2 is not executed very frequently but has the second highest total execution time. Why is this
simple SQL taking so long? Does it have problems processing?
● The execution times for statement 3 are ne for one-o execution, but it runs too frequently, over 20,000
times. Why? Is there a problem in application code?
Sorting by AVG_EXECUTION_TIME or EXECUTION_COUNT provides a dierent angle on your analysis.
The following example aims to show you how to interpret information about locking situations. The information
in columns TOTAL_LOCK_WAIT_COUNT and TOTAL_LOCK_WAIT_DURATION lets us know which statement is
waiting for others and how much time it takes.
USER STATEMENT_STRING
TOTAL_LOCK_
WAIT_COUNT
TOTAL_LOCK_
WAIT_DURATION
TOTAL_ EXECU
TION_TIME
SYSTEM
SELECT
"FROMNUMBER","TONUMBER",
"NRLEVEL" FROM
"NRIV" ... FOR UPDATE
11,549,961
210,142,307,207 676,473
128 P U B L IC
SAP HANA Troubleshooting and Performance Analysis Guide
Root Causes and Solutions

USER STATEMENT_STRING
TOTAL_LOCK_
WAIT_COUNT
TOTAL_LOCK_
WAIT_DURATION
TOTAL_ EXECU
TION_TIME
SYSTEM
UPDATE "NRIV" SET
"NRLEVEL" = ? WHERE
"CLIENT" = '000' ... AND
"TOYEAR" = '0000'
0
0 3,706,184
SYSTEM
SELECT "DIMID" FROM
"/BIC/DZDSTGCUBE4" WHERE
"/B49/S_VERSION" = ?
0 0 460,991
Here, it is clear that the rst statement is waiting almost all the time. Known as pessimistic/optimistic locking,
the SELECT...FOR UPDATE code locks the resulting columns and may be replaced by a non-locking variant,
which can result in poor performance. If the application is critical, it may be necessary to revise the
SELECT...FOR UPDATE code for better resource utilization and performance.
Execution in a Distributed System
In distributed SAP HANA systems, tables and table partitions are located on multiple hosts. The execution of
requests received from database clients may potentially have to be executed on multiple hosts, depending on
where the requested data is located. The following example illustrates statement routing and how, if it is not
enabled, requests from the database client are executed on the contacted index server (in this case the master
index server) and the required data is fetched from the index server on the relevant host(s). However, if
statement routing is enabled, after initial query compilation, request execution is routed directly to the host on
which the required data is located.
Distributed Execution with Statement Routing O and On
Execution times should be better with statement routing enabled. You can use the SQL plan cache to compare
the execution statistics of statements with statement routing enabled and disabled and thus conrm the eect.
SAP HANA Troubleshooting and Performance Analysis Guide
Root Causes and Solutions
P U B L I C 129

Statement routing is controlled by the client_distribution_mode parameter in the indexserver.ini
le. It is enabled by default (value=statement).
The following SQL plan cache examples show the execution times of sample statements based on the scenario
illustrated above with hosts A, B and C.
Note
The column IS_DISTRIBUTED_EXECUTION indicates whether or not statement execution takes place on
more than one host.
The TOTAL_EXECUTION_TIME for a statement is the sum of execution times on all hosts, therefore:
Statement
Request Path Total Execution Time
UPSERT "RSBMONMESS_DTP"
( "MSGNO", "MSGTY", "MSGID", ...
Host A = execution time on Host A
SELECT * FROM "/BI0/SIOBJNM"
WHERE "IOBJNM" = ?
Host A > Host B = execution time on Host A + execution
time on Host B
SELECT * FROM "/B49/SCUSTOMER"
WHERE "/B49/S_CUSTOMER" = ?
Host A > Host B > Host C = execution time on Host B + execution
time on Host C
130 P UB L I C
SAP HANA Troubleshooting and Performance Analysis Guide
Root Causes and Solutions

Statement Request Path Total Execution Time
UPSERT "RSBMONMESS_DTP"
( "MSGNO", "MSGTY", "MSGID", ...
Host A = execution time on Host A
SELECT * FROM "/BI0/SIOBJNM"
WHERE "IOBJNM" = ?
Host B = execution time on Host B
SELECT * FROM "/B49/SCUSTOMER"
WHERE "/B49/S_CUSTOMER" = ?
Host C = execution time on Host C
3.15.3 Optimization of Critical SQL Statements
You can improve the general performance of the SAP HANA database by implementing various best practices,
design principles, available features, and add-ons.
To enhance the performance of the SAP HANA database, we recommend you do the following:
● Optimize outlier queries
Queries that sometimes take much longer than expected can be caused by query-external factors (for
example, resource bottlenecks) that have to be determined and eliminated.
● Check data manipulation commands (DML)
DML operations like INSERT, UPDATE and DELETE can be impacted by lock waits.
● Create indexes for any non-primary key columns that are often queried.
SAP HANA automatically creates indexes for primary key columns; however, if you need indexes for non-
primary key columns, you must create them manually.
● Use native HANA models
Develop native HANA models and graphical calculation views in the SAP Web IDE to take advantage of the
latest performance optimization capabilities.
● Develop procedures to embed data-intensive application logic into the database.
With procedures, no large data transfers to the application are required and you can use performance-
enhancing features such as parallel execution.
○ If you use SQLScript to create procedures, follow the best practices for using SQLScript.
○ For statistical computing, create procedures using the open source language R.
● Download and install the available application function libraries, such as Predictive Analysis Library (PAL)
and Business Function Library (BFL).
Application functions are like database procedures written in C++ and called from outside to perform data
intensive and complex operations.
● Scale SAP HANA to improve performance.
SAP HANA's performance is derived from its ecient, parallelized approach. The more computation cores
your SAP HANA server has, the better overall system performance is.
Note
With SAP HANA, you do not need to perform any tuning to achieve high performance. In general, the SAP
HANA default settings should be sucient in almost any application scenario. Any modications to the
predened system parameters should only be done after receiving explicit instruction from SAP Support.
SAP HANA Troubleshooting and Performance Analysis Guide
Root Causes and Solutions
P U B L I C 131

3.15.3.1 Outlier Queries
Outlier queries are database statements that take much more time than usual and expected. This usually
happens because extra work has to be performed during execution.
Besides heavy load on the machine by non-SAP HANA processes (which should not be the case on production
systems) SAP HANA itself can be under heavy load. Reasons include:
● Many users are connected and issue a large amount of statements
● Extraordinary expensive statements are executed
● Background tasks are running
Use the Performance Monitor to determine the number of statements issued and the indexserver CPU usage
while the slow statement execution was perceived (see the gure CPU Consumption and SQL Throughput, the
lower line (red) is the CPU consumption in percent (%), the upper line (orange) is the SQL throughput / s):
CPU Consumption and SQL Throughput
You can see that during the period in the red rectangle both CPU consumption and SQL throughput decreased.
During that time frame you would look for something that consumed a lot of resources or blocked the
statements (locking); just after 15:35 you see that the CPU consumption increases while the SQL throughput
decreases. Here, a possible case would be a change in usage: instead of many small, fast SQL statements the
workload changed to a few "heavy" (complicated calculation requiring many CPU cycles) SQL statements.
If there was a high statement load in the same period when you experienced the slow execution, the root cause
is likely a lack of resources. To resolve the situation consider restricting the number of users on SAP HANA or
upgrading the hardware. See Getting Support for further help, for example if you need to improve scalability.
If you did not experience a high statement load during the time frame of the problem, check for background
activities:
● Delta Merges: Use Performance Monitor Merge Requests and the monitoring view
M_DELTA_MERGE_STATISTICS to check if delta merges happened. In that case try to improve the delta
merge strategy to prevent merges happening in phases where users are disturbed (see the SAP HANA
Administration Guide for details).
● Column Unloads: See Load Monitor Column Unloads and the monitoring view M_CS_UNLOADS to
look for signs of column unloads. If a column used in the problematic statement had to be loaded before
execution, the execution itself will take signicantly longer.
● Savepoints: Savepoints consume resources and write-lock the database during their critical phase. Check
M_SAVEPOINTS and look for savepoints during the time frame of the problem. If a savepoint slowed down
132
P U B L I C
SAP HANA Troubleshooting and Performance Analysis Guide
Root Causes and Solutions

your execution, the chance of having the same problem again is very low. If it happens often, see Getting
Support for further help.
Related Information
M_DELTA_MERGE_STATISTICS
M_CS_UNLOADS
M_SAVEPOINTS
Getting Support
3.15.3.2 Data Manipulation Language (DML) Statements
Data Manipulation Language (DML) statements are often slowed down by lock-wait situations.
Check under Monitoring SQL Plan Cache and the view M_SQL_PLAN_CACHE to determine such issues:
Note
Only check entries that have TOTAL_LOCK_WAIT_COUNT greater than 0. For those entries, compare the
column MAX_CURSOR_DURATION against AVG_CURSOR_DURATION. If there is a signicant dierence,
there was at least one situation where the transactions took much longer than average.
See Transactional Problems for information on how to deal with such issues.
Related Information
M_SQL_PLAN_CACHE
Transactional Problems [page 111]
3.15.3.3 Creation of Indexes on Non-Primary Key Columns
Create indexes on non-primary key columns to enhance the performance of some queries using the index
adviser.
SAP HANA automatically creates indexes for all primary key columns.
Indexing the primary key columns is usually sucient because queries typically put lter conditions on primary
key columns. When lter conditions are on non-key elds and tables have many records, creating an index on
the non-primary key columns may improve the performance.
SAP HANA Troubleshooting and Performance Analysis Guide
Root Causes and Solutions
P U B L I C 133

Tip
To check whether there is an index for a column, in the Plan Graph of the SQL analyzer, in the properties of
a column, see the Inverted Index entry. Alternatively, you can also see the system view INDEXES.
You can create indexes on non-primary key columns to enhance the performance of some queries, particularly
highly selective queries on non-primary key columns.
Use the index adviser to nd out for which tables and columns indexing would be most valuable. The
indexAdvisor.py script is part of a SAP HANA system installation and runs from the command line. It is located
in the
$DIR_INSTANCE/exe/python_support directory.
There is a trade-o between indexing and memory consumption: While indexing non-primary key columns can
make query execution faster, the downside is that memory consumption increases. The index adviser takes
this trade-o into account: In dynamic mode, the index adviser looks for the tables and columns that are used
most often. The higher the selectivity is, that is, the more dierent the values are in the column, the higher the
performance gains are from indexing the columns.
To create indexes on non-primary columns, use the CREATE INDEX statement as follows:
CREATE INDEX <name> ON <table> (<column>)
Related Information
SAP HANA SQL and System Views Reference
3.15.3.4 Developing Procedures
SQL in SAP HANA includes extensions for creating procedures, which enables you to embed data-intensive
application logic into the database, where it can be optimized for performance (since there are no large data
transfers to the application and features such as parallel execution is possible). Procedures are used when
other modeling objects, such as views, are not sucient; procedures are also often used to support the
database services of applications that need to write data into the database.
Reasons to use procedures instead of standard SQL, include:
● SQL is not designed for complex calculations, such as for nancials.
● SQL does not provide for imperative logic.
● Complex SQL statements can be hard to understand and maintain.
● SQL queries return one result set. Procedures can return multiple result sets.
● Procedures can have local variables, eliminating the need to explicitly create temporary tables for
intermediate results.
Procedures can be written in the following languages:
● SQLScript: The language that SAP HANA provides for writing procedures.
● R: An open-source programming language for statistical computing and graphics, which can be installed
and integrated with SAP HANA.
134
P U B L I C
SAP HANA Troubleshooting and Performance Analysis Guide
Root Causes and Solutions

There are additional libraries of procedures, called Business Function Library and Predictive Analysis Library,
that can be called via SQL or from within another procedure.
HANA Database Explorer
HANA Database Explorer provides a comprehensive set of development tools that allow you to evaluate, revise,
and optimize stored procedures. You can browse through the objects in the schema to locate the procedures,
from there, a number of options are available from the context menu. Features include a code editor for running
and testing procedures as well as debugging and SQLScript analysis tools. Refer to the documentation
sections on Database Explorer in the SAP HANA Administration Guide for more details.
SQL Extensions for Procedures
SQL includes the following statements for enabling procedures:
● CREATE TYPE: Creates a table types, which are used to dene parameters for a procedure that represent
tabular results. For example:
CREATE TYPE tt_publishers AS TABLE (
publisher INTEGER,
name VARCHAR(50),
price DECIMAL,
cnt INTEGER);
● CREATE PROCEDURE: Creates a procedure. The LANGUAGE clause species the language you are using to
code the procedure. For example:
CREATE PROCEDURE ProcWithResultView(IN id INT, OUT o1 CUSTOMER)
LANGUAGE SQLSCRIPT READS SQL DATA WITH RESULT VIEW ProcView AS
BEGIN
o1 = SELECT * FROM CUSTOMER WHERE CUST_ID = :id;
END;
● CALL: Calls a procedure. For example:
CALL getOutput (1000, 'EUR', NULL, NULL);
Related Information
Create and Edit Procedures
Open the SAP HANA Database Explorer (SAP HANA Cockpit)
SAP HANA Troubleshooting and Performance Analysis Guide
Root Causes and Solutions
P U B L I C 135

3.15.3.5 Application Function Library (AFL)
You can dramatically increase performance by executing complex computations in the database instead of at
the application server level.
SAP HANA provides several techniques to move application logic into the database, and one of the most
important is the use of application functions. Application functions are like database procedures written in C++
and called from outside to perform data intensive and complex operations. Functions for a particular topic are
grouped into an application function library (AFL), such as the Predictive Analytical Library (PAL) or the
Business Function Library (BFL).
Currently, all AFLs are delivered in one archive (that is, one SAR le with the name AFL<version_string>.SAR).
Note
The AFL archive is not part of the SAP HANA appliance, and must be installed separately by an
administrator. For more information about installing the AFL archive, see the SAP HANA Server Installation
and Update Guide.
Security Considerations
● User and Schema
During startup, the system creates the user _SYS_AFL, whose default schema is _SYS_AFL.
Note
The user and its schema _SYS_AFL are created during a new installation or update process if they do
not already exist.
All AFL objects, such as areas, packages, functions, and procedures, are created under this user and
schema. Therefore, all these objects have fully specied names in the form of _SYS_AFL.<object name>.
● Roles
For each AFL library, there is a role. You must be assigned to this role to execute the functions in the library.
The role for each library is named: AFL__SYS_AFL_<AREA NAME>_EXECUTE. For example, the role for
executing PAL functions is AFL__SYS_AFL_AFLPAL_EXECUTE.
Note
There are 2 underscores between AFL and SYS.
Note
Once a role is created, it cannot be dropped. In other words, even when an area with all its objects is
dropped and recreated during system start-up, the user still keeps the role that was previously granted.
136
P U B L I C
SAP HANA Troubleshooting and Performance Analysis Guide
Root Causes and Solutions
3.15.3.6 Aspects of Scalability
Before you decide how to scale your SAP HANA implementation, there are a number of aspects that need to be
considered, such as scaling data, performance, applications, and hardware.
Scaling the Data
One technique you can use to deal with planned data growth is to purchase more physical RAM than is initially
required to set the allocation limit according to your needs, and then to increase it over time to adapt to your
data. Once you have reached the physical limits of a single server, you can scale out over multiple machines to
create a distributed SAP HANA system. You can do this by distributing dierent schemas and tables to
dierent servers (complete data and user separation). However, this is not always possible, for example, when
a single fact table is larger than the server's RAM size.
The most important strategy for scaling your data is data partitioning. Partitioning supports the creation of
very large tables (billions of rows) by breaking them into smaller chunks that can be placed on dierent
machines. Partitioning is transparent for most SQL queries and other data manipulations.
For more information, see the section on managing tables.
Scaling Performance
SAP HANA's performance is derived from its ecient, parallelized approach. The more computation cores your
SAP HANA server has, the better the overall system performance is.
Scaling performance requires a more detailed understanding of your workload and performance expectations.
Using simulations and estimations of your typical query workloads, you can determine the expected load that a
typical SAP HANA installation may comfortably manage. At the workload level, a rough prediction of scalability
can be established by measuring the average CPU utilization while the workload is running. For example, an
average CPU utilization of 45% may indicate that the system can be loaded 2X before showing a signicant
reduction in individual query response time.
For more information, see the sections on workload management and performance analysis.
Scaling the Application
Partitioning can be used to scale the application as it supports an increasing number of concurrent sessions
and complex analytical queries by spreading the calculations across multiple hosts. Particular care must be
taken in distributing the data so that the majority of queries match partitioning pruning rules. This
accomplishes two goals: directing dierent users to dierent hosts (load balancing) and avoiding the network
overhead related to frequent data joins across hosts.
SAP HANA Troubleshooting and Performance Analysis Guide
Root Causes and Solutions
P U B L I C 137

Scaling Hardware
SAP HANA is oered in a number of ways – in the form of an on-premise appliance, delivered in a number of
dierent congurations and "sizes" by certied hardware partners or by using the tailored data center
integration model, and as part of a cloud-based service. This creates dierent system design options with
respect to scale-up and scale-out variations. To maximize performance and throughput, SAP recommends that
you scale up as far as possible (acquire the conguration with the highest processor and memory specication
for the application workload), before scaling out (for deployments with even greater data volume
requirements).
Note
The SAP HANA hardware partners have dierent building blocks for their scale-out implementations.
Therefore, you should always consult with your hardware partner when planning your scale-out strategy.
Related Information
Table Partitioning
Workload Management
Managing and Monitoring SAP HANA Performance
3.15.3.7 Further Recommendations
In addition to the general recommendations for improving SAP HANA database performance, for specic
scenarios, you can use further features and best practices to improve performance.
If appropriate, you can take the following actions to improve performance:
● For any required long-running transactions, you can use the SQL command ALTER SYSTEM RECLAIM
VERSION SPACE to trigger the row store garbage collector to free up memory space and enhance system
responsiveness.
● For multicolumn join scenarios, use dynamic joins rather than standard joins.
In a dynamic join, the elements of a join condition between two data sources are dened dynamically based
on the elds requested by the client query. It is used to improve the performance by reducing the number
of records to be processed by the join node.
● When inserting or loading a large number of rows into a table that has a TEXT or SHORTTEXT column or
uses a FULLTEXT INDEX, merge the delta of the table for better search performance.
● When loading data from CSV les using the IMPORT FROM command, use THREADS and BATCH to enable
parallel loading and commit many records at once. In general, for column tables, a good setting to use is 10
parallel loading threads, with a commit frequency of 10,000 records or greater. You can also use TABLE
LOCK, which locks the entire table and bypasses the delta table. Table locks are only recommended for
initial loads.
138
P U B L I C
SAP HANA Troubleshooting and Performance Analysis Guide
Root Causes and Solutions
3.16 Application Performance Analysis
This section provides a high-level guide for analyzing the performance of SAP HANA-based applications.
When you have an SAP HANA-based application with unsatisfying performance, you should start a systematic
investigation considering the various layers that are involved. Here we focus on the database layer; approaches
for analyzing UI and application server performance are described in the respective documents.
3.16.1 SQL Trace Analysis
The rst step in application performance analysis is to gure out if the database layer is causing performance
problems for your application at all.
Context
You should analyze how many and which database calls are made and what their contribution to the overall
application performance is. This should be done within the context of a given user interface step or transaction.
Procedure
1. Start the tracing of database calls.
2. Run the application from its user interface or with any other driver.
Both, SAP HANA cockpit and SAP Web IDE for SAP HANA provide two main tracing tools, namely SQL
trace and Expensive statements trace.
A convenient way to narrow the trace analysis to the scope of a user interface step or transaction is to use
the passport-based ltering of Expensive statements trace in the SAP Web IDE for SAP HANA, which also
oers aggregated statistics to quickly answer above questions.
Deep tracing (including complete execution plans) is provided by Plan trace in SAP HANA cockpit.
3. Terminate the tracing and review aggregated and individual results.
4. As a result of this investigation you might see some indicators for bad application logic creating excessive
load on the database such as:
○ Too many database calls (per transaction/UI step)
○ Many identical executions, for example repeated identical selects
○ Too many records returned (per execution or in total)
○ Too many columns or all columns of a row selected
○ Inecient statement reuse, that is, statements that need to be optimized over and over again
○ One or more database calls with unexpected bad performance, so you should further investigate those
calls
SAP HANA Troubleshooting and Performance Analysis Guide
Root Causes and Solutions
P U B L I C 139

Related Information
Plan Trace [page 207]
Analyzing SQL Traces [page 181]
Expensive Statements Trace [page 186]
3.16.2 Statement Measurement
Once you have determined which SQL statements are problematic you should rst perform a sound
measurement in order to get reliable performance numbers and to make sure that indeed your statements are
causing the issues and not the current state of your SAP HANA system.
Procedure
1. Execute your statements and measure their performance (in particular response time).
SAP HANA cockpit oers basic measurement of SQL statements. In addition, the SAP HANA database
explorer and the SQL analyzer support executing and analyzing SQL statements.
2. Check your SAP HANA system status for disturbing conditions, such as high load, high resource usage and
so on.
3. In case of disturbing conditions repeat your measurement from step 1.
4. Repeat your measurements until you get stable results without major variations (for example, 3 stable
executions in a row).
Note
Higher initial response times could be an indicator of caches that are not properly lled. Depending on
your business needs you can decide whether this is acceptable or not.
5. Once you have a stable result you may also acquire a detailed SAP HANA engine trace which will allow for a
deeper analysis.
Results
As a result of this activity you have reliable data for your query performance, both for initial query execution
performance (possibly cold execution) and stabilized execution performance (warm execution).
Related Information
Statement Performance Analysis [page 121]
140
P U B L I C
SAP HANA Troubleshooting and Performance Analysis Guide
Root Causes and Solutions

3.16.3 Data Analysis
The easiest way to analyze a poorly performing SQL statement is to look at the data ow as this can be
matched with the understanding of the business/application needs.
Procedure
1. Check the result size, that is the number of records and number of columns, returned by your SQL
statement and compare it with the actual business needs.
As a result of this investigation you might restrict the result size by changing the application logic (for
example, the number of columns selected in the eld list or by applying additional lters in the WHERE
clause) with regards to its database call.
2. Check the usage of underlying tables, meaning the set of tables used, their size and the number of entries
selected from those tables, and compare it with your understanding of the business needs.
As a result of this investigation you might identify tables that should not be involved at all and adapt your
statement or the underlying database logic accordingly (for example, by checking joins and join types).
SAP HANA cockpit oers data ow analysis with the Tables Used view in the SQL analyzer.
3. Check the data ow of your statement, that is, the order in which tables are joined, how lters are applied
and the size of intermediate results.
As a result of this investigation you may identify:
○ inecient join orders (starting with table A and not with table B, when that is the much smaller result
set)
○ unexpectedly missing lters (that is, intermediate selections which seem too broad).
You can then adapt your statement or underlying database logic as necessary.
SAP HANA cockpit oers data ow analysis with the Plan Graph view in the SQL analyzer.
For detailed information about the SQL analyzer, refer to Analyzing Statement Performance in the SAP
HANA Administration Guide.
Related Information
Tables Used [page 205]
Analyzing Statement Performance
SAP Note 2565156
SAP HANA Troubleshooting and Performance Analysis Guide
Root Causes and Solutions
P U B L I C 141
3.16.4 Source Analysis
Before conducting a detailed technical analysis, it is recommended to rst analyze source artifacts (models,
scripts, views) for possible performance-impacting aspects.
Context
The actual activities depend on the respective artifact (models, scripts, views).
Procedure
1. Graphical Calculation Views
SAP Web IDE for SAP HANA oers dedicated performance debugging capabilities as part of the modeler
for graphical calculation views; furthermore it provides deeper inspection of these views.
a. Check the eect of the attributes, parameters and lters used in the query on the execution time.
b. Check that the information is combined and aggregated in the correct way as required by the business
scenario, for example:
○ Is the aggregation behavior consistent with the intended semantics?
○ Is the join cardinality correct for each join?
○ Are dynamic joins used?
○ Is the result always aggregated?
○ Has Join Optimization been enabled?
○ Do analytical privileges inuence performance?
c. Check whether any performance-relevant execution hints are activated, for example:
○ Enforce execution via a specied database engine
○ Enforce upper bound for parallelization
d. Check whether modeling constructs are used that are known to be costly, for example:
○ Calculated join attributes
○ Complicated lter expressions
○ Mixed models that involve engine switches
e. Check whether intermediate steps produce reasonable results (in terms of size).
2. SQL Script
The Statement Statistics view (part of the SQL analyzer) supports analysis of SQLScript.
a. Check if your procedure ts with the given guidelines
For example, see Developing Procedures
b. Analyze your script for most expensive steps / statements
3. Plain SQL
a. Check if your statement ts with the guidelines for SQL Query Design
For example, see Optimization of Critical SQL Statements
142
P U B L I C
SAP HANA Troubleshooting and Performance Analysis Guide
Root Causes and Solutions
Results
As a result of this activity you either gured out and solved problems at the source level or you now have to
continue with an even deeper technical analysis.
Related Information
Developing Procedures [page 134]
Technical Analysis [page 143]
Statement Statistics [page 199]
Optimization of Critical SQL Statements [page 131]
3.16.5 Technical Analysis
The deepest level of performance analysis addresses the technical details of a database statement execution.
Context
You should follow this in order to track down problematic performance symptoms from which you can derive
possible root causes at higher levels.
There are a number of tools that can support you. SAP HANA cockpit oers the SQL analyzer which allows for
deep technical analysis. Dedicated views and lters support the analysis along numerous dimensions. For
detailed information about the SQL analyzer, refer to Analyzing Statement Performance in the SAP HANA
Administration Guide.
Procedure
1. Inspect aggregated execution KPIs (execution time, resource consumption, distribution characteristics) in
order to gure out in which aspect or dimension you might look for possible issues.
2. For any suspicious KPI, track down the KPI to the deepest possible level manifesting the symptom.
3. From there, try to correlate the symptom with the cause, in higher level statement elements.
4. You might restrict the scope of your analysis by focusing on the critical path, or on a specic time interval,
system node, engine, or execution plan operator.
SAP HANA Troubleshooting and Performance Analysis Guide
Root Causes and Solutions
P U B L I C 143

Related Information
Analyzing SQL Execution with the Plan Explanation [page 191]
Analyzing Statement Performance
SAP Note 2565156
3.17 System Hanging Situations
This section explains what checks to carry out and how to perform those checks if your SAP HANA instance is
hanging. The database is said to be hanging when it no longer responds to queries that are executed against it.
Context
The source of the system standstill might be related to any of the components involved, for example, the
storage, OS and hardware, network, SAP HANA database or the application layer. For troubleshooting it is
essential to collect information about the context of the active threads in the SAP HANA database.
As SQL statements cannot usually be executed for analysis, you should perform the following steps if it is still
possible to log on to the OS of the master host (for example, as the <sid>adm user). Also see SAP Note
1999020 on "SAP HANA: Troubleshooting when database is no longer reachable" for further specic steps and
guidance on proactive or reactive actions you can take.
Procedure
1. Collect a runtime dump (see SAP Note 1813020 - How to generate a runtime dump on SAP HANA).
2. Collect CPU, memory and other information about threads currently running in the system by executing
the command top -H and taking a screenshot of the output.
Note
Transparent Huge Pages (THP) is only applicable to servers with Intel processors.
3. Please provide this information when logging an incident with SAP support and avoid restarting the
database as otherwise retrospective analysis might not always be possible.
Related Information
SAP Note 1999020
SAP Note 1813020
144
P U B L I C
SAP HANA Troubleshooting and Performance Analysis Guide
Root Causes and Solutions

Transparent Huge Pages [page 145]
CPU Power Saving [page 146]
3.17.1 Transparent Huge Pages
Transparent Huge Pages (THP) is a feature that is generally activated for the Linux kernel shipped with SUSE
Linux Enterprise Server (SLES) 11 and Red Hat Enterprise Linux (RHEL) 6 versions certied for usage with SAP
HANA. Due to the special manner of SAP HANA's memory management, using THP may lead to hanging
situations and performance degradations.
Context
You experience that your SAP HANA database does not react anymore, that the CPU load is high and/or severe
performance issues occur. Additionally, Transparent Huge Pages are activated on your SAP HANA servers.
Until further notice, SAP strongly recommends that you disable Transparent Huge Pages on all your SAP HANA
servers.
Note
Transparent Huge Pages is supported on Intel-based hardware platforms only.
See the SAP Notes below for further reference:
● SAP Note 2131662 - Transparent Huge Pages (THP) on SAP HANA Servers
● SAP Note 1824819 - SAP HANA DB: Recommended OS settings for SLES 11 / SLES for SAP Applications 11
SP2
● SAP Note 1954788 - SAP HANA DB: Recommended OS settings for SLES 11 / SLES for SAP Applications 11
SP3
● SAP Note 2013638 - SAP HANA DB: Recommended OS settings for RHEL 6.5
● SAP Note 2136965 - SAP HANA DB: Recommended OS settings for RHEL 6.6
Note
The following checks and steps should be performed on all hosts of the aected SAP HANA system. They
have to be executed as the root user in the Linux shell.
Procedure
1. To check whether Transparent Huge Pages are activated and currently being used by processes, execute
the below commands in the Linux shell:
a. cat /sys/kernel/mm/transparent_hugepage/enabled
b. cat /proc/meminfo | grep AnonHugePages
SAP HANA Troubleshooting and Performance Analysis Guide
Root Causes and Solutions
P U B L I C 145

If the rst output shows "[always] madvise never", that is "always" is shown inside square brackets, then
THPs are activated according to the value of the relevant Linux Kernel parameter. If the second output
shows a value greater than 0 Kb (Kilobytes), then this is evidence that some processes use THPs.
2. If both steps show that Transparent Huge Pages are activated or in use, deactivate them by executing the
commands below in the Linux shell:
a. echo never > /sys/kernel/mm/transparent_hugepage/enabled
b. cat /sys/kernel/mm/transparent_hugepage/enabled
The rst command will deactivate Transparent Huge Pages by setting the relevant Kernel parameter to
"never". Right after executing this command, the hanging situation will be resolved. You can verify whether
the Kernel parameter has the correct value by executing the second command which should show the
output "always madvise [never]" where the new value is in square brackets.
3. Note that unless the value of the Kernel parameter has not been persisted, it is only set/valid until the host
is restarted the next time. To prevent toggling the value from [never] back to [always] causing THPs to be
activated again, use one of the below strategies to persist it:
a. Add the parameter "transparent_hugepage=never" to the kernel boot line in the /etc/grub.conf le
of the Bootloader.
b. Integrate the parameter "transparent_hugepage=never" within your system boot scripts (for
example,. /etc/rc.local).
Related Information
SAP Note 2131662
SAP Note 1824819
SAP Note 1954788
SAP Note 2013638
SAP Note 2136965
3.17.2 CPU Power Saving
The Linux Kernel shipped with SUSE Linux Enterprise Server (SLES) 11 and Red Hat Enterprise Linux (RHEL) 6
versions certied for usage with SAP HANA contain a new cpuidle driver for recent Intel CPUs. This driver leads
to a dierent behavior in C-states switching and causes performance degradations.
Context
See the SAP Notes below for further reference:
● SAP Note 1824819 SAP HANA DB: Recommended OS settings for SLES 11 / SLES for SAP Applications 11
SP2
● SAP Note 1954788 SAP HANA DB: Recommended OS settings for SLES 11 / SLES for SAP Applications 11
SP3
146
P U B L I C
SAP HANA Troubleshooting and Performance Analysis Guide
Root Causes and Solutions

● SAP Note 2013638 SAP HANA DB: Recommended OS settings for RHEL 6.5
● SAP Note 2136965 SAP HANA DB: Recommended OS settings for RHEL 6.6
Procedure
1. Check if the recommended driver is enabled and whether the CPU power safe mode is activated. Execute
the following command as root user in the Linux shell:
cat /sys/devices/system/cpu/cpuidle/current_driver
The correct value for the cpuidle driver should be "acpi_idle". If so, no further steps are required. In case
the output shows the wrong value "intel_idle", follow the steps in SAP Notes.
2. Check the CPU power save mode by running the following command:
cat /sys/devices/system/cpu/cpu*/cpufreq/scaling_governor
The correct value for the CPU power save mode should be "performance". If the output shows at least one
line with "ondemand", follow the steps in SAP Note 1890444 - Slow HANA system due to CPU power save
mode.
Related Information
SAP Note 1824819
SAP Note 1954788
SAP Note 2013638
SAP Note 2136965
SAP Note 1890444
3.18 Troubleshoot System Replication
This section describes how to analyze, avoid and solve problems related to system replication.
The following topics are covered:
● Performance: system replication appears to slow down transaction processing
● Setup and initial conguration problems
● Intermittent connectivity problems
● Managing the size of the log le with logreplay.
SAP HANA Troubleshooting and Performance Analysis Guide
Root Causes and Solutions
P U B L I C 147

Further Resources
System Replication is described in detail in the SAP HANA Administration Guide. Additionally, the following set
of documents including illustrated step-by-step procedures is available on the SAP Community Portal:
● SAP HANA – High Availability
● FAQ: High Availability for SAP HANA
● SAP HANA – Host Auto-Failover
● How To Perform System Replication for SAP HANA 2.0
● Network Recommendations for SAP HANA System Replication
● How To Congure Network Settings for SAP HANA System Replication
The two FAQ SAP Notes listed here relate to High Availability and Replication:
Related Information
SAP Note 2057595
SAP Note 1999880
SAP HANA Administration Guide
3.18.1 Replication Performance Problems
If system replication appears to slow down transaction processing, you can check the network and disk I/O on
the secondary site.
A slow-down related to system replication can occur in the following scenarios:
● ASYNC replication mode is congured over long distances;
● multi-tier system replication is congured and a tier 3 system is attached;
● SYNC/SYNCMEM replication mode is congured over short distances.
The following troubleshooting steps can help you determine and resolve the underlying cause.
Check If Log Can Be Shipped in Time
You can check the system replication KPI values to analyze the problem and verify that it is really related to
system replication:
● check if log shipping is signicantly slower than local log write (SYNC/SYNCMEM)
● check Async Buer Full Count (ASYNC)
You can check system replication KPIs in SAP HANA cockpit (see Monitoring SAP HANA System Replication in
the SAP HANA Administration Guide). You can also get an overview of basic system replication KPIs by running
the query HANA_Replication_SystemReplication_Overview_*_MDC.txt (from SAP KBA 1969700). This query is
148
P U B L I C
SAP HANA Troubleshooting and Performance Analysis Guide
Root Causes and Solutions

based on the system view M_SERVICE_REPLICATION and can be used to compare log shipping time to local
log write time. For synchronous replication the following KPIs are shown:
Example output of SQL Statement HANA_Replication_SystemReplication_Overview.txt
KEY VALUE
Replication mode SYNC
Secondary connect time 2016/10/18 14:02:36
Days since secondary connect time 1.26
Used persistence size (GB) 205.76
Log backup size / day (GB) 83.58
Local log buer write size (MB) 101130.54
Shipped log buer size (MB) 100258.52
Avg. local log buer write size (KB) 6.14
Avg. shipped log buer size (KB) 6.14
Avg. local log buer write time (ms) 0.13
Avg. log buer shipping time (ms) 0.24
Local log buer write throughput (MB/s) 44.68
Log buer shipping throughput (MB/s) 24.99
Initial data shipping size (MB) 0.00
Initial data shipping time (s) 0.00
Last delta data shipping size (MB) 2736.00
Last delta data shipping time (s) 13.00
Delta data shipping size (MB) 758704.00
Delta data shipping time (s) 3538.20
Delta data shipping throughput (MB/s) 214.43
Delta data shipping size / day (MB) n/a
Replication delay (s) 0.00
The following KPIs are of particular importance, the shipping time should not be signicantly higher than the
local write time:
● Avg. local log buer write time (ms)
SAP HANA Troubleshooting and Performance Analysis Guide
Root Causes and Solutions
P U B L I C 149

● Avg. log buer shipping time (ms)
You can see a graphical comparison of these local and shipped values in the cockpit System Replication
Overview (Network tab). The graph displayed compares the local write wait time with the remote write wait
time monitored over the last 24 hours:
For asynchronous replication scenarios the redo log is written into an Asynchronous Log Buer, which
occasionally can run full in case the logs are not shipped in a timely manner to the secondary instance. This can
lead to a performance overhead on the primary site as by default it waits with new COMMITS until there is free
space in the buer. This can be avoided by setting the parameter
logshipping_async_wait_on_buffer_full in the system_replication section of the global.ini le to
FALSE.
Note
In order to maintain a stable connection during the initial data shipment this parameter should be set to
true. This is recommended because if the log shipping connection is reset for any reason the data shipment
connection is also reset and the initial data shipment has to start again from the beginning. In multi-tier
scenarios a restarted full data shipment from primary to secondary site also results in a completely new full
data shipment to a tertiary site. For the duration of the initial shipment, therefore, you may also increase
the value of the logshipping_timeout parameter on the primary which has a default value of 30
seconds.
The size of the asynchronous log shipping buer on the primary site is normally adequate; the default value of
the logshipping_async_buffer_size parameter is 256MB for the indexserver (in the indexserver.ini) and
64MB for all other services (maintained in the global.ini). However, if additional free memory is available this
value can also be increased for specic services with a high log generation (such as the indexserver). You
should make such changes only in the service-specic ini les rather than in the global.ini le.
Once the asynchronous replication connection is established you can see how much is in the async buer by
checking the value of BACKLOG_SIZE in the system view M_SERVICE_REPLICATION. If there is no connection
this column shows the number of log entries that have been generated on the primary but which have not yet
150
P U B L I C
SAP HANA Troubleshooting and Performance Analysis Guide
Root Causes and Solutions

reached the secondary. You can also see this information (the backlogSize) by running the following command
on the primary with admin rights:
hdbcons ‘replication info’
- backlogSize : 2781184 bytes
For further details of the most common performance issues caused by system replication and under which
circumstances they occur, please refer to SAP KBA 1999880 - FAQ: SAP HANA System Replication.
Check If Data Load Can Be Handled by Network Link
To estimate the required bandwidth for Data/Log shipping, use
HANA_Replication_SystemReplication_Bandwidth.txt (from SAP Note 1069700), which is based on the I/O
statistics from the primary site. We recommend executing this SQL statement when system replication is
disabled. The data returned will help you to estimate the amount of data/log shipped from the primary site and
compare this to the available bandwidth.
You can also do a network performance test using, for example, the open source IPERF tool or similar, to
measure the real application network performance. The recommended bandwidth is 10 Gbit/s.
If the network bandwidth is not adequate you can activate data and log compression which signicantly
reduces the shipment size by setting the following parameters in the system_replication section of
global.ini:
● enable_log_compression = TRUE
● enable_data_compression = TRUE
Check Network Conguration (Long Distance)
Increasing the TCP window size can result in better network utilization and higher throughput. If the bandwidth
can handle load, check if the network is shared and whether other applications may be interfering with
performance. Collect network information on bandwidth and latency from the Linux kernel parameters as
described here. For these values refer also to SAP Note 2382421 - Optimizing the Network Conguration on
HANA and OS-Level (Linux Kernel Parameters) :
● Check the network utilization prole for the network link to see if the maximum capacity of the network has
been reached.
● If the network is not fully utilized, check the linux kernel TCP conguration with sysctl –a | egrep
“net.core|net.ipv4.tcp” .
● Check that window scaling is set to the default value of 1. net.ipv4.tcp_window_scaling = 1.
● Check whether the max size can be increased for net.ipv4.tcp_wmem and net.ipv4.tcp_rmem.
● Calculate the Bandwidth Delay Product (BDP): Bandwidth * Latency (for example, BDP = 50ms * 3 Gbps =
19.2 MB). The BDP tells you what TCP window size is needed to use the network link fully.
SAP HANA Troubleshooting and Performance Analysis Guide
Root Causes and Solutions
P U B L I C 151

Check Disk I/O on a Secondary Site
Slow disk I/O on the secondary can postpone releasing log buers on the primary, which results in wait
situations on the primary. You can do the following:
● Use a Disk Performance Test Tool
Execute fsperf on log volume, for example:
$ fsperf /usr/sap/TST/SYS/global/hdb/log/mnt00001/hdb00002
● Check the Monitoring and Administration area
If SQL is not available, use command line tools (this has to be done for each individual service), for
example:
$ hdbcons "statreg print -n M_VOLUME_IO_TOTAL_STATISTICS -h"
A runtime dump also contains I/O statistics, which you can see with: $ hdbcons “runtimedump dump”.
Caution
Technical expertise is required to use hdbcons. To avoid incorrect usage, use hdbcons only with the
guidance of SAP HANA development support.
● Check I/O relevant tables in the proxy schema of the corresponding secondary site, which provide SQL
access on the primary site on statistic views of the secondary. For more information, see Monitoring
Secondary Sites in the SAP HANA Administration Guide.
Related Information
SAP Note 1969700
SAP Note 1999880
SAP Note 2382421
Monitoring Secondary Systems
Monitoring SAP HANA System Replication with the SAP HANA Cockpit
3.18.2 Setup and Initial Conguration Problems
This section outlines the analysis steps you need to take in case you face conguration problems during the
initial HANA System Replication Setup.
The initial SAP HANA System Replication Setup steps are as follows:
● enabling the SAP HANA System Replication on the primary site with sr_enable
● registering the secondary system with sr_register
While there are no errors to be expected when you enable the primary site, the registration operation on the
secondary site can fail due to various errors.
152
P U B L I C
SAP HANA Troubleshooting and Performance Analysis Guide
Root Causes and Solutions

Note
If you are in the process of setting up HANA System Replication for the rst time, please make sure you
have met all the prerequisites and performed the necessary preparation steps, outlined in the SAP HANA
Administration Guide.
Pay special attention to the following points:
● Are the primary and secondary sites architecturally identical?
● Are the network interface congurations identical on both sites? (refer to the SCN document How to
Congure Network Settings for HANA System Replication for details).
● Are the ports needed for system replication open and reachable from the primary and the secondary
site?
Wrong Topology Information
Upon registering the secondary site, the following error is raised:
Output Code
> hdbnsutil -sr_register
--remoteHost=primary_host --remoteInstance=<primary_instance_no> --
mode=<replication_mode>
--name=<logical_site_name>
adding site ...
checking for inactive nameserver ...
nameserver primary_host:3xx01 not responding.
collecting information ...
error: source system and target system have overlapping logical hostnames;
each site must have a unique set of logical hostnames.
hdbrename can be used to change names;
failed. trace file nameserver_primary_host.00000.000.trc may contain more
error details.
The root cause for those issues is usually a wrong topology information. In this case, the secondary site
contained the following landscape denition in the nameserver.ini:
Sample Code
[landscape]
id = <id>
master = <secondary_host>:3xx01
worker = <primary_host>
active_master = <secondary_host>:3xx01
roles_<primary_host> = worker
The worker property contained the hostname of the primary site, which was wrong. Therefore, the registration
failed. The problem should disappear once the correct hosts are maintained in the master and worker (if any)
properties. You need to check on both sites if the information maintained in the nameserver topology is
consistent.
SAP HANA Troubleshooting and Performance Analysis Guide
Root Causes and Solutions
P U B L I C 153

Resyncing the Secondary: Persistence Compatibility Checks
If the primary and secondary systems are disconnected for any reason, they must be resynced. If the
persistencies (that is, the data and log volume snapshots) of the primary and secondary are compatible, it is
possible to achieve a resync with only a delta data shipment or a log shipment; in this case full data shipping is
not necessary. Even if the data snapshots are not compatible, the system will automatically attempt a full data
shipment (Resync Optimization). If necessary, a full data shipment can be triggered manually using the
following command:
hdbnsutil -sr_register --force_full_replica
Trace messages related to persistence which indicate that this is necessary include the following:
● Secondary persistence is not compatible with primary persistence.
● The persistence of at least one service is not initialized correctly.
Communication Problems with the Primary Site
The sr_register command on the secondary site is failing with:
Output Code
> hdbnsutil -sr_register --name=<logical_site_name> --
remoteHost=<primary_host --remoteInstance=<primary_instance_no> --
mode=<replication_mode> --force_full_replica --sapcontrol=1
unable to contact primary site host <primary_host>:3xx02. connection
refused,location=<primary_host>:3xx02
Possible Root Cause 1: Ports Not Open / Blocked by Firewall
This error usually indicates a general communication problem between the primary and secondary site. Mostly,
this is caused by the primary host not listening on the required ports for various reasons. You can check
whether the required ports 3<instance_number>01 and 3<instance_number>02 (non-MDC scenarios) or
4<instance_number>02 (MDC scenarios) are listening on the required interfaces with the following
command on OS level as privileged user (for example, root):
>netstat –apn | grep 3<instance_no>02
>netstat –apn | grep 4<instance_no>02
If you see that these ports are open and listening on the localhost interface only, you will not be able to reach
them from the secondary site. You need to adjust the settings for listeninterface in the global.ini le
from .local to .global:
Sample Code
[communication]
listeninterface=.global
154
P U B L I C
SAP HANA Troubleshooting and Performance Analysis Guide
Root Causes and Solutions

With this setting, the following interface:port pairs should be visible in netstat:
Note
If the ports are open, check whether they are not ltered by your rewall. Often it is not sucient to check
the connectivity to remote hosts via ping, because ping uses the ICMP protocol for communication. You
can easily verify the accessibility of remote hosts by issuing a telnet call. For example:
>telnet <primary_host> 30001
>telnet <primary_host> 30102
Possible Root Cause 2: SSL-Related Problems
Another cause for this error could be a wrongly implemented SSL conguration.
Note
If you do not secure the HANA network with SSL, do not implement any parameter changes related to SSL.
This can be revealed by activated corresponding traces on the primary site via SAP HANA cockpit:
● Database Explorer Trace Conguration Database Trace Search for “sr_nameserver” Change from
INFO to DEBUG OK
● Database Explorer Trace Conguration Database Trace Search for “trexnet” Change from ERROR
to INFO OK
Alternatively, the traces can be activated in the SQL console by issuing the following statements as a SYSTEM
user:
Source Code
alter system alter configuration ('indexserver.ini','SYSTEM') SET
('trace','sr_nameserver')='debug' with reconfigure;
alter system alter configuration ('indexserver.ini','SYSTEM') SET
('trace','trexnet')='info' with reconfigure;
After the trace activation, the registration problem needs to be reproduced by re-running the sr_register
command on the secondary. The nameserver trace on the primary site would reveal the following errors in the
CommonCrypto Engine:
Output Code
Crypto/SSL/CommonCrypto/Engine.cpp:563: SSL handshake failed: SSL error
[536871970]: Unknown error, General error: 0x20000422 | SAPCRYPTOLIB |
SSL_accept
SSL API error
Version in SSLPlaintext.version field of currently received record differs
from
the one negotiated in the current or currently accomplished handshake.
SAP HANA Troubleshooting and Performance Analysis Guide
Root Causes and Solutions
P U B L I C 155

0xa060023c | SSL | ssl3_accept
Version in SSLPlaintext.version field of currently received record differs
from
the one negotiated in the current or currently accomplished handshake.
0xa060023c | SSL | ssl3_get_record
Version in SSLPlaintext.version field of currently received record differs
from
the one negotiated in the current or currently accomplished handshake.
(ErrCode: 536871970)
Make sure the following parameters are consistent on both sites in the conguration le global.ini:
Sample Code
[communication]
ssl = systempki
..
...
[system_replication_communication]
enable_ssl = on
You need to ensure that the SSFS key and data les are stored on both sites. The following les must exist on
both sites:
$DIR_INSTANCE/../global/security/rsecssfs/data/SSFS_<SID>.DAT
$DIR_INSTANCE/../global/security/rsecssfs/data/SSFS_<SID>.KEY
Possible Root Cause 3: Wrong Conguration of the Internal Hostname Resolution
Parameters
Please check whether the internal hostname resolution information is consistent on both sites. The following
how-to guides are a good source of information:
● How to Congure Network Settings for SAP HANA System Replication
● How to Perform System Replication for SAP HANA.
Possible Root-Cause 4: Wrong MTU Size Congured
A closer look at the nameserver trace le on the secondary site would reveal:
Output Code
error: unable to contact primary site; to <primary_host_ip> (<primary_host>):
3xx01; original error: timeout occured,location=<primary_host_ip> :3xx02. Was
MTU size set to 1500? (https://css.wdf.sap.corp/sap/support/notes/2142892);
This problem is discussed in full detail in SAP Note 2166157 - Error: 'failed to open channel ! reason: connection
refused' when setting up Disaster Recovery.
Possible Root Cause 5: HANA Service Unavailability
Check the availability of the indexserver / nameserver process on the primary site. Often the services faced an
intermittent restart, crash or reconguration which did not go unrecognized by the secondary site.
156
P U B L I C
SAP HANA Troubleshooting and Performance Analysis Guide
Root Causes and Solutions

Related Information
SAP HANA Administration Guide
Congure Tracing in the SAP HANA Database Explorer
How to Perform System Replication for SAP HANA
How to Congure Network Settings for SAP HANA System Replication
SAP Note 2166157
3.18.3 Intermittent Connectivity Problems
This section discusses the mitigation strategies for sporadic network interruptions causing problems in the
SAP HANA System Replication mechanism.
A common intermittent error is that the log buer is not shipped in a timely fashion from the primary to the
secondary site.
Log Shipping Timeout
Possible Root Cause 1: Log Area Is Full on the Secondary Site
If the System Replication Mode is set to SYNC – full sync, the commits on primary are halted as nothing
can be written to the log area on secondary site any longer. On the secondary site, the trace les contain the
following error:
Output Code
i EventHandler LocalFileCallback.cpp(00455) : [DISKFULL] (1st request) [W] ,
buffer= 0x00007f7eef8ae000, offset= 589299712, size= 0/524288, file= "<root>/
logsegment_000_00000508.dat
" ((open, mode= RW, access= rw-rw-r--, flags= DIRECT|LAZY_OPEN), factory=
(root= "/hana/log/<SID>/mnt00001/hdb00003/" (access= rw-rw-r--, flags=
AUTOCREATE_DIRECTORY, usage= LOG, fs= xfs,
config=
(async_write_submit_active=auto,async_write_submit_blocks=new,async_read_submi
t=off,num_submit_queues=1,num_completion_queues=1,size_kernel_io_queue=512,max
_parallel_io_requests=64,
min_submit_batch_size=16,max_submit_batch_size=64))) {shortRetries= 0,
fullRetries= 0 (0/10)}
To quickly mitigate the situation, you can disable the “full sync” option by running the following command:
>hdbnsutil -sr_fullsync --disable
Afterwards, the log area on the secondary site needs to be analyzed with regard to why the log segments are
not freed up. This is usually caused by an erroneous log backup mechanism.
SAP HANA Troubleshooting and Performance Analysis Guide
Root Causes and Solutions
P U B L I C 157

For further details refer to the following SAP Notes:
SAP Note 2083715 - Analyzing log volume full situations
SAP Note 1679938 - Log Volume is full
Possible Root Cause 2: Sporadic Communication Issues on the Network Layer
For more information about how to deal with communication problems between the primary and the
secondary site, see SAP HANA System Replication Communication Problems.
Related Information
SAP Note 2083715
SAP Note 1679938
SAP HANA System Replication Communication Problems [page 166]
3.18.4 LogReplay: Managing the Size of the Log File
There is a risk in replication scenarios which use one of the logreplay operation modes of causing a disk full
situation on the primary if the secondary system is not available for any reason; this can potentially lead to a
complete freeze of the database.
The logreplay modes (logreplay introduced in HANA 1.0 SPS10 and logreplay_readaccess introduced in HANA
2) require a log history on the primary so that a secondary system can be resynchronized without the need for
a full data shipment. As long as a secondary system is registered the log le will continue to grow. When the
secondary system synchronizes, then the log is automatically cleared down. However, if the replication
environment changes, if for example, the secondary is separated because of network problems, manual
intervention may be required to manage the log le or, in the worst case scenario, to recover from a disk full
situation. This problem can also happen on a secondary system where a takeover has occurred.
The log replay modes are described in detail in the SAP HANA Administration Guide section System Replication
With Operation Mode Logreplay. This section of the SAP HANA Troubleshooting and Performance Analysis
Guide describes procedures to rstly prevent problems from occurring and secondly to resolve a disk full
situation.
Log File Retention (RetainedFree Status)
If the secondary cannot be synchronized for any reason, then log segments continue to be written but are
marked as RetainedFree. You can check for RetainedFree log segments either in SAP HANA cockpit or from the
command line.
158
P U B L I C
SAP HANA Troubleshooting and Performance Analysis Guide
Root Causes and Solutions

1) To check using SAP HANA cockpit, start from the Disk Usage app and open Monitor Disk Volume. The
graph shows usage for log and data volumes; you can lter the display for a specic volume and server (for
example indexserver). Check the State column of the log les for RetainedFree log segments as shown here:
2) To check using the command line, execute the following command as <sid>adm for a specic log volume
(hdb00003 in this example – the log volume of one indexserver):
#>hdblogdiag seglist $DIR_INSTANCE/../SYS/global/hdb/log/mnt00001/hdb00003
The result shows details of each log segment including status information. Look for any segments with status
RetainedFree as shown here:
LogSegment[0/2:0xec98740-0xecb6000(0x763000B)/
GUID=759DC14B-00D7-20161122-134436-39A00002ED/
PrevGUID=759DC14B-00D7-20161122-134436-39A00002EC,TS=2016-11-30
06:55:18.008741,Hole=0xec98740/
RetainedFree/0x0]@0x00007f34cb32a010
How to Avoid Log Full Situations
Unregister an Unused Secondary
If the secondary is disconnected for a prolonged period and if it is not to be used as a replication server
anymore, then unregister the secondary site and disable the primary functionality. This will stop the
RetainedFree log entries from being written:
1. Unregister the secondary; this is normally done from the secondary site but can be done from the primary
if the secondary is not available anymore:
hdbnsutil –sr_unregister
SAP HANA Troubleshooting and Performance Analysis Guide
Root Causes and Solutions
P U B L I C 159

2. Disable the primary (from the primary site):
hdbnsutil –sr_disable
3. Execute recongure on the primary site:
hdbnsutil –reconfig
You can use this same procedure for a primary which, after a takeover, will no longer be used for failback.
Set a Maximum Retention Size
Another option to manage the log size is to set a value for the logshipping_max_retention_size
parameter. If the log size reaches this limit, then RetainedFree log entries will be overwritten. Note the following
points in this case:
● If any RetainedFree log entries are lost, then synchronization by logreplay will no longer be possible and a
full data shipment will be necessary to resynchronize the secondary.
● It is not possible to switch back to delta mode to resynchronize - only a full data shipping is possible.
Tip
As a further general precaution, to prevent any disk full situation from arising you can reserve a portion of
the disk with an emergency placeholder le (containing any dummy values), for example, occupying 5 –
10 % of the le system. This le can then be deleted if ever necessary to quickly solve disk full situations.
How to Recover From Log Full Situations
Secondary Has Been Taken out of Service
If the secondary has been permanently taken out of service, then these log entries will never be required. In this
case the secondary can be unregistered and the log volume cleaned up:
1. Unregister the secondary (same steps as previous subsection: unregister, disable and recongure).
2. Delete the Free marked log segments from the command line for each of the persistent relevant services
(nameserver, indexserver, xsengine, …). To do this run hdbcons with the log release parameter as
<sid>adm. In a multi-database system the -p switch is required with the process ID of the service (such as
indexserver):
hdbcons –p <PID_of_service> “log release”
Secondary Still Required
If the secondary is still required, then restart it and allow it to resynchronize. When this has completed, the
RetainedFree log segments on the primary will be marked as Free, you can then clean up the log as described
above by running hdbcons with the log release parameter.
Log Full Has Caused Complete Database Freeze
If the log full has caused a complete database freeze, you can try to move the log to another linked le system
and replay the log from there. Essentially, this is a three step procedure, refer to SAP Note 1679938 Log Volume
is full for complete details:
● Stop the primary system.
● Mount the log volumes of the primary via symbolic link to another le system.
● Start the primary and the secondary and allow them to resynchronize.
160
P U B L I C
SAP HANA Troubleshooting and Performance Analysis Guide
Root Causes and Solutions

When this has completed, you can then clean up the log by running hdbcons with the log release parameter
as described above.
Related Information
SAP Note 1679938
3.19 Network Performance and Connectivity Problems
This section covers the troubleshooting of problems on the network layer.
In cases where a subjectively slow performing system behaviour is experienced, but a rst analysis of the SAP
HANA resource utilization does not reveal any obvious culprits, it is often necessary to analyze the network
performance between the SAP HANA server host(s) and SAP Application Server(s) / Non-ABAP clients, SAP
HANA nodes (inter-node communication in SAP HANA scale-out environments), or, in an SAP HANA system
replication scenario, between primary and secondary site.
3.19.1 Network Performance Analysis on Transactional Level
The following section should help you to perform an in-depth investigation on the network performance of
specic clients.
Prerequisites
SYSTEM administrator access using SAP HANA cockpit or hdbsql.
Procedure
1. Use the monitoring view M_SQL_CLIENT_NETWORK_IO to analyse gures about client and server elapsed
time as well as message sizes for client network messages.
Sample Code
SELECT * FROM M_SQL_CLIENT_NETWORK_IO
In case a long execution runtime is observed on the application server side and the corresponding
connections on the SAP HANA side do not show expensive operations, an overview of the total processing
SAP HANA Troubleshooting and Performance Analysis Guide
Root Causes and Solutions
P U B L I C 161

time spent on client side and SAP HANA server side can be retrieved by executing the above SQL query. By
default, collection of statistics related to client network I/O is regulated by the following parameter
sql_client_network_io in the indexserver.ini le, which must be set to on (true).
Please note that this parameter change implies a certain performance overhead and should only be active
for the duration of the troubleshooting activity.
An example result of the above mentioned query is shown here:
CLIENT_DURATION and SERVER_DURATION contain the values in microseconds. The dierence between
CLIENT_DURATION and SERVER_DURATION makes the total transfer time of the result
(SEND_MESSAGE_SIZE in bytes). This allows you to see whether the transfer time from the SAP HANA
server to the client host is exceptionally high.
2. Run SQL: “HANA_Network_Clients” from the SQL statement collection attached to SAP Note 1969700.
Another important KPI is the Round Trip Time (RTT) from server to client. In order to analyze this gure the
SQL statement "HANA_Network_Clients" from the collection attached to SAP Note 1969700 can be used.
As this SQL statement is using the view M_EXPENSIVE_STATEMENTS, the expensive statements trace
needs to be active in the
SAP HANA database explorer Trace Conguration :
Once the trace is activated and the long-running statements are re-executed, the information to be
extracted from the M_EXPENSIVE_STATEMENTS view is STATEMENT_HASH:
162
P U B L I C
SAP HANA Troubleshooting and Performance Analysis Guide
Root Causes and Solutions

With the Statement Hash '7c4a13b071f030f1c0d178ab9cf82c37' (please note that this one is only an
example statement hash) of the SQL statement to be analyzed, the SQL “HANA_Network_Clients” can be
modied in a way that a corresponding Statement Hash is used to restrict the selection:
Sample Code
…
SELECT /* Modification section */
TO_TIMESTAMP('1000/01/01 18:00:00', 'YYYY/MM/DD HH24:MI:SS')
BEGIN_TIME,
TO_TIMESTAMP('9999/12/31 18:10:00', 'YYYY/MM/DD HH24:MI:SS')
END_TIME,
'%' HOST,
'%' PORT,
'%' SERVICE_NAME,
'%' CLIENT_HOST,
'7c4a13b071f030f1c0d178ab9cf82c37' STATEMENT_HASH,
.
.
.*/
FROM
DUMMY
Which provides the following result:
The KPI AVG_RTT_MS is of importance and should not show values signicantly higher than ~ 1,5 ms.
3. For further options, please refer to SAP KBA 2081065.
Related Information
SAP Note 2081065
SAP Note 1969700
3.19.2 Stress Test with NIPING
The SAP NIPING tool is a powerful tool which can be used to perform specic network stability tests.
Prerequisites
You must have OS level access to the SAP HANA host and the client host.
SAP HANA Troubleshooting and Performance Analysis Guide
Root Causes and Solutions
P U B L I C 163

Procedure
Read SAP Note 500235 - Network Diagnosis with NIPING.
A stress test with SAP's NIPING tool may be performed in order to conrm the high network latency (or
bandwidth exhaustion).
Related Information
SAP Note 500235
3.19.3 Application and Database Connectivity Analysis
There are a number of ways to identify possible root causes for network communication issues between your
application and the SAP HANA instance it is connecting to.
Prerequisites
You have access to both the application and SAP HANA instance.
Procedure
1. On an ABAP application server, check the following:
a. Run transaction OS01 - Database - Ping x10
If a connection to the database cannot be established over a longer period of time by an SAP ABAP
application work process, the work process is terminated. First, the work process enters the reconnect
state in which it constantly tries to connect to the database, after a predened amount of retries fail,
the work process terminates. In this case the connectivity from the SAP application server to the SAP
HANA server must be veried.
b. Run transaction SE38 - Report ADBC_TEST_CONNECTION
If a specic database connection is failing, the report ADBC_TEST_CONNECTION oers a connectivity
check for each dened database connection.
c. Check for common errors in SAP KBA 2213725 - How-To: Troubleshooting of -10709 errors
If an application is facing communication issues with the SAP HANA server, on client side the
connectivity issue may be indicated by several 10709-errors, mostly short dumps. The error 10709 is
generic but the error text of the short dumps contains the error information that was returned by the
server. Some root causes may be found in unfavorable parameter settings, either on client or on server
side, some may be caused by a faulty network.
164
P U B L I C
SAP HANA Troubleshooting and Performance Analysis Guide
Root Causes and Solutions

In most cases, a short dump with characteristics is raised:
Sample Code
Category Installation Errors
Runtime Errors DBSQL_SQL_ERROR
Except. CX_SY_OPEN_SQL_DB
The "Database error text" gives you a rst hint as to what might have caused the issue. For an overview
of the most common errors in this context and detailed explanations of how to resolve them, see SAP
KBA 2213725 - How-To: Troubleshooting of -10709 errors.
2. On non-ABAP applications, check the following SAP Notes and documentation references:
a. SAP Note 1577128 - Supported clients for SAP HANA
On non-ABAP client connections check that the client you are using is supported.
b. Section Troubleshooting: ODBC Tracing in the SAP HANA Client Interface Programming Reference
A typical SAP HANA ODBC connection failure is indicated by an error with the following prex:
Sample Code
[LIBODBCHDB SO][HDBODBC]....
The most common errors are documented in SAP Notes and KBAs. You can use the search features of
the Support portal to nd a solution for a specic error. If no specic SAP Note is available, you can
record an ODBC trace to gain more detailed insight.
c. SAP KBA 2081065 - Troubleshooting SAP HANA Network
If the error occurs sporadically, it is useful to perform a long-term stress test between the client and
SAP HANA server to conrm the network's stability. For more information, see SAP Note 500235. To
examine the exact trac from the TCP/IP layer, a tcpdump can be recorded which shows what packets
are sent and received and which packets were rejected or required a retransmission.
3. Generic Smart Data Access troubleshooting steps are:
a. To verify that the issue might not be a aw in the SAP HANA cockpit, always try to connect via the 'isql'
tool on the SAP HANA host directly as the SAP HANA<sid>adm.
b. Make sure all libraries can be accessed on OS level by the SAP HANA <sid>adm user (PATH
environment variable).
c. In the SAP HANA <sid>adm home directory (cd $home) check that the correct host and port, and
username and password combinations are used in the .odbc.ini le.
d. Check that the LD_LIBRARY_PATH environment variable of the SAP HANA <sid>adm user contains
the unixODBC and remote DB driver libraries.
For example, with a Teradata setup, the LD_LIBRARY_PATH should contain the following
paths: .../usr/local/unixODBC/lib/:/opt/teradata/client/15.00/odbc_64/lib...
Connections from the SAP HANA server to remote sources are established using the ODBC interface
(unixODBC). For more information, see the SAP HANA Administration Guide.
4. Microsoft SQL Server 2012 - Specic Smart Data Access Troubleshooting
a. Make sure unixODBC 2.3.0 is used. A higher version leads to a failed installation of the Microsoft ODBC
Driver 11 for SQL Server 2012.
SAP HANA Troubleshooting and Performance Analysis Guide
Root Causes and Solutions
P U B L I C 165

b. The version can be veried with the following command executed as the SAP HANA <sid>adm user
on the SAP HANA host: isql --version.
c. You can also refer to the Guided Answers tree Troubleshooting Smart Data Access (SDA) Conguration.
5. Teradata - Specic Smart Data Access Troubleshooting
a. Check SAP KBA 2078138 - "Data source name not found, and no default driver specied" when
accessing a Teradata Remote Source through HANA Smart Data Access.
Under certain circumstances it is necessary to adjust the order of the paths maintained in
LD_LIBRARY_PATH.
Related Information
SAP Note 2213725
SAP Note 1577128
SAP Note 2081065
SAP Note 500235
SAP Note 2078138
ODBC Tracing and Trace Options
SAP HANA Administration Guide
Troubleshooting Smart Data Access (SDA) Conguration (Guided Answer)
3.19.4 SAP HANA System Replication Communication
Problems
Problems during initial setup of the system replication can be caused by incorrect conguration, incorrect
hostname resolution or wrong denition of the network to be used for the communication between the
replication sites.
Context
System replication environments depend on network bandwidth and stability. In case communication
problems occur between the replication sites (for example, between SITE A and SITE B), the rst indication of a
faulty system replication setup will arise.
Procedure
1. Check the nameserver traceles.
166
P U B L I C
SAP HANA Troubleshooting and Performance Analysis Guide
Root Causes and Solutions

The starting point for the troubleshooting activity are the nameserver traceles. The most common errors
found are:
Sample Code
e TNS TNSClient.cpp(00800) : sendRequest dr_secondaryactivestatus to
<hostname>:<system_replication_port> failed with NetException.
data=(S)host=<hostname>|service=<service_name>|(I)drsender=2|
e sr_nameserver TNSClient.cpp(06787) : error when sending request
'dr_secondaryactivestatus' to <hostname>:<system_replication_port>:
connection broken,location=<hostname>:<system_replication_port>
e TrexNetBuffer BufferedIO.cpp(01151) : erroneous channel ### from #####
to <hostname>:<system_replication_port>: read from channel failed;
resetting buffer
Further errors received from the remote side:
Sample Code
Generic stream error: getsockopt, Event=EPOLLERR - , rc=104: Connection
reset by peer
Generic stream error: getsockopt, Event=EPOLLERR - , rc=110: Connection
timed out
It is important to understand that if those errors suddenly occur in a working system replication
environment, they are often indicators of problems on the network layer. From an SAP HANA perspective,
there is nothing that could be toggled, as it requires further analysis by a network expert. The investigation,
in this case, needs to focus on the TCP trac by recording a tcpdump in order to get a rough
understanding how TCP retransmissions, out-of-order packets or lost packets are contributing to the
overall network trac. How a tcpdump is recorded is described in SAP Note 1227116 - Creating network
traces. As these errors are not generated by the SAP HANA server, please consider consulting your in-
house network experts or your hardware vendor before engaging with SAP Product Support.
2. Set the parameter sr_dataaccess to debug.
In the DB Administration area of the SAP HANA cockpit open the Conguration of System Properties
monitor. In the [trace] section of the indexserver.ini le set the parameter sr_dataaccess = debug.
This parameter enables a more detailed trace of the components involved in the system replication
mechanisms. For more information about how to change parameters, see Memory Information from Logs
and Traces.
Related Information
SAP Note 1227116
Memory Information from Logs and Traces [page 23]
SAP HANA Troubleshooting and Performance Analysis Guide
Root Causes and Solutions
P U B L I C 167

3.19.5 SAP HANA Inter-Node Communication Problems
This section contains analysis steps that can be performed to resolve SAP HANA inter-node communication
issues.
Procedure
1. If communication issues occur between dierent nodes within an SAP HANA scale-out environment,
usually the SAP HANA traceles contain corresponding errors.
A typical error recorded would be:
Sample Code
e TrexNet Channel.cpp(00343) : ERROR: reading from channel ####
<IP_of_remote_host:3xx03> failed with timeout error; timeout=60000 ms
elapsed
e TrexNetBuffer BufferedIO.cpp(01092) : channel #### from : read from
channel failed; resetting buffer
To understand those errors it is necessary to understand which communication parties are aected by this
issue. The <IP:port> information from the above mentioned error already contains valuable information.
The following shows the port numbers and the corresponding services which are listening on those ports:
Sample Code
Nameserver 3<instance_no>01
Preprocessor 3<instance_no>02
Indexserver 3<instance_no>03
Webdispatcher 3<instance_no>06
XS Engine 3<instance_no>07
Compileserver 3<instance_no>10
Interpreting the above error message it is safe to assume that the aected service was failing to
communicate with the indexserver of one node in the scale-out system. Please note that these errors are
usually caused by network problems and should be analyzed by the person responsible for OS or network
or the network team of the hardware vendor.
2. In SAP HANA cockpit go to the Threads tile and check the column Thread Status for Network Poll, Network
Read, Network Write.
In case the Threads tile in the SAP HANA cockpit shows many threads with the state Network Poll, Network
Read or Network Write, this is a rst indication that the communication (Network I/O) between the SAP
HANA services or nodes is not performing well and a more detailed analysis of the possible root causes is
necessary. For more information about SAP HANA threads, see SAP KBA 2114710 - FAQ: SAP HANA
Threads and Thread Samples.
3. Run SQL: "HANA_Network_Statistics".
As of SAP HANA SPS 10 the view M_HOST_NETWORK_STATISTICS provides SAP HANA host related
network gures. The SAP HANA SQL statement collection from SAP Note 1969700 - SQL Statement
Collection for SAP HANA contains SQL: “HANA_Network_Statistics” which can be used to analyze the
network trac between all nodes within a SAP HANA scale-out system.
168
P U B L I C
SAP HANA Troubleshooting and Performance Analysis Guide
Root Causes and Solutions

Sample Code
---------------------------------------------------------------------------
----------
|HOST |SEG_RECEIVED |BAD_SEG_RCV|BAD_SEG_PCT|SEG_SENT |SEG_RETRANS|
RETRANS_PCT|
---------------------------------------------------------------------------
----------
|hostnam| 163965201| 282| 0.00017| 340922924|
19520| 0.00572|
---------------------------------------------------------------------------
----------
For a detailed documentation of the gures from this output, please refer to the documentation section of
the SQL statement SQL: “HANA_Network_Statistics”.
4. Run SAP HANA Conguration Mini Checks from SAP KBA 1999993 - How-To: Interpreting SAP HANA Mini
Check Results.
The "Network" section of the mini-check results contains the following checks:
Sample Code
---------------------------------------------------------------------------
-------------------
|CHID |DESCRIPTION |HOST |VALUE |
EXPECTED_VALUE|C|SAP_NOTE|
---------------------------------------------------------------------------
-------------------
|**** |NETWORK | |
| | | |
| | | |
| | | |
| 1510|Avg. intra node send throughput (MB/s) |hostnam|444 |>=
120 | | 2222200|
| 1512|Avg. inter node send throughput (MB/s) |hostnam|never |>=
80 | | 2222200|
| 1520|Retransmitted TCP segments (%) | |0.00571 |<=
0.10000 | | 2222200|
| 1522|Bad TCP segments (%) | |0.00017 |<=
0.01000 | | 2222200|
---------------------------------------------------------------------------
-------------------
The results usually contain an "expected value" (which provides a certain "rule of thumb" value) and a
"value" eld which represents the actual value recorded on the system. If the recorded value is breaching
the limitations dened by the expected value, the "C" column should be agged with an 'X'. You can then
check the note for this item referenced in the column SAP_NOTE.
Related Information
SAP Note 2114710
SAP Note 1969700
SAP Note 1999993
SAP HANA Troubleshooting and Performance Analysis Guide
Root Causes and Solutions
P U B L I C 169

3.20 SAP HANA Dynamic Tiering
Identify and resolve specic performance issues and enhance the performance of SAP HANA dynamic tiering.
Note
Troubleshooting information for SAP HANA dynamic tiering is in the SAP HANA Dynamic Tiering:
Administration Guide.
3.20.1 Tools and Tracing
This section gives you an overview of the tools and tracing options available for SAP HANA dynamic tiering.
3.20.1.1 Federation Trace
Federation trace can be turned ON to diagnose most issues with SAP HANA dynamic tiering.
Federation trace generates tracing information in the indexserver.ini trace le.
To enable federation trace:
ALTER SYSTEM ALTER CONFIGURATION ('indexserver.ini', 'SYSTEM') SET ('trace',
'fedtrace') = 'debug' WITH RECONFIGURE;
ALTER SYSTEM ALTER CONFIGURATION ('indexserver.ini', 'SYSTEM') SET ('trace',
'federationexecution') = 'debug' WITH RECONFIGURE;
3.20.2 Query Plan Analysis
The query plan shows the various operators involved in the query execution.
Queries referencing both SAP HANA tables and SAP HANA dynamic tiering tables are either:
● Executed in SAP HANA by pulling data from SAP HANA dynamic tiering
● Relocated to SAP HANA dynamic tiering, where the data is pulled from SAP HANA
Generally, since SAP HANA dynamic tiering involves tables with large amounts of data, it may be preferable to
use the latter strategy. Another reason to use the latter strategy is when the SAP HANA dynamic tiering table is
too large to t in SAP HANA.
If your query involves both SAP HANA tables and SAP HANA dynamic tiering tables and you are experiencing
poor performance, you should review the query plan. Review the visual query plan that shows the timings for
various sub-trees. Alternatively, you can query M_REMOTE_STATEMENTS to show timing results for query
fragments executed on SAP HANA dynamic tiering. If the timing shown is small, and you think the optimizer is
shipping the upper limit of query fragments, then SAP HANA dynamic tiering is probably not the cause of the
performance problem.
170
P U B L I C
SAP HANA Troubleshooting and Performance Analysis Guide
Root Causes and Solutions

The Remote Row Scan operator deals with a query fragment executed by an SAP HANA dynamic tiering
node. If this operator is directly under the top-level Project node, then the entire query has been either
pushed down or relocated to an SAP HANA dynamic tiering node. Generally, relocating the query yields better
performance.
Changing the Execution Strategy to Remote
If the execution strategy 'auto' mode is not yielding the best plan, try the following procedure to change the
execution strategy from 'auto' to 'remote':
1. Clear the query plan cache.
ALTER SYSTEM CLEAR SQL PLAN CACHE;
2. Change the execution strategy from 'auto' to 'remote':
ALTER SYSTEM ALTER CONFIGURATION ('esserver.ini', 'SYSTEM') SET
('row_engine', 'execution_strategies') = 'remote' WITH RECONFIGURE;
Changing the Execution Strategy to Auto
If the execution strategy is set to 'auto', then the optimizer chooses the best strategy for executing the query:
either relocating the query to SAP HANA dynamic tiering, or executing the query in SAP HANA. In most cases,
'auto' provides best performance.
1. Change the execution strategy from 'remote' to 'auto':
ALTER SYSTEM ALTER CONFIGURATION ('esserver.ini', 'SYSTEM') SET
('row_engine', 'execution_strategies') = 'auto' WITH RECONFIGURE;
If neither execution strategy improves performance, there may be a capability issue. The query optimizer
decides what to push down to SAP HANA dynamic tiering based on the capability supported by the option. If
the query deals with some operator, builtin, or other item that SAP HANA dynamic tiering does not understand,
then it lets the SAP HANA execution engine compensate for it. Review your query to see if there are any
unsupported operators, or builtins and see if you can rewrite the query without them. Finally, you may be
missing statistics on the tables that may prevent the optimizer from choosing an optimal query plan.
3.20.2.1 Statistics
Statistics help the query optimizer in choosing the right query plan. Missing statistics may prevent the query
optimizer from selecting the optimal query plan.
When no statistics for an extended table are present, the query optimizer assumes the table size to be 1 million
rows. If the actual table has signicantly dierent number of rows, then the query plan chosen may not be
optimal. To ensure that optimizer has the correct information, we recommend that you create statistics on the
extended tables.
SAP HANA Troubleshooting and Performance Analysis Guide
Root Causes and Solutions
P U B L I C 171
SAP HANA currently supports several types of statistics:
HISTOGRAM
Creates a data statistics object that helps the query optimizer estimate the data distribution
in a single-column data source. If you specify multiple columns in <data_sources>, then
multiple data statistics objects (HISTOGRAM) are created--one per column specied.
SIMPLE
Creates a data statistics object that helps the query optimizer calculate basic statistics, such
as min, max, null count, count, and distinct count for a single-column data source. If you
specify multiple columns in <data_sources>, then multiple data statistics objects are
created--one per column specied.
TOPK
Creates a data statistics object that helps the query optimizer identify the highest-frequency
values in a table data source. If you specify multiple columns in <data_sources>, then
multiple data statistics objects are created--one per column specied.
SKETCH
Creates a data statistics object that helps the query optimizer estimate the number of
distinct values in the data source. A data statistics object is created for the specied
<table_name>(<column-name>,...), which approximates the number of distinct tuples
in the projection of the table on the set of specied columns.
SAMPLE
Creates a sample of data from <data_source> that the SQL optimizer can use during
optimization. When benecial, the SQL optimizer generates system SAMPLE data statistics
objects automatically on column and row store tables. However, this behavior can incur a
cost to performance. You can avoid this cost by creating SAMPLE data statistics objects
explicitly (in advance). Creating them explicitly is especially useful in situations where
sampling live table data is expensive (for example, very large tables).
RECORD
COUNT
Creates a data statistics object that helps the query optimizer calculate the number of
records (rows) in a table data source. The RECORD COUNT type is a table-wide statistic. You
do not specify columns in <data_sources> when creating a RECORD COUNT data statistics
object. When benecial, the SQL optimizer maintains system RECORD COUNT data statistics
objects automatically on column and row store tables.
We recommend that simple statistics, at the very least, are present on key columns of extended tables.
3.20.3 Data Loading Performance
SAP HANA dynamic tiering supports all data loading methods for extended tables. This section explores the
various mechanisms for inserting data into extended tables, and recommends the optimal loading
mechanisms.
In general, SAP HANA dynamic tiering is optimized for batch writes, like SAP HANA. Singleton writes are not
the best use case for SAP HANA dynamic tiering, although singleton writes are supported.
172
P U B L I C
SAP HANA Troubleshooting and Performance Analysis Guide
Root Causes and Solutions

3.20.3.1 IMPORT FROM Statement
If you have a CSV le for the data to be loaded, the IMPORT FROM statement is by far the best method for
loading data into an SAP HANA dynamic tiering table.
The IMPORT FROM statement is sent directly to the SAP HANA dynamic tiering node for the data load.
Currently, IMPORT FROM does not support the THREADS parameter on the import command and hence it is
better to break the les into multiple les if you are planning on loading hundreds of millions of rows.
When dealing with a delta-enabled extended table, you can run these IMPORT FROM statements in parallel if
required. However, note that this will put heavy demand on the delta memory. Make sure delta memory is
appropriately congured. Alternatively, you can do this load serially.
When importing very large amounts of data into an extended table, use multiple les in the same IMPORT
FROM statement. Breaking into multiple les for IMPORT FROM yields better performance than a single le
import.
3.20.3.2 INSERT Statement with SELECT Statement
If the data is present in another SAP HANA table, then INSERT-SELECT is a better loading method than the
IMPORT FROM statement.
The query optimizer tries to relocate the INSERT-SELECT on an extended table to the SAP HANA dynamic
tiering node. The SAP HANA dynamic tiering node does a parallel fetch from SAP HANA, thereby speeding up
the INSERT-SELECT.
3.20.3.3 Parameterized Array Inserts
Array insert is by far the most optimal mechanism to load data into an extended table.
SAP HANA dynamic tiering converts an array-insert into a LOAD statement on the SAP HANA dynamic tiering
node.
Bulk load is controlled by the bulk_inserts_as_load and bulk_load_as_binary parameters. Both
parameters are 'true' by default.
If you need to re-enable the defaults:
1. Re-enable the bulk load mechanism for optimizing array inserts:
ALTER SYSTEM ALTER CONFIGURATION ('esserver.ini', 'SYSTEM') SET
('row_engine', 'bulk_inserts_as_load') = 'true' WITH RECONFIGURE;
2. Re-enable binary load (instead of the ASCII load):
ALTER SYSTEM ALTER CONFIGURATION ('esserver.ini', 'SYSTEM') SET
('row_engine', 'bulk_load_as_binary') = 'true' WITH RECONFIGURE;
SAP HANA Troubleshooting and Performance Analysis Guide
Root Causes and Solutions
P U B L I C 173

4 Tools and Tracing
This section gives you an overview of the available tools and tracing options that are available.
4.1 System Performance Analysis
As a rst step to resolving SAP HANA performance issues, you can analyze detailed aspects of system
performance in the SAP HANA studio on the Performance tab of the Administration editor.
When analyzing system performance issues, the information provided on the Performance tab enables you to
focus your analysis on the following questions:
● What and how many threads are running, what are they working on, and are any of these threads blocked?
● Are any sessions blocking current transactions?
● Are any operations running for a signicantly long time and consuming a lot of resources? If so, when will
they be nished?
● How do dierent hosts compare in terms of performance?
On the Performance tab, you can take certain actions to improve performance, including canceling the
operations that cause blocking situations.
4.1.1 Thread Monitoring
You can monitor all running threads in your system in the Administration editor on the Performance
Threads sub-tab. It may be useful to see, for example, how long a thread is running, or if a thread is blocked
for an inexplicable length of time.
Thread Display
By default, the Threads sub-tab shows you a list of all currently active threads with the Group and sort lter
applied. This arranges the information as follows:
● Threads with the same connection ID are grouped.
● Within each group, the call hierarchy is depicted (rst the caller, then the callee).
● Groups are displayed in order of descending duration.
On big systems with a large number of threads, this arrangement provides you with a more meaningful and
clear structure for analysis. To revert to an unstructured view, deselect the Group and sort checkbox or change
the layout in some other way (for example, sort by a column).
174
P U B L I C
SAP HANA Troubleshooting and Performance Analysis Guide
Tools and Tracing

Thread Information
Detailed information available on the Threads sub-tab includes the following:
● The context in which a thread is used
This is indicated by the thread type. Important thread types are SqlExecutor and PlanExecutor.
SqlExecutor threads handle session requests such as statement compilation, statement execution, or
result fetching issued by applications on top of SAP HANA. PlanExecutor threads are used to process
column-store statements and have an SqlExecutor thread as their parent.
Note
With revision 56, PlanExecutor threads were replaced by JobWorker threads.
Note
The information in the Thread Type column is only useful to SAP Support for detailed analysis.
● What a thread is currently working on
The information in Thread Detail, Thread Method, and Thread Status columns is helpful for analyzing what a
thread is currently working on. In the case of SqlExecutor threads, for example, the SQL statement
currently being processed is displayed. In the case of PlanExecutor threads (or JobWorker threads as of
revision 56), details about the execution plan currently being processed are displayed.
Note
The information in the Thread Detail, Thread Method, and Thread Status columns is only useful to SAP
Support for detailed analysis.
● Information about transactionally blocked threads
A transactionally blocked thread is indicated by a warning icon ( ) in the Status column. You can see
detailed information about the blocking situation by hovering the cursor over this icon.
A transactionally blocked thread cannot be processed because it needs to acquire a transactional lock that
is currently held by another transaction. Transactional locks may be held on records or tables. Transactions
can also be blocked waiting for other resources such as network or disk (database or metadata locks).
The type of lock held by the blocking thread (record, table, or metadata) is indicated in the Transactional
Lock Type column.
The lock mode determines the level of access other transactions have to the locked record, table, or
database. The lock mode is indicated in the Transactional Lock Type column.
Exclusive row-level locks prevent concurrent write operations on the same record. They are acquired
implicitly by update and delete operations or explicitly with the SELECT FOR UPDATE statement.
Table-level locks prevent operations on the content of a table from interfering with changes to the table
denition (such as drop table, alter table). DML operations on the table content require an intentional
exclusive lock, while changes to the table denition (DDL operations) require an exclusive table lock. There
is also a LOCK TABLE statement for explicitly locking a table. Intentional exclusive locks can be acquired if
no other transaction holds an exclusive lock for the same object. Exclusive locks require that no other
transaction holds a lock for the same object (neither intentional exclusive nor exclusive).
For more detailed analysis of blocked threads, information about low-level locks is available in the columns
Lock Wait Name, Lock Wait Component and Thread ID of Low-Level Lock Owner. Low-level locks are locks
acquired at the thread level. They manage code-level access to a range of resources (for example, internal
data structures, network, disk). Lock wait components group low-level locks by engine component or
resource.
SAP HANA Troubleshooting and Performance Analysis Guide
Tools and Tracing
P U B L I C 175

The Blocked Transactions sub-tab provides you with a ltered view of transactionally blocked threads.
Monitoring and Analysis Features
To support monitoring and analysis, you can perform the following actions on the Threads sub-tab:
● See the full details of a thread by right-clicking the thread and choosing Show Details.
● End the operations associated with a thread by right-clicking the thread and choosing Cancel Operations.
Note
This option is not available for threads of external transactions, that is those with a connection ID of -1.
● Jump to the following related objects by right-clicking the thread and choosing Navigate To <related
object> :
○ Threads called by and calling the selected thread
○ Sessions with the same connection ID as the selected thread
○ Blocked transactions with the same connection ID as the selected thread
● View the call stack for a specic thread by selecting the Create call stacks checkbox, refreshing the page,
and then selecting the thread in question.
Note
The information contained in call stacks is only useful to SAP Support for detailed analysis.
● Activate the expensive statements trace, SQL trace, or performance trace by choosing Congure Trace
<required trace> .
The Trace Conguration dialog opens with information from the selected thread automatically entered
(application and user).
Note
If the SQL trace or expensive statements trace is already running, the new settings overwrite the
existing ones. If the performance trace is already running, you must stop it before you can start a new
one.
Related Information
M_SERVICE_THREADS System View
M_SERVICE_THREAD_SAMPLES System View
SQL Trace [page 181]
Performance Trace [page 231]
Expensive Statements Trace [page 186]
176
P U B L I C
SAP HANA Troubleshooting and Performance Analysis Guide
Tools and Tracing

4.1.2 Blocked Transaction Monitoring
Blocked transactions, or transactionally blocked threads, can impact application responsiveness. They are
indicated in the Administration editor on the Performance Threads tab. You can see another
representation of the information about blocked and blocking transactions on the Blocked Transactions sub-
tab.
Information About Blocked Transactions
Blocked transactions are transactions that are unable to be processed further because they need to acquire
transactional locks (record or table locks) that are currently held by another transaction. Transactions can also
be blocked waiting for other resources such as network or disk (database or metadata locks).
The type of lock held by the blocking transaction (record, table, or metadata) is indicated in the Transactional
Lock Type column.
The lock mode determines the level of access other transactions have to the locked record, table, or database.
The lock mode is indicated in the Transactional Lock Type column.
Exclusive row-level locks prevent concurrent write operations on the same record. They are acquired implicitly
by update and delete operations or explicitly with the SELECT FOR UPDATE statement.
Table-level locks prevent operations on the content of a table from interfering with changes to the table
denition (such as drop table, alter table). DML operations on the table content require an intentional
exclusive lock, while changes to the table denition (DDL operations) require an exclusive table lock. There is
also a LOCK TABLE statement for explicitly locking a table. Intentional exclusive locks can be acquired if no
other transaction holds an exclusive lock for the same object. Exclusive locks require that no other transaction
holds a lock for the same object (neither intentional exclusive nor exclusive).
For more detailed analysis of blocked transactions, information about low-level locks is available in the columns
Lock Wait Name, Lock Wait Component and Thread ID of Low-Level Lock Owner. Low-level locks are locks
acquired at the thread level. They manage code-level access to a range of resources (for example, internal data
structures, network, disk). Lock wait components group low-level locks by engine component or resource.
Monitoring and Analysis Features
To support monitoring and analysis, you can perform the following actions on the Blocked Transactions sub-
tab:
● Jump to threads and sessions with the same connection ID as a blocked/blocking transaction by right-
clicking the transaction and choosing Navigate To <related object> .
● Activate the performance trace, SQL trace, or expensive statements trace for the blocking transaction
(that is the lock holder) by choosing Congure Trace <required trace> .
The Trace Conguration dialog opens with information from the selected thread automatically entered
(application and user).
SAP HANA Troubleshooting and Performance Analysis Guide
Tools and Tracing
P U B L I C 177

Note
If the SQL trace or expensive statements trace is already running, the new settings overwrite the
existing ones. If the performance trace is already running, you must stop it before you can start a new
one.
Related Information
SQL Trace [page 181]
Performance Trace [page 231]
Expensive Statements Trace [page 186]
M_BLOCKED_TRANSACTIONS System View
M_OBJECT_LOCKS System View
M_RECORD_LOCKS System View
M_OBJECT_LOCK_STATISTICS System View
4.1.3 Session Monitoring
You can monitor all sessions in your landscape in the Administration editor on the Performance Sessions
sub-tab.
Session Information
The Sessions sub-tab allows you to monitor all sessions in the current landscape. You can see the following
information:
● Active/inactive sessions and their relation to applications
● Whether a session is blocked and if so which session is blocking
● The number of transactions that are blocked by a blocking session
● Statistics like average query runtime and the number of DML and DDL statements in a session
● The operator currently being processed by an active session (Current Operator column).
Note
In earlier revisions, you can get this information from the SYS.M_CONNECTIONS monitoring view with
the following statement:
SELECT CURRENT_OPERATOR_NAME FROM M_CONNECTIONS WHERE CONNECTION_STATUS =
'RUNNING'
Tip
To investigate sessions with the connection status RUNNING, you can analyze the SQL statements being
processed in the session. To see the statements, ensure that the Last Executed Statement and Current
178
P U B L I C
SAP HANA Troubleshooting and Performance Analysis Guide
Tools and Tracing
Statement columns are visible. You can then copy the statement into the SQL console and analyze it using
the Explain Plan and Visualize Plan features. It is also possible to use the SQL plan cache to understand and
analyze SQL processing.
Monitoring and Analysis Features
To support monitoring and analysis, you can perform the following actions on the Sessions sub-tab:
● Cancel a session by right-clicking the session and choosing Cancel Session...
● Jump to the following related objects by right-clicking the session and choosing Navigate To <related
object>
:
○ Threads with the same connection ID as the selected session
○ Blocked transactions with the same connection ID as the selected session
● Activate the performance trace, SQL trace, or expensive statements trace by choosing Congure Trace
<required trace> .
The Trace Conguration dialog opens with information from the selected session automatically entered
(application and user).
Note
If the SQL trace or expensive statements trace is already running, the new settings overwrite the
existing ones. If the performance trace is already running, you must stop it before you can start a new
one.
Related Information
SQL Trace [page 181]
Performance Trace [page 231]
Expensive Statements Trace [page 186]
M_CONNECTIONS System View
M_TRANSACTIONS System View
4.1.4 Job Progress Monitoring
Certain operations in SAP HANA typically run for a long time and may consume a considerable amount of
resources. You can monitor long-running jobs in the Administration editor on the Performance Job
Progress sub-tab.
By monitoring the progress of long-running operations, for example, delta merge operations and data
compression, you can determine whether or not they are responsible for current high load, see how far along
they are, and when they will nish.
SAP HANA Troubleshooting and Performance Analysis Guide
Tools and Tracing
P U B L I C 179

The following information is available, for example:
● Connection that triggered the operation (CONNECTION_ID)
● Start time of the operation (START_TIME)
● Steps of the operation that have already nished (CURRENT_PROGRESS)
● Maximum number of steps in the operation (MAX_PROGRESS)
For more information about the operations that appear on the Job Progress sub-tab, see system view
M_JOB_PROGRESS.
Related Information
M_JOB_PROGRESS System View
4.1.5 Load Monitoring
A graphical display of a range of system performance indicators is available in the Administration editor on the
Performance Load sub-tab.
You can use the load graph for performance monitoring and analysis. For example, you can use it to get a
general idea about how many blocked transactions exist now and in the past, or troubleshoot the root cause of
slow statement performance.
Related Information
SAP HANA Troubleshooting and Performance Analysis Guide [page 6]
4.2 SQL Statement Analysis
A key step in identifying the source of poor performance is understanding how much time SAP HANA spends
on query execution. By analyzing SQL statements and calculating their response times, you can better
understand how the statements aect application and system performance.
You can analyze the response time of SQL statements with the following traces:
● SQL trace
From the trace le, you can analyze the response time of SQL statements.
● Expensive statements trace
On the Performance Expensive Statements Trace tab, you can view a list of all SQL statements that
exceed a specied response time.
180
P U B L I C
SAP HANA Troubleshooting and Performance Analysis Guide
Tools and Tracing
In addition to these traces, you can analyze the SQL plan cache, which provides a statistical overview of what
statements are executed in the system.
4.2.1 Analyzing SQL Traces
The SQL trace allows you to analyze the response time of SQL statements within an object.
Procedure
1. In the Administration editor, choose the Trace Conguration trace and edit the SQL trace.
2. In the Trace Conguration dialog box, specify a name for the trace le, set the trace status to Active, and
specify the required trace and user lters.
3. Choose Finish.
4. Run the application or SQL statements you want to trace.
5. Re-open the SQL trace conguration and set the trace status to Inactive.
6. Choose Finish.
7. Choose the Diagnosis Files tab and open the trace le you created.
8. Choose Show Entire File.
9. Analyze the response time of the relevant SQL statements to identify which statements negatively aect
performance.
The SQL statements in the trace le are listed in order of execution time. To calculate the response time of
a specic SQL statement, calculate the dierence between the times given for # tracing
PrepareStatement_execute call and # tracing finished PrepareStatement_execute.
4.2.1.1 SQL Trace
The SQL trace collects information about all SQL statements executed on the index server (tenant database)
or name sever (system database) and saves it in a trace le for further analysis. The SQL trace is inactive by
default.
Information collected by the SQL trace includes overall execution time of each statement, the number of
records aected, potential errors (for example, unique constraint violations) that were reported, the database
connection being used, and so on. The SQL trace is a good starting point for understanding executed
statements and their potential eect on the overall application and system performance, as well as for
identifying potential performance bottlenecks at statement level.
SAP HANA Troubleshooting and Performance Analysis Guide
Tools and Tracing
P U B L I C 181

SQL Trace Files
SQL trace information is saved as an executable python program (by default sqltrace_<...>.py), which can
be used to replay the traced database operations. You can also use the SQL Trace Analyzer tool to automate
the analysis of the le.
Enabling and Conguring the SQL Trace
You can enable and congure the SQL trace in the SAP HANA database explorer or SAP HANA studio.
Alternatively, you can modify the parameters in thesqltrace section of the indexserver.ini (tenant
database) or nameserver.ini (system database).
Example
Use the following statement to enable the SQL trace:
ALTER SYSTEM ALTER CONFIGURATION ('indexserver.ini', 'SYSTEM') SET ('sqltrace',
'trace') = 'on' WITH RECONFIGURE
Recommendation
Do not leave the SQL trace enabled all the time as writing trace les consumes storage space on the disk
and can impact database performance signicantly.
Trace Levels
You can set the level for the SQL trace by changing the value of the conguration parameter [sqltrace]
level in the indexserver.ini le (tenant database) or nameserver.ini le (system database). Trace
information includes details such as executed timestamp, thread ID, connection ID, and statement ID.
Trace Level
Description
NORMAL All statements that have nished successfully are traced.
ERROR All statements that returned errors are traced.
ERROR_ROLLBACK All statements that are rolled back are traced.
ALL All statements including status of normal, error, and rollback are traced.
ALL_WITH_RESULTS In addition to the trace generated with trace level ALL, the result returned by select state
ments is also included in the trace le.
Note
An SQL trace that includes results can quickly become very large.
Caution
An SQL trace that includes results may expose security-relevant data, for example,
query result sets.
182 P U B L IC
SAP HANA Troubleshooting and Performance Analysis Guide
Tools and Tracing

Trace Details
You can congure trace detail information by setting the parameter [sqltrace] details. You can select one
or more categories of information to include in the trace, for example: 'basic,resource_consumption'.
Possible values are listed in the following table. Note that for resource consumption information (this is also
included in the 'all' option) the following two parameters in the
global.ini le [resource_tracking]
section, must be set to 'on':
● enable_tracking
● memory_tracking
You may also wish to limit the maximum memory allocation per statement by setting a value for the
[memorymanager] statement_memory_limit parameter in the global.ini le. Set this to 5, for
example, to apply a limit of 5GB.
Trace Details Description
basic Connection information and statement information (default)
all Include all comments of connection and statement
user_variables User-dened variables in the session context
statement Statement information such as executed timestamp, thread ID, connection ID, statement
ID, statement hash and duration
session_variables System-dened variables in the session context
resource_consumption Statement resource consumption information such as local (+remote, if available) cpu-
time and memory-size.
passport Decoded passport contents
connection Connection information such as session ID, transaction ID, client PID, client IP, user name,
schema name, and session variable:value pairs
"empty" Trace without these comments
SAP HANA Troubleshooting and Performance Analysis Guide
Tools and Tracing
P U B L I C 183

Additional Conguration Options
Option Conguration Parameter Default Description
Trace le name
tracefile sqltrace_
$HOST_$
{PORT}_$
{COUNT:
3}.py
User-specic name for the trace le
If you do not enter a user-specic le name, the le
name is generated according to the following de
fault pattern:
DB_<dbname>/sqltrace_$HOST_$
{PORT}_${COUNT:3}.py, where:
● DB_<dbname> is the sub-directory where the
trace le is written if you are running on a ten
ant database
● $HOST is the host name of the service (for ex
ample, indexserver)
● $PORT is the port number of the service
● $COUNT:3 is an automatically generated 3-
digit number starting with 000 that incre
ments by 1 and serves as a le counter when
several les are created.
User, applica
tion, object, and
statement l-
ters
user
Empty string Filters to restrict traced statements to those of par
ticular database or application users and applica
tions, as well as to certain statement types and spe
cic objects (tables, views, procedures).
All statements matching the lter criteria are re
corded and saved to the specied trace le.
For user, application_user, and
application the use of wildcards is supported
(see following subsection Using Wildcards).
application_user
application
object
statement_type
Flush limit
flush_interval
16 During tracing, the messages of a connection are
buered. As soon as the ush limit number of mes
sages is buered (or if the connection is closed),
those messages are written to the trace le.
When set to 0, every SQL trace statement is imme
diately written to the trace le
Using Wildcards
If you apply lters for the user, application_user, and application parameters, the use of wildcards and
exceptions is also supported. The asterisk wildcard character denotes any number of characters and the
exclamation mark denotes an exclusion. For example:
user=SM*,JONES,!GREEN,!BRO*
In this case all users starting with SM will be traced, JONES will be traced, user GREEN will not be traced and all
users starting with BRO will not be traced. If terms in the string conict with each other then the sequence in
which the terms occur determines the result. In the following example user SMALL will be traced in spite of the
exclusion; the exclusion is ignored because it occurs after the rst wildcard.
user=SM*,JONES,!SMALL,!BRO*
184
P U B L I C
SAP HANA Troubleshooting and Performance Analysis Guide
Tools and Tracing

Trace File Rotation
The size and number of trace les are controlled by the following parameters.
Parameter Default Description
max_files 1
Sets the maximum number of trace
les
filesize_limit 1610612736 (or 1.5 GB)
Sets the maximum size of an individual
trace le in bytes
Caution
If both the maximum number of les and the maximum le size are reached, SQL tracing stops. If this
happens, you can increase the values of max_files and filesize_limit. See SAP Note 2629103.
SAP HANA SQL Trace Analyzer
SAP HANA SQL trace analyzer is a Python tool you can use to analyze the HANA SQL trace output. The tool
gives you an overview of the top SQL statements, the tables accessed, statistical information on dierent
statement types and on transactions executed.
For more information about the installation and usage of SAP HANA SQL trace analyzer, see SAP Knowledge
Base Article 2412519 FAQ: SAP HANA SQL Trace Analyzer.
Related Information
Diagnosis Files
SAP Note 2412519
SAP Note 2629103
4.2.2 Analyzing Expensive Statements Traces
The expensive statements trace allows you to identify which SQL statements require a signicant amount of
time and resources.
Procedure
1. In the Administration editor, choose the Trace Conguration trace and edit the expensive statements trace.
2. In the Trace Conguration dialog box, set the trace status to Active and specify a threshold execution time
in microseconds.
SAP HANA Troubleshooting and Performance Analysis Guide
Tools and Tracing
P U B L I C 185

The system will identify any statements that exceed this threshold as expensive statements.
3. Choose Finish.
4. Run the application or SQL statements you want to trace.
5. Choose the Performance Expensive Statements Trace tab.
6. Analyze the displayed information to identify which statements negatively aected performance.
For each SQL statement, the following columns are especially useful for determining the statement's
impact on performance:
○ START_TIME
○ DURATION_MICROSEC
○ OBJECT_NAME (names of the objects accessed)
○ STATEMENT_STRING
○ CPU_TIME
4.2.2.1 Expensive Statements Trace
Expensive statements are individual SQL statements whose execution time exceeds a congured threshold.
The expensive statements trace records information about these statements for further analysis and is inactive
by default.
If, in addition to activating the expensive statements trace, you enable per-statement memory tracking, the
expensive statements trace will also show the peak memory size used to execute the expensive statements.
Expensive Statements Trace Information
If you have the TRACE ADMIN privilege, then you can view expensive statements trace information in the
following ways:
● In the Expensive Statements app of the SAP HANA cockpit
● On the Trace Conguration Expensive Statements Trace tab of the SAP HANA database explorer
● On the Performance Expensive Statements tab of the SAP HANA studio
● In the M_EXPENSIVE_STATEMENTS system view
Enabling and Conguring the Expensive Statements Trace
You can enable and activate the expensive statements trace in the SAP HANA cockpit or the SAP HANA
database explorer. Alternatively, you can modify the parameters in the expensive_statement section of the
global.ini conguration le.
186
P U B L I C
SAP HANA Troubleshooting and Performance Analysis Guide
Tools and Tracing

Conguration Options
Note
The following table shows the conguration parameters which are available; not all of these may be
available in the SAP HANA cockpit or the SAP HANA database explorer.
Option
Conguration Parameter Default Value Description
Trace status
enable off
Species the activation status of the trace.
Threshold CPU
time
threshold_cpu_time -1 (disabled)
Species the threshold CPU time of statement exe
cution in microseconds.
When set to 0, all SQL statements are traced.
Note
Resource tracking and CPU time tracking must
also be enabled. You can do this by conguring
the corresponding parameters in the
resource_tracking section of the
global.ini le.
Threshold
memory
threshold_memory -1 (disabled)
Species the threshold memory usage of state
ment execution in bytes.
When set to 0, all SQL statements are traced.
Note
Resource tracking and memory tracking must
also be enabled. You can do this by conguring
the corresponding parameters in the
resource_tracking section of the
global.ini le.
Threshold dura
tion
threshold _duration 1000000 ( mi
croseconds = 1
second )
Species the threshold execution time in microsec
onds.
When set to 0, all SQL statements are traced. In the
SAP HANA database explorer, you can set the
threshold duration to be measured in seconds or
milliseconds.
User, applica
tion, and object
lters
user
Empty string Species lters to restrict traced statements to
those of a particular database, application user, ap
plication, or tables/views. For
user,
application_user, and application the
use of wildcards is supported (see following sub
section
Using Wildcards).
application_user
application
object
SAP HANA Troubleshooting and Performance Analysis Guide
Tools and Tracing
P U B L I C 187

Option Conguration Parameter Default Value Description
Passport trace
level
passport_tracelevel
Empty string
If you are activating the expensive statements trace
as part of an end-to-end trace scenario with the
Process Monitoring Infrastructure (PMI), you can
specify the passport trace level as an additional l-
ter.
This means that only requests that are marked with
a passport of the specied level are traced.
Note
Process tracing is possible only for compo
nents in the ABAP and Business Objects
stacks.
Trace parame
ter values
trace_parameter_values true
In SQL statements, eld values may be specied as
parameters (using a "?" in the syntax). If these pa
rameter values are not required, then you can disa
ble this setting to reduce the amount of data
traced.
Trace ush in
terval
trace_flush_interval
10 Species the number of records after which a trace
le is ushed.
Use in-memory
tracing
use_in_memory_tracing true
If in-memory tracing is active, then information is
cached in memory. Otherwise, the data is written
directly to le.
In-memory
tracing records
in_memory_tracing_reco
rds
30000
Species the maximum number of trace records
(per service) stored in memory.
This setting only takes eect when in memory trac
ing is active.
Using Wildcards
If you apply lters for the user, application_user, and application parameters, the use of wildcards and
exceptions is also supported. The asterisk wildcard character denotes any number of characters and the
exclamation mark denotes an exclusion. For example:
user=SM*,JONES,!GREEN,!BRO*
In this case all users starting with SM will be traced, JONES will be traced, user GREEN will not be traced and all
users starting with BRO will not be traced. If terms in the string conict with each other then the sequence in
which the terms occur determines the result. In the following example user SMALL will be traced in spite of the
exclusion; the exclusion is ignored because it occurs after the rst wildcard.
user=SM*,JONES,!SMALL,!BRO*
Trace File Rotation
To prevent expensive statement trace information from growing indenitely, you can limit the size and number
of trace les using the following parameters in expensive_statement of global.ini.
188
P U B L I C
SAP HANA Troubleshooting and Performance Analysis Guide
Tools and Tracing

Parameter Default Description
maxfiles 10
Species the maximum number of
trace les.
When the maximum number of trace
les reached, the oldest trace le is de
leted and a new one opened.
When set to 0, trace le rotation is disa
bled.
maxfilesize 10000000 (or 9.5 megabytes)
Species the maximum size of an indi
vidual trace le in bytes.
When the maximum number of les is
greater than 1 and the maximum le
size is reached, a new trace le is
opened.
When the maximum number of les is 1,
the maximum le size is greater than
zero, and the maximum le size is
reached, the trace le is deleted and a
new one opened.
Related Information
Setting a Memory Limit for SQL Statements [page 35]
Monitoring and Analyzing Expensive Statements (SAP HANA Cockpit)
Expensive Statements Monitoring (SAP HANA Studio)
M_EXPENSIVE_STATEMENTS System View
SAP Note 2180165
4.2.3 Analyzing SQL Execution with the SQL Plan Cache
The SQL plan cache is a valuable tool for understanding and analyzing SQL processing.
Before it is executed, every SQL statement is compiled to a plan. Once a plan has been compiled it is better to
reuse it the next time the same statement is executed rather than compiling a new plan every time. The SAP
HANA database provides an object, the SQL plan cache, that stores plans generated from previous executions.
Whenever the execution of a statement is requested, an SQL procedure checks the SQL plan cache to see if
there is a plan already compiled. If a match is found, the cached plan is reused. If not, the statement is
compiled and the newly generated plan is cached.
As the SQL plan cache collects statistics on the preparation and execution of SQL statements it is an important
tool for understanding and analyzing SQL processing. For example, it can help you to nd slow queries as well
as to measure the overall performance of your system.
SAP HANA Troubleshooting and Performance Analysis Guide
Tools and Tracing
P U B L I C 189

Various options are available for analyzing the plan cache for a statement:
● In SAP HANA cockpit the link for SQL Plan Cache is available in the Monitoring group.
● In SAP HANA studio SQL Plan Cache is a sub-tab of the Performance tab.
● The two system views associated with the SQL plan cache are M_SQL_PLAN_CACHE_OVERVIEW and
M_SQL_PLAN_CACHE.
The SQL plan cache contains a lot of information. Filtering according to the following columns can help you
identify statements that are more likely to be causing problems and/or could be optimized:
Column
Description
TOTAL_EXECUTION_TIME The total time spent for all executions of a plan
This helps to identify which statements are dominant in terms of time.
AVG_EXECUTION_TIME The average time it takes to execute a plan execution
This can help you identify long-running SQL statements.
EXECUTION_COUNT The number of times a plan has been executed
This can help you identify SQL statements that are executed more frequently than ex
pected.
TOTAL_LOCK_WAIT_COUNT The total number of waiting locks
This can help you identify SQL statements with high lock contention.
USER_NAME The name of the user who prepared the plan and therefore where the SQL originated
(ABAP/index server/statistics server)
For a full list of all SQL cache columns including descriptions, see the documentation for the system views
M_SQL_PLAN_CACHE_OVERVIEW and M_SQL_PLAN_CACHE in the SAP HANA SQL and System Views
Reference. Refer also to the sections on Managing the Performance of SAP HANA in the SAP HANA
Administration Guide.
Related Information
Managing and Monitoring SAP HANA Performance
SAP HANA SQL and System Views Reference
SQL Plan Cache Analysis [page 126]
4.3 Query Plan Analysis
In SAP HANA, to identify queries that are ineciently processed, you can both technically and logically analyze
the steps SAP HANA took to process those queries.
From a technical perspective, analyzing query plans allows you to identify long running steps, understand how
much data is processed by the operators, and see whether data is processed in parallel. However, if you
190
P U B L I C
SAP HANA Troubleshooting and Performance Analysis Guide
Tools and Tracing

understand the idea and purpose behind the query, you can also analyze query plans from a logical perspective
and consider questions such as:
● Does SAP HANA read data from multiple tables when only one is required?
● Does SAP HANA read all records when only one is required?
● Does SAP HANA read the best table, possibly a large table even though another table has a much smaller
result set?
To gain the insight you need to answer such questions, the following tools are available for query plan analysis:
● Plan explanation
● Plan visualization
Both tools are available as SQL commands but are also integrated into administration tools. Refer to SAP Note
2073964 - Create & Export PlanViz in HANA Studio for an introduction to using PlanViz in SAP HANA studio.
Tip
In some releases of HANA 1 and early releases of HANA 2 there were a number of known issues related to
the Plan visualization trace, these are documented in the KBA 2119087 - How-To: Conguring SAP HANA
Traces (section ‘PlanViz / Execution trace’). To avoid any issues you can use Explain Plan as an alternative
to Plan Visualization trace.
Related Information
SAP Note 2119087
SAP Note 2073964
4.3.1 Analyzing SQL Execution with the Plan Explanation
You can generate a plan explanation for any SQL statement and use this to evaluate the execution plan; you
may be able to use this information to optimize the query by reducing the run time or the memory
consumption.
The Explain Plan can be collected in several dierent ways:
● By running the EXPLAIN PLAN SQL statement
● In the SQL console of SAP HANA studio
● From within DBACOCKPIT.
Running EXPLAIN PLAN from the SQL Command Line
The SQL command oers two options: to capture the results directly from the query or capture from an
existing entry in the plan cache. The results of these two options may vary because in the rst case Explain Plan
is based on the prepared SQL statement not on the executed statement. If, on the other hand, you run Explain
Plan for a statement which has been executed and is available in the cache, then additional parameter aware
optimization will already have been applied. See also SAP Note 2410208 - Collect Explain Plan of a Prepared
Statement.
SAP HANA Troubleshooting and Performance Analysis Guide
Tools and Tracing
P U B L I C 191

After running Explain Plan, the plan results are saved in the EXPLAIN_PLAN_TABLE. An additional option
available is to give the plan details a recognizable name (STATEMENT_NAME value) so that your results are
easily identiable, see the following example.
The SQL syntax for the two options is as follows:
Code Syntax
EXPLAIN PLAN [SET STATEMENT_NAME = *<statement_name>*] FOR SELECT *<subquery>*
EXPLAIN PLAN [SET STATEMENT_NAME = *<statement_name>*] FOR SQL PLAN CACHE
ENTRY *<sql_plan_id>*
<statement_name> String literal. Used to identify the name of a specic execution plan in the output table
for a given SQL statement. It is set to NULL if the STATEMENT_NAME is not specied.
<subquery> An SQL statement.
<sql_plan_id> An SQL plan id (in sql plan cache).
The following illustration shows the usage of the two options and the statement name value:
Explain Plan in SAP HANA Studio
Enter a statement in the SQL console
of SAP HANA studio and before
executing the command choose
Explain Plan in the context menu. You
can enter multiple statements
separated by a semicolon to generate
several plan explanations at once.
The plan explanation is then displayed
on the
Result tab and stored in the
EXPLAIN_PLAN_TABLE view of the
SYS schema for later examination.
192 P U B L I C
SAP HANA Troubleshooting and Performance Analysis Guide
Tools and Tracing

Explain Plan in DBACOCKPIT
The Explain Plan results can also be
collected from transaction
DBACOCKPIT on the application
server:
Note
From DBACOCKPIT you will only
see partial information on the
explain plan, in the output you will
see the Operations executed and
the order they were executed in
but not the information on cost
and table size estimations
(OUTPUT_SIZE and
SUBTREE_COST). It is possible to
get this missing information by
taking the executed statement
from the plan cache and executing
the statement again.
How to use the Explain Plan to optimize a query:
The execution plan shows important detailed information on the query execution and the background
operations. Some of the key values are described briey here and in the examples which follow, refer to the
EXPLAIN_PLAN_TABLE system view in the SAP HANA SQL and System Views Reference for full details.
Area Detail
Operation details The OPERATOR_NAME value shows the type of operation which was executed, such as
joins, unions, aggregations and so on. Operations depend on the engine used - essentially
row engine or column engine. Dependencies are shown by indentation - see examples be
low.
Engine The type of engine where an operator is executed is shown in the EXECUTION_ENGINE col
umn: ROW, COLUMN, OLAP, HEX, ESX.
Table details Table details include table name, type, size, tables or objects which were accessed.
Estimated cost Cost values include the estimated output row count (OUTPUT_SIZE) and the estimated
time in seconds (SUBTREE_COST).
SAP HANA Troubleshooting and Performance Analysis Guide
Tools and Tracing
P U B L I C 193

Example 1
The following illustrations and commentary show how the information returned can be used.
We can see the OUTPUT_SIZE and SUBTREE_COST estimations for the various operations. The cost value is
used for the cost-based optimizer to choose the best plan; generally, the smaller the subtree cost, the better
the performance.
We can see that for the operations 1-13 the ROW store engine is used and that the operations 1-5 are executed
sequentially (OPERATOR_NAME values indented incrementally) and that operations 6-11 are executed in
parallel (left-aligned together):
Possible Optimizations
In this example, it may be possible to adjust the query so that more steps can be executed in parallel, or it may
be possible to change the query operations so that the column store engine is used instead of the row store
engine if a similar operator exists for the column store engine. You can use query hints to inuence how a query
is executed, for example, the hint use_olap_plan will force the HANA database to use the OLAP engine
instead of the join engine where this is technically possible. The available hints for the SAP HANA database are
described in the SAP HANA SQL and System Views Reference.
Refer also to the knowledge base article 2142945 - FAQ: SAP HANA Hints.
Example 2
In the following example lines we can see the execution engine switching between column and row store:
Where possible an engine switch should be avoided as it requires a materialization of intermediate results and
this is expensive in terms of both query performance and memory usage on HANA. It may be possible
therefore to optimize this query by adjusting it to avoid the engine switch.
194
P U B L I C
SAP HANA Troubleshooting and Performance Analysis Guide
Tools and Tracing

For more information about optimization possibilities refer to:
● The examples given in the SAP HANA SQL and System Views Reference
● Knowledge base article 2000002 - FAQ: SAP HANA SQL Optimization.
Related Information
SAP Note 2142945
SAP Note 2410208
SAP Note 2000002
4.3.2 Analyzing SQL Execution with the Plan Visualizer
To help you understand and analyze the execution plan of an SQL statement, you can generate a graphical view
of the plan.
Procedure
1. Visualize the plan of the SQL statement in one of the following ways:
a. Enter the statement in the SQL console and choose Visualize Plan in the context menu.
b. On the SQL Plan Cache tab or the Expensive Statements Trace tab of the Performance tab, right-click
the statement and choose Visualize Plan.
A graphical representation of the query, with estimated performance, is displayed.
Visualized Plan
SAP HANA Troubleshooting and Performance Analysis Guide
Tools and Tracing
P U B L I C 195
2. Validate the estimated performance by choosing Execute Plan in the context menu. Or use the shortcut key
F8
Another similar high-level graphic is generated with execution time information for each of the parts.
As of SPS 9, by default, a gray color indicates that the operator is not physical, meaning the operator
simply exists to give a more structured graph display.
Almost all of these non-physical operators can be removed from the graph if you prefer, by selecting 'None'
for the 'Node Grouping' option provided on the left of the graph.
Note: You can change the colors for each operator type under Window Preferences SAP HANA
PlanViz Graph Appearance .
Executed Plan
196
P U B L I C
SAP HANA Troubleshooting and Performance Analysis Guide
Tools and Tracing

SAP HANA Troubleshooting and Performance Analysis Guide
Tools and Tracing
P U B L I C 197
Note
Execution time is given as a pair of values: "Exclusive" (the execution time of the node), and "Inclusive"
(the execution time including the descendent nodes.
Results
This graphic is a very powerful tool for studying performance of queries on SAP HANA databases. You can
explore the graphic further, for example, you can expand, collapse, or rearrange nodes on the screen. You can
also save the graphic as an image or XML le, for example, so you can submit it as part of a support query.
4.3.2.1 Overview Page
Visualization of execution plans will automatically display an 'Overview' page
Starting from SPS 09 (client version), visualization of execution plans will automatically display an 'Overview'
page as you can see in the screenshot below. Some important KPIs required to begin a performance analysis
are provided so that you can rst get a big picture of what is going on before going into the complex details.
Overview Page
The following table describes the nature of each KPI:
KPI
Description Comment
Compilation Initial compilation time
198 P U B L I C
SAP HANA Troubleshooting and Performance Analysis Guide
Tools and Tracing

KPI Description Comment
Execution Total duration of the query excluding
compilation time
Dominant Operators Operators sorted by their execution
time (top 3)
You can click on any operator name to
move to the corresponding visualized
operator in the graph
Number of Nodes Number of servers involved in the exe
cution
You can click on the value to see how
much time was spent in each node
Number of Network Transfers Total number of network transfers that
have occurred during execution
You can click on the value to open 'Net
work View' which visualizes the trans
fers in more detail
Dominant Network Transfers Network transfers sorted by their exe
cution time (top 3)
You can click on any network transfer to
move to the corresponding visualized
transfer in the graph.
Note: This section only appears if the
query was executed in a distributed en
vironment.
SQL Query
The statement that was executed
System The system where the execution occur
red (that is, where nal results are
fetched)
Memory Allocated Total memory allocated for executing
the statement
Number of Tables Used Total number of tables touched upon by
any operator during execution
You can click on the value to open the
'Tables Used View' for more detail re
garding each table
Maximum Rows Processed The largest number of rows processed
by any single operator
Result Record Count The nal result record count
4.3.2.2 Statement Statistics
Visualization of execution plans for procedures displays a set of statistics for each SQL statement involved in a
procedure.
Context
This set of statistics is automatically visualized when a procedure is executed and it provides a good starting
point for analyzing performance of procedures as it lets you easily drill-down into the most expensive SQL
statements. Basic information such as execution count, execution/compile time, allocated memory size and so
SAP HANA Troubleshooting and Performance Analysis Guide
Tools and Tracing
P U B L I C 199
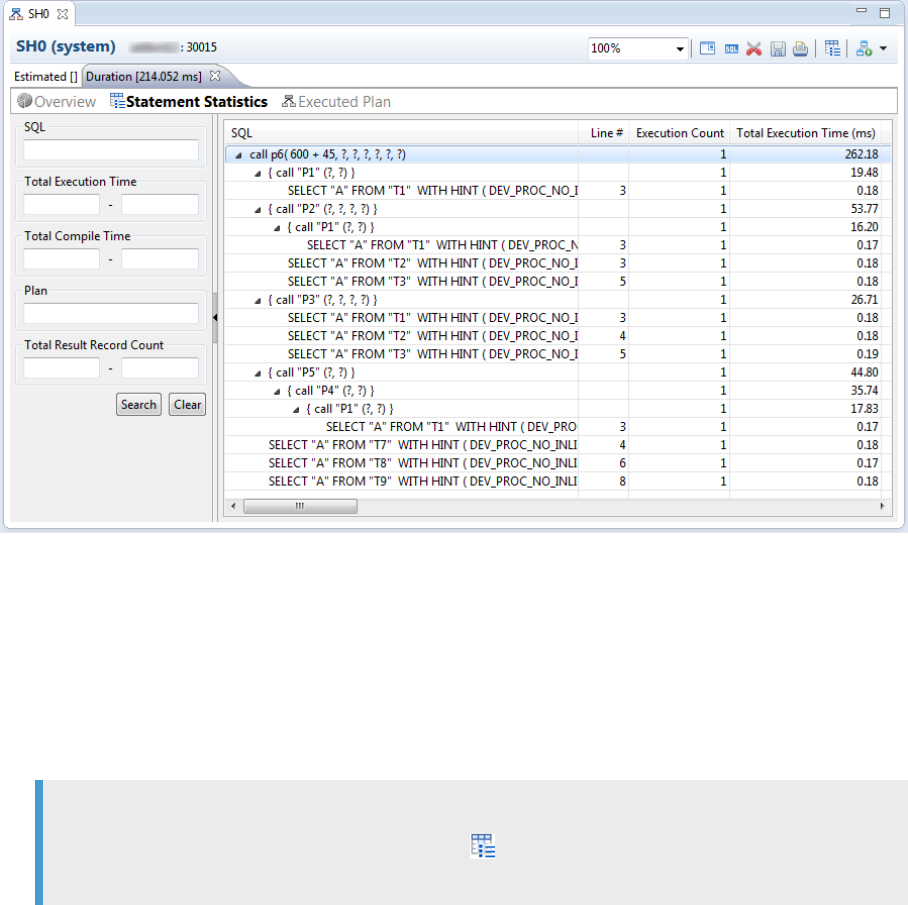
on are provided for each statement so that you can sort the column (criterion) of interest to nd the most
expensive statement.
The following pieces of information are available: SQL Statement, Line Number, Execution Count, Execution
Times, Compilation Times, Memory Allocated, Result Record Count, Explain Plan Result, and Procedure
Comment
Statement Statistics view
By right-clicking on any element of the SQL statement, you will have access to these menus:
● Show Plan in Graph: Displays the execution plan corresponding to the selected statement in the context of
entire plan.
● Show Plan in New Window: Displays the execution plan corresponding to the selected statement ONLY in a
separate pop-up window.
● Execute Statement: Enables users to reproduce the execution of a single statement
Note
To use this feature, the 'Keep Temp Tables' button ( ) located on the top-right corner of a graph editor
(Plan Visualizer) must be toggled before obtaining the executed plan of the procedure under analysis.
Procedure
1. Open an SQL Console
2. Enter any procedure into the console and choose Visualize Plan from the context menu.
3. Choose F8 to see executed plan from the visualized plan.
200
P U B L I C
SAP HANA Troubleshooting and Performance Analysis Guide
Tools and Tracing

Statement Statistics will be shown automatically and it will list all the statements that were involved in the
procedure. You can use this view to drill down to the potential root-cause of a long running procedure. For
example you might detect a single statement that takes up most of the time and check whether this is
indeed expected or notice that an identical statement is repeatedly executed with varying statistics (for
example, big gap between minimum execution time and maximum execution time).
4.3.2.3 Timeline View
The Timeline view provides a complete overview of the execution plan based on visualization of sequential
time-stamps.
Context
The following pieces of information are available in the view:
● X-axis: time elapsed since query execution,
● Y-axis: list of operators
● Duration of each operator execution represented by rectangular bars
● The nature of each time-stamp (for example, open, fetch, close, and so on.)
The view supports:
● Synchronized selection with operators in graphical plan
● Hierarchical display of operators based on parent-child relationship
● Re-conguration of scales via a toolbar option
Procedure
1. To see a temporal breakdown of the individual operations processed in the execution of the query, open the
Timeline view.
From the main menu choose Window Show View Timeline .
Timeline View
SAP HANA Troubleshooting and Performance Analysis Guide
Tools and Tracing
P U B L I C 201

2. Use this view to drill down to the potential root-cause of a long running query:
For example you might
○ Detect a single operator that takes up most of the time and check whether this is expected
○ Notice that some operators are executed sequentially instead of running in parallel, so you might
check the system environment
Next Steps
However, users should take into account the following point and limitations when analyzing the Timeline view:
● Any gaps or multiple occurrence of 'open', 'fetch', and so on in the Column Search operator invoked by the
row engine indicates that there was another operation called by the column engine in the meantime.
● The adjustment for exclusivity of time-stamps as described above is not applicable for column engine
operators, meaning some operators may not be actually running in parallel but simply calling one another.
● Logical grouping operators for the column engine (those colored in gray) simply display the aggregated
time-stamps of their constituent operators.
4.3.2.4 Operator List for Plan Visualizer
The Operator List view is used within the context of the Plan Visualizer perspective. It lists detailed
characteristics of all operators within a current plan, both visualized and executed.
The Operator List can be used to dynamically explore the operator set along user dened lters in order to
pinpoint specic operators of interest. The view supports:
● Display of various KPIs, for example,. isPhysical (meaning whether an operator is a real, physically
executed one), oset, execution time, CPU time
● Setting of lters along all the columns and KPIs
● Display of the number of operators within the ltered set
● Immediate aggregated information (max, min, sum, and so on) regarding the same KPIs on the lterd
operator set and the remaining set (not within the lter)
202
P U B L I C
SAP HANA Troubleshooting and Performance Analysis Guide
Tools and Tracing

● Detailed display of all operators within the ltered set (which can be further sorted)
● Export of the (ltered) operator list to a CSV le
● Forwards and backwards browsing through the history of applied lters.
As of SPS 09 the following features are supported:
● Show or hide columns using the preferences dialog (preferences icon next to save button)
● Change the order of columns using drag and drop
● Order and column visibility are stored in users workspace
● Remote search functionality. Press Ctrl+F when displaying an executed plan and specify search
parameters. When you carry out a search the operator list is updated accordingly
Operator List
You can use the Operator List view to analyze the set of operators within a plan for the occurrence of specic
conditions, even before looking into the visualized plan. For example, you might
1. Filter all operators that process a certain number of (input) rows
2. Further restrict the lter to physical operators (using "x" as the search criteria in lter column "Physical")
3. Display the executed plan, press Ctrl+F and set "Execution Time - At least" to 50
4. Finally, double click on an operator you are interested in to check its positioning within a visualized plan.
4.3.2.5 Network View
The Network View can visualize sequential network data transfers between dierent servers based on their
given timestamps when an execution plan is based on a distributed query.
Context
The following pieces of information are available in the view:
● X-axis: servers involved,
● Y-axis: time elapsed since query execution
● Duration of each operator represented by rectangular bars
● Size of data transferred in bytes
The view supports:
SAP HANA Troubleshooting and Performance Analysis Guide
Tools and Tracing
P U B L I C 203

● Synchronized selection with network operators in graphical plan
● Hover information for network bars
● Zoom in and out
You may use this view to discover any issues related to a distributed environment.
Procedure
1. Open the view
2. Check the results
For example you might notice that an unusually long time is spent on a particular network data transfer, so
you might check the data size and/or network condition and see that network data transfers occur too
frequently between a particular set of servers, so you might improve the distribution set-up.
3. Optimize your distributed landscape based on the results.
204
P U B L I C
SAP HANA Troubleshooting and Performance Analysis Guide
Tools and Tracing

4.3.2.6 Tables Used
The table usage view provides an overview on which tables have been used during the processing of a
statement.
Context
The Tables Used view can be used to cross-check your business understanding about which tables are needed
to fulll a given SQL statement.
The view displays 3 metrics per table:
● Maximum number of entries processed, that is the overall output cardinality of any processing step on that
table in the statement execution.
● Number of accesses, meaning how often a table has been accessed during statement execution
● Maximum processing time, that is the maximum processing time across the possibly multiple table
accesses
The view content can be sorted along any column; double-clicking on any row (table) leads to a corresponding
operator list ltered for physical operators accessing the selected table.
You may use this view to understand whether the data processing of your statement matches your business
expectations.
Procedure
1. Review the tables used in your SQL.
You may detect a table that has been processed which should not be needed from a business perspective,
so you might modify you SQL in a way that this table is no more used.
2. Review the number of times a table is accessed.
SAP HANA Troubleshooting and Performance Analysis Guide
Tools and Tracing
P U B L I C 205
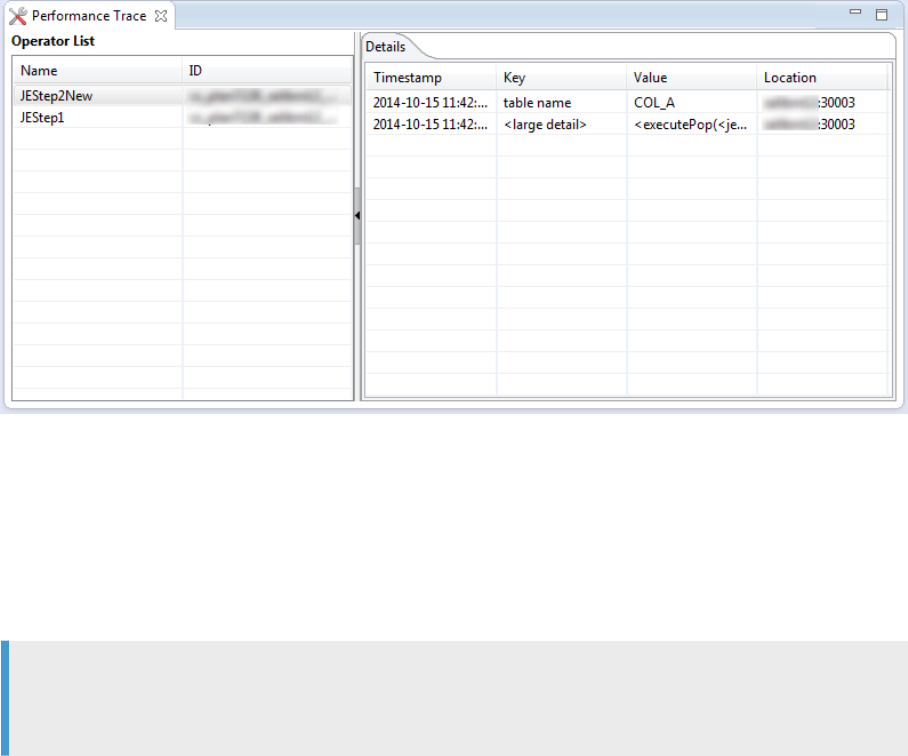
You may see that the number of processed entries is far higher than expected, so you can check if it is
possible to improve the ltering in your SQL statement.
4.3.2.7 Performance Trace
The Performance Trace view displays the list of operators that have performance trace data. The data can be
viewed by selecting any of the operator shown in the list.
Context
The view consists of two main sections:
● The left panel shows list of operators you can select to view performance trace data
● The right panel shows the performance trace data for the operator you have selected
The view supports:
● synchronized selection between operators visualized in the graph
● double-clicking on a particular data to view its full-text
Note
This view is mainly targeted towards advanced users who are well acquainted with the core details of SAP
HANA.
206
P U B L I C
SAP HANA Troubleshooting and Performance Analysis Guide
Tools and Tracing
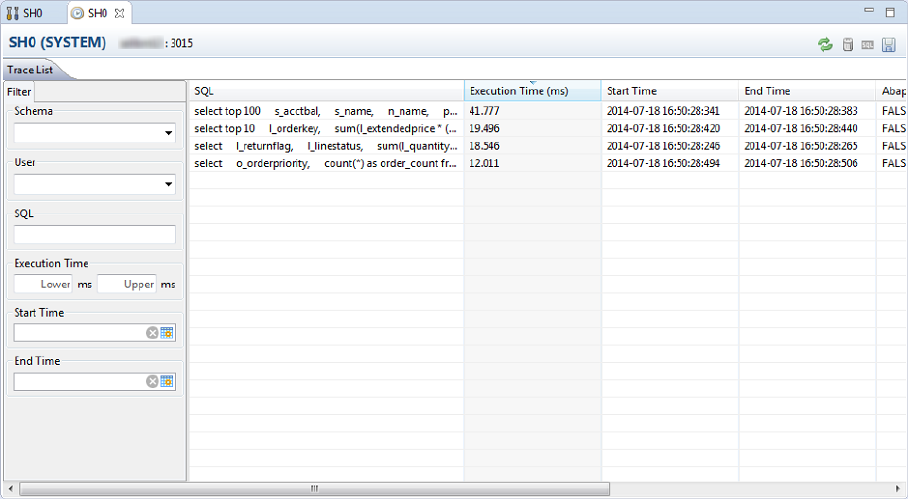
Procedure
1. Look for any additional properties relevant to a particular operator that you cannot nd from other views.
2. Fill in missing gaps in the Timeline view by deducing from the sequential list of activities.
3. Further break-down a specic operation into core engine-level details.
4.3.2.8 Plan Trace
Plan trace enables you to collect SQL queries and their execution plans, executed in a given time frame for a
particular application session.
Context
You can access the plan trace conguration wizard in SAP HANA studio in two ways:
● By right-clicking on a particular session you wish to trace in the Administration editor -> Performance ->
Sessions
● Going to Administration editor -> Trace Conguration tab
For each SQL query that has been traced, you will be able to visualize the execution plan for performance
analysis.
Once you stop an active trace, a Plan Trace Editor will be automatically opened displaying the queries that have
been traced.
As of SPS 09, only 'SELECT' statements are traced with Plan trace. You can double-click a particular statement
or open "Visualize Plan" from the context menu to get the execution plan.
SAP HANA Troubleshooting and Performance Analysis Guide
Tools and Tracing
P U B L I C 207

Procedure
1. Open the SQL Console
2. Open Administration editor Performance tab Sessions tab
3. Right-click on the session which corresponds to the SQL Console that you opened in step 1.
The column Application Source will contain the keyword 'SQLExecuteFormEditor'
4. From the context menu, choose Congure Trace Plan Trace
5. 'Press 'Finish' in the pop-up conguration wizard
6. Execute some SELECT queries in the SQL Console
Only SELECT queries are supported with SPS 09.
7. After execution, go back to the sessions list and deactivate 'Plan Trace' via conguration wizard (as in steps
4 to 6)
8. An editor (Plan Trace editor) will open automatically showing the list of queries that you have executed in
'SQL Console'
9. Each item (query) can be double-clicked for visualization of its execution plan
208
P U B L I C
SAP HANA Troubleshooting and Performance Analysis Guide
Tools and Tracing

4.3.2.9 Calculation Scenario Visualization
By navigating to a particular calculation view in the Systems view, you can access the Visualize View context
menu, which will visualize the calculation scenario associated with the view.
The calculation scenario visualizer consists of following three main sections:
● left: an overview which provides a list of calculation nodes involved in the scenario with their main
properties
● middle: the visualized graph of calculation scenario
● right: an input tab which provides mapping information of the selected node, an output tab which provides
attributes of a selected node, and a source tab which shows the raw JSON data of the selected node
The visualizer supports:
● link with 'Properties' view for each selected node
● double-clicking on a particular data source to drill down to its calculation scenario
You may use this visualizer to check whether the scenario is designed according to your understanding, and, if
not, nd potential tweaking points.
SAP HANA Troubleshooting and Performance Analysis Guide
Tools and Tracing
P U B L I C 209

4.4 Result Cache
The static result cache and the dynamic result cache are congurable applications of caching query results to
gain performance benets.
Caching is used widely in SAP HANA as a strategy to improve performance by re-using queried data rather
than re-reading and processing the data every time it is requested. The static result cache (sometimes referred
to as cached views) and the dynamic result cache are applications of this. The static result cache is created for
a specic view and remains valid for the duration of a user-dened retention period. The dynamic result cache
is similar but does not have a retention period; it guarantees transactional consistency by maintaining delta
records of all changes applied to the underlying table.
The following table gives a comparative overview of essential details of the static and dynamic result cache
features, these are described in detail in the subsections which follow:
Feature Static Result Cache Dynamic Result Cache
Target Scenario Scalability enhancement for query on complex
view (usually top-level view) from an
application which can accept stale data.
Scalability enhancement for heavy aggregation
workload on big tables which are frequently
updated (for example ACDOCA).
Query result Stale data Non-Stale data
Scope Target objects: SQL View, User-dened table
function (w/o imperative logic), Calculation
view with some limitation.
Aggregation types: SUM, MIN, MAX, COUNT.
Target objects: SQL Views on the aggregation
of a single column table.
Aggregation types:
SUM, COUNT, AVG - fully supported.
MIN, MAX- partially supported for insert only
table.
Cache Maintenance
Whenever the cache period becomes older
than the retention period then the cache is fully
refreshed.
At each query execution:
-If updated records are identiable then the
cache is incrementally updated with updated
records.
-If no update is identiable (due to MVCC
garbage collection) then the cache is fully
refreshed.
Implicit view matching Not supported Supported with hint / conguration.
Adoption eort:
dening cache
Usually static result cache is enabled on
existing CDS view or calculation view.
In the case of a CDS view without aggregation
the result cache should be dened with
expected aggregation type from target queries.
If the target aggregation is already dened as a
view, dynamic result can be enabled on the
existing view (explicit usage).
Otherwise, a new view denition is required and
dynamic result cache can be used with implicit
view matching.
210 P U B L I C
SAP HANA Troubleshooting and Performance Analysis Guide
Tools and Tracing

Feature Static Result Cache Dynamic Result Cache
Adoption eort:
enable cache
utilization
A hint is required to exploit static result cache
to make user intention on stale data access
clear.
Dynamic result cache is utilized by default even
without a hint (but hint or conguration is
required for enabling implicit view matching in
the current release.)
4.4.1 Static Result Cache
Complex SQL views and calculation views place a heavy load on the system. You may be able to use the static
result cache to reduce CPU consumption (and thus to increase overall system throughput) or to reduce the
response time of queries.
Frequently accessed views may consume an excessive amount of CPU. Cached views can trade this CPU
consumption for an increased memory consumption by caching the result of evaluating a view and reusing this
cached data when the view is accessed by a query.
Using the static result cache the query result of a view is cached in memory and refreshed only periodically. On
the one hand, this avoids having to reevaluate the view each time the view is accessed, on the other hand, the
cached data might be stale if the tables used by the view are updated after the last refresh. However, the data
retention period which determines how old the data may become is congurable and the age of the cached
data is also returned to the database client.
Cached views must be implemented in combination with careful testing to validate that correct results are
returned, that the cached views are actually used, and that indeed the CPU consumption is reduced. Tools
which can help with this are available in SAP HANA cockpit and SAP HANA studio such as Explain Plan and
Visualize Plan (see separate sections of this document).
Scope
Generally, caching can be used for calculation views, SQL views, table functions which return the result of a
single SQL SELECT statement, and CDS views (which are translated into table functions). To save memory,
cached views store aggregated values (aggregation types SUM, MIN, MAX, and COUNT are supported).
Not all views may be suitable for caching (for example views using time functions which depend upon the
current time would not be suitable). Caching cannot be used for scripted views, join views, OLAP views, and
hierarchy views. Other limitations may apply, for example, if analytic privileges have been applied to the data.
Conguring the Memory Budget
A maximum cache size (a memory budget) must be dened to manage the maximum amount of memory
available to cache cached views. This is congured in the indexserver.ini le in the total_size parameter in
the result_cache section of the le.
SAP HANA Troubleshooting and Performance Analysis Guide
Tools and Tracing
P U B L I C 211

Parameter Default Detail
total_size 10000 The memory budget in MB available for cached views.
If the memory consumed for caching views exceeds this threshold an alert is raised and, where necessary,
cached views will be dropped from memory resulting in higher response times for previously cached data. In
this case administrators may increase the memory budget size or create capacity in the budget by, for
example, dropping cached views which are rarely used.
If a view fails to be created then it is added to an exclusion list of views which have not been successfully
cached (view M_VIEW_CACHE_EXCLUSIONS). There are two common cases where this occurs:
● If the time to calculate the result of the view is longer than the retention time.
● If the memory required to cache the result of the view is larger than the memory budget.
The following example query selects basic details of failed cached views:
SELECT SCHEMA_NAME, OBJECT_NAME, REASON, EXCLUDE_TIME
FROM M_RESULT_CACHE_EXCLUSIONS
Hints to Enable the Result Cache
The static result cache feature is disabled by default and is only considered when explicitly invoked by using
one of the following RESULT_CACHE hints in the SQL statement :
Parameter
Detail
HINT(RESULT_CACHE)
Always use the result cache if it is available.
HINT(RESULT_CACHE_MAX_LAG(
seconds))
Sets the retention period of the result cache to this value (or the value set in the
ADD CACHE conguration).
HINT(RESULT_CACHE_NON_TRAN
SACTIONAL)
Allows join or union operations using the result cache entries and disregards
possible transaction inconsistencies.
HINT(RESULT_CACHE_NO_REFRE
SH)
Access existing cached data without refreshing it even if its retention period is
over.
Note that the hint class for result cache is also supported: RESULT_LAG('result_cache'[, seconds])
4.4.1.1 Creating and Using the Static Result Cache
This topic gives a number of examples to illustrate how you can use the result cache.
To save memory cached SQL views are based on aggregated results (SUM, MIN, MAX and COUNT are
supported); only the aggregated values are stored. The SQL optimizer uses the aggregation type of each
column in the top-most select statement as the basis for the cached result.
212
P U B L I C
SAP HANA Troubleshooting and Performance Analysis Guide
Tools and Tracing

When a user submits a query to a cached view a matching process analyzes the request and the denition of
the query to see if the cached data can be used or if the request must read the data from the database.
To exploit the cached data the query must match with the denition of the result cache and a number of
matching rules apply:
● The query must reference the same columns (or a subset of the columns) in the cache.
● The query must explicitly reference the view or a sub view referenced by the view.
● The predicate in the query must be the same as that used in creating the view, any additional conditions
which are added must be more restrictive lters.
Examples
Aggregation (OF clause)
For SQL views / functions, you can explicitly state the aggregation type as part of the ADD cache clause, then
the cache will be dened with an additional aggregation operation on the top for the view denition. This is
shown in the following example which creates a view and then uses the alter view syntax to add the view to the
cache with a retention period of 120 minutes.
CREATE VIEW SIMPLE_VIEW AS
(SELECT A, SUM(KF1) AS KF1, MIN(KF2) AS KF2, MAX(KF3) AS KF3
FROM SIMPLE_TABLE GROUP BY A)
ALTER VIEW SIMPLE_VIEW ADD CACHE RETENTION 120 OF A, SUM(KF1), MIN(KF2),
MAX(KF3), KF4;
The cache contents will be created from the result of the query: SELECT A, SUM(KF1), MIN(KF2),
MAX(KF3) FROM SIMPLE_VIEW GROUP BY A;
In the following example queries, the rst two statements consistently use the same aggregated values as
dened in the query and can exploit the cache. The third example cannot use the cached data because it
requests unaggregated details which are not included in the cache:
SELECT SUM(KF1) FROM SIMPLE_VIEW WITH HINT(RESULT_CACHE);
SELECT SUM(KF1), MIN(KF2), MAX(KF3) FROM SIMPLE_VIEW GROUP BY A WITH
HINT(RESULT_CACHE);
/* only aggregated data is cached - cannot use the cached data*/
SELECT KF1, KF2, KF3 FROM SIMPLE_VIEW WITH HINT(RESULT_CACHE);
If the user does not state the aggregation option in the ALTER VIEW statement, the cache will be dened the
same as the view denition:
ALTER VIEW SIMPLE_VIEW ADD CACHE RETENTION 120;
In this case, the cache contents will be created from result of the query: SELECT * FROM SIMPLE_VIEW;.
There is then no limitation of cache utilization for queries on SIMPLE_VIEW (as long as RESULT_CACHE hint is
used) and the cache would be utilized for all of above three queries.
SAP HANA Troubleshooting and Performance Analysis Guide
Tools and Tracing
P U B L I C 213

Filters (FILTER clause)
This example illustrates ltering. If the user states the additional lter option, the cache will be dened with an
additional lter on the top of the view denition:
ALTER VIEW SIMPLE_VIEW ADD CACHE RETENTION 120 FILTER B > 3;
The cache contents will be created from the result of the query: SELECT * FROM SIMPLE_VIEW WHERE B >
3;
In the following example queries the rst two statements will exploit the cache as those queries requires cache
data (B > 3) only. The third example cannot use the cached data because the query requests data which is not
a part of cached data.
SELECT SUM(KF1) FROM SIMPLE_VIEW WHERE B > 3 AND B < 10 WITH HINT(RESULT_CACHE);
SELECT SUM(KF1) FROM SIMPLE_VIEW WHERE B > 3 AND A = 1 WITH HINT(RESULT_CACHE);
/* only B > 3 data is cached - cannot use the cached data*/
SELECT KF1, KF2, KF3 FROM SIMPLE_VIEW WHERE A = 1 WITH HINT(RESULT_CACHE);
Cached Views and Analytic Privileges
By default a cache entry is created for each analytic privilege which in some cases may lead to a large number
of cache entries. To avoid this situation and to provide some exibility an alternative scheme is available which
can be applied by using a hint. This option must rst be enabled using a conguration parameter but once it is
enabled, one cache entry is created without applying analytic privileges and the privilege is then applied on top
of the cache for every query execution. Additionally, the coverage of analytic privilege type is also changed with
the alternative approach. By default, only static XML analytic privileges are supported, but using the
conguration and hint this limitation is removed and dynamic XML analytic privileges and SQL analytic
privileges are also supported.
This feature is enabled using the following conguration setting in the result_cache section of the
indexserver.ini le:
Parameter
Default Detail
before_analytic_privilege False
Set this to True to enable the option of caching the result before
applying analytic privileges.
Once the feature is enabled the following hints are supported:
● HINT(RESULT_CACHE_BEFORE_ANALYTIC_PRIVILEGE) - this hint builds the cache before the
authorization restrictions are applied (that is, read all the data and apply the restrictions when the data is
queried so that only authorized data is selected for each user).
● HINT(RESULT_CACHE_AFTER_ANALYTIC_PRIVILEGE)- this hint builds the cache in the normal way by
applying analytic privileges rst. This option is more ecient in terms of memory usage since less data is
cached but is only suitable for views where static XML privileges have been applied.
214
P U B L I C
SAP HANA Troubleshooting and Performance Analysis Guide
Tools and Tracing

Result Cache HDI Plugin
To transform and deploy design time DDL-based result cache denitions the result cache plugin is available.
The following example denes a result cache for the view named 'A_Sql_View':
RESULT CACHE "_SYS_CACHE#sap::A_Sql_View" ON VIEW "sap::A_Sql_View" WITH
RETENTION 30
This DDL-style syntax is the same as SQL except that no CREATE / ADD keyword is required. The complete
name of the cache is specied as: "_SYS_CACHE#<view name>".
To cache a table function use ON FUNCTION instead of ON VIEW. Any values after the keyword WITH are
copied to the corresponding SQL statement, so other parameters such as dening a projection list, a lter or
the force ag are also supported.
Refer to the SAP HANA Developer Guide For SAP HANA XS Advanced Model for further details.
4.4.1.2 Resources for Testing the Result Cache
This topic uses an example calculation view to illustrate how you can work with tools to test the result cache.
After caching a view it is important to verify that the view has been successfully cached, that correct results are
returned, that the cached views is actually used and is eectively reducing CPU consumption. The following
example uses the ALTER VIEW syntax to add a calculation view result to the cache with a retention period of 60
minutes:
ALTER VIEW "_SYS_BIC"."sap.hba.ecc/CostCenterPlanActualCommitmentQuery" ADD
CACHE RETENTION 60;
Note that the top-most node of a calculation view should be an aggregation type node. If it is not but the
calculation view does implicit grouping then caching will fail.
Carry out the following checks:
1) Check the system view RESULT_CACHE:
select schema_name, object_name, cache_type
from RESULT_CACHE
where object_name = 'my_view';
If the query on system view RESULT_CACHE returns a record, it indicates the successful creation of the cached
view.
2) After running a query against the cached view, use the Explain Plan tool (context menu in the SQL Console)
to conrm the source of the query result. The OPERATOR_NAME value should show RESULT_CACHE.
3) Continue to test the cached view by monitoring the execution times of queries based on the view. Expect the
rst execution of the query to be slow and look for performance improvements on subsequent runs. If there is
no reduction in response time or CPU consumption when the cached view is used then it is not benecial.
4) Use monitoring views M_RESULT_CACHE and M_HEAP_MEMORY to see more details of the cached view
such as memory consumption and data refresh details.
SAP HANA Troubleshooting and Performance Analysis Guide
Tools and Tracing
P U B L I C 215

Related Information
Analyzing SQL Execution with the Plan Explanation [page 191]
4.4.2 Dynamic Result Cache
The dynamic result cache may be used to improve the performance of queries which are frequently executed.
In comparison to the static result cache, running queries against a dynamic result cache may be a better option
for increasing the performance of queries. The dynamic result cache oers improved throughput and response
time but most importantly it eliminates the risk of querying stale data and will always return transactionally
consistent data. However, dynamic caches are not suitable for all views, the performance gains depend very
much upon the nature of the data, the query, and how frequently the cache is read.
Optimal scenarios where the dynamic result cache can dramatically improve performance include the following
characteristics:
● Intensive parallel querying of large tables
● Extensive use of aggregation
● Tables are regularly updated and up-to-date query results are essential.
An SAP Note about the Dynamic Result Cache is available: SAP Note 2506811 - FAQ: SAP HANA Dynamic
Result Cache.
Overview
You specify the cache type when you create the cache; only one type of cache can be applied to a view, either
static or dynamic. A key dierence is that the dynamic result cache has no retention period:
ALTER VIEW V ADD STATIC CACHE RETENTION 10;
ALTER VIEW V ADD DYNAMIC CACHE;
Dynamic result caches require no retention period because up-to-date query results are guaranteed. When a
query is executed against a dynamic result cache there are two possible responses:
● In the best-case scenario up-to-date results are returned by rstly incrementally updating the cache with
delta records of newly inserted, updated or deleted data and then returning the query result from the
cache.
● In some situations an incremental update of the cache is no longer possible as delta records are not
identiable due to version garbage collection; in this case the 'fallback' option is then invoked and the
query runs against the database. A full refresh of the cache is then executed in the background in a
separate thread.
The decision to either read from the cache or the database is taken during execution of the query. Events which
invalidate and prevent use of the cache include the following:
● The cached data has been invalidated by garbage collection (see details below).
216
P U B L I C
SAP HANA Troubleshooting and Performance Analysis Guide
Tools and Tracing

● The volume of delta records has reached its maximum permitted size of 10,000,000 (planned to be
changed in a future release).
In any of these cases the fallback option is used instead of the cache.
Scope
Dynamic result caches are only supported for SQL views dened as aggregation on single column tables;
aggregation types sum, count, and avg are supported. MIN and MAX aggregation is partially supported for
INSERT (see below).
Benets and Limitations
Some of the factors inuencing the benets gained from using dynamic result cache are discussed in more
detail here:
Query Execution Frequency: A side-eect of the version garbage collection process is that it may clear data
from the cache. To a certain extent the frequency of the garbage collection can be controlled by setting the
blocking period (see conguration below), but you should consider the negative impact this will have on the
general performance of all SELECT and UPDATE statements accessing the target table. If the cache is not used
within the blocking period then the cache will be invalidated by garbage collection and must be refreshed. A
querying frequency against the cached view of less than the garbage collection blocking period (default 1
minute) is therefore essential.
Table Size and Cache Size: Performance of the dynamic result cache is proportional to the cache size. A
performance gain can only be expected if the dynamic result cache has a signicantly smaller cache size than
the base table.
Aggregation: One of the greatest benets of cached views is in reducing the need for expensive aggregation
processes. If your data has a high degree of aggregation then using cached views may be benecial. Queries
with highly-selective lters, on the other hand, requiring only a few milliseconds for aggregation processing
should expect no benet from using dynamic result cache.
Base Table Characteristics: If the base table of the view is mostly used to INSERT data then a dynamic result
cache can be dened eectively in combination with all supported aggregation types: SUM, COUNT, AVG, MIN,
MAX. However, DELETE and UPDATE operations on the base table in combination with MIN or MAX
aggregation invalidate the cache and reduce the potential performance improvement. It is therefore not
recommended to use dynamic result cache with MIN/MAX aggregation if the target table is not an INSERT only
table.
Related Information
SAP Note 2506811
SAP HANA Troubleshooting and Performance Analysis Guide
Tools and Tracing
P U B L I C 217
4.4.2.1 Working With The Dynamic Result Cache
This section includes examples of creating the cache and the conguration parameters available to modify the
operation of caches and monitoring usage.
SQL Syntax
The OPTIMIZER ADMIN privilege is required to execute commands to congure the dynamic result cache.
You can add a dynamic cache to a view using either the CREATE VIEW or ALTER VIEW statements. Optionally, a
lter condition can be applied to the view. The basic syntax is shown here:
CREATE VIEW <view_name> [(column_name_list)] AS <subquery>
WITH DYNAMIC CACHE [FILTER <filter_condition>];
The option to DROP a cache is also available. Commands for use with ALTER SYSTEM are:
● CLEAR (remove all cache entries)
● REMOVE (remove a single named cache entry)
Refer to the SAP HANA SQL and System Views Reference for full details.
Examples
The basic usage with ALTER VIEW is shown in this example:
ALTER VIEW MyView ADD DYNAMIC CACHE;
To create a view with a dynamic result cache the syntax is:
CREATE VIEW MyView as (…) WITH DYNAMIC CACHE;
The following examples show how the dynamic result cache is used when a lter condition is applied:
1. You can apply a lter using the parameterized lter condition (with a question mark):
ALTER VIEW view1 ADD DYNAMIC CACHE FILTER MANDT = ?;
Only the equals comparator is permitted but multiple conditions can be used with the AND operator. For
example: MANDT = ? AND RLDNR = ?
2. If the cache is dened with a lter then a condition must be applied in the query:
SELECT * FROM view1 WHERE MANDT = 300;
3. The lter value can also be provided as a runtime parameter using the question mark syntax:
SELECT * FROM view1 WHERE MANDT = ?;
218
P U B L I C
SAP HANA Troubleshooting and Performance Analysis Guide
Tools and Tracing

Conguration
Dynamic result caches are enabled by default. A number of conguration parameters are available to manage
this feature in the 'dynamic_result_cache' section of the ini le:
Parameter: enabled
Purpose
Enable the dynamic cached views feature. If this is set as false then any cached data will be
ignored.
Default
true
Additional information
This functionality is available at run-time using the following two hints:
DYNAMIC_RESULT_CACHE - Select data from the dynamic result cache
NO_DYNAMIC_RESULT_CACHE - Explicit instruction not to use the cache
Parameter: total_size
Purpose
Apply a memory budget, that is, the maximum memory allocation which is available for all
dynamic result cache entries.
Default
10000
Unit
MB
Parameter: max_cache_entry_size
Purpose
Apply a memory budget for individual cache entries, that is, the maximum memory allocation
which is available for a single dynamic result cache.
Default
1000
Unit
MB
Exceptions Caches which exceed this size limitation are not used, they are registered on the exclusion list
and the fallback query will be used in future. The monitoring view
M_DYNAMIC_RESULT_CACHE_EXCLUSIONS shows a single entry for each cache which has
been excluded.
Note that for caches where a lter has been applied exclusion depends on the parameter used
and the total size of the result. If the result using one parameter is excluded it may still be
possible to use the cache with a dierent parameter which returns results within the memory
budget.
You can remove a cache key from the exclusion list by any of the following:
1. Disable dynamic result cache on the view: ALTER VIEW … DROP DYNAMIC CACHE;
2. Drop the view: DROP VIEW...;
3. Use the clear command: ALTER SYSTEM CLEAR DYNAMIC RESULT CACHE;
SAP HANA Troubleshooting and Performance Analysis Guide
Tools and Tracing
P U B L I C 219

Parameter: version_garbage_collection_blocking_period
Purpose
This parameter is used to prevent garbage collection from running against the view's base table.
Default
60
Unit
Seconds
Additional information
A side-eect of the version garbage collection process is that it may invalidate the cache which
must then be refreshed. To prevent this from frequently happening, you can use this parameter
to control the garbage collection process of the base table to block garbage collection for a
limited period of time.
Note that if the cache is not used within this period it will be invalidated and must be refreshed.
Parameter: enable_auto_delta_refresh
Purpose
Controls automatic delta refresh of dynamic result cache. Use this feature to minimize the
possibility of cache invalidation by garbage collection. If this is turned on a background job
triggers a refresh of the cache entry's delta whenever it is required. The feature is turned o by
default.
Default
FALSE
Parameter: enable_implicit_match
Purpose
Controls implicit matching which automatically attempts to match queries with the dynamic
result cache. The feature is enabled by default.
Default
TRUE
Monitoring
Two views are available to analyze the operation of the cache:
M_DYNAMIC_RESULT_CACHE Every cache has its own ID and this view gives full details of each cache
including memory size, record count and timestamps for cache and delta store. It also includes the timestamp
of the last cached MVCC snapshot which is the basis of the garbage collection process.
This view only shows data for a cache once a query has been executed against the view.
M_DYNAMIC_RESULT_CACHE_EXCLUSIONS Usage of views which cannot be cached is logged and details
can be seen in this view. Typically, this is caused by a data selection which exceeds the size dened in
max_cache_entry_size (by default 1GB). This view includes memory size, record count and timestamp of the
data.
220
P U B L I C
SAP HANA Troubleshooting and Performance Analysis Guide
Tools and Tracing
Implicit Matching
In order to extend the usage of the dynamic result cache to other queries, implicit matching automatically
attempts to match queries with cached views.
Using implicit matching the SQL optimizer reads the query plan of the current statement and analyzes the
structure to check if the requested data can be retrieved from cached data. If a suitable cache is available and
all the checks for data compatibility and user privileges are successful then the SQL optimizer rewrites the
execution plan to utilize the existing dynamic result cache.
Implicit matching may incur a slight overhead in query compilation times and although the feature is enabled
by default it can be turned o by setting the conguration parameter enable_implicit_match to FALSE.
Hints for Enabling Implicit Matching
If implicit view matching is disabled it can be used on an ad hoc basis using the following hint:
DYNAMIC_RESULT_CACHE_IMPLICIT_MATCH
Or, conversely, use this hint if necessary to manually turn it o:
NO_DYNAMIC_RESULT_CACHE_IMPLICIT_MATCH
Optionally, implicit matching can be used with a named specic view, or a selection of preferred views:
DYNAMIC_RESULT_CACHE_IMPLICIT_MATCH(<schema_name1>.<view_name1>,
<schema_name2>.<view_name2>, ...)
4.4.2.2 Testing the Dynamic Result Cache
You will need to test queries using a dynamic result cache to verify the performance benet. Some general
guidance to support testing is given here.
Testing and Verication
Important resources for testing include Explain Plan and Plan Visualization, and the monitoring view
M_DYNAMIC_RESULT_CACHE. You should be able to step through the complete process of creating and
querying the view and measuring the performance. This may include the following actions:
● Building and querying the cache
● Updating the target table and seeing an increase in the delta record count
● Seeing the selection of the appropriate query plan (both reading from the cache and reading from the
database) using Plan Visualization.
● Testing the eects of version garbage collection.
● Measuring performance (using hints to turn cache usage on or o).
SAP HANA Troubleshooting and Performance Analysis Guide
Tools and Tracing
P U B L I C 221
Create and Verify the View and Cache
Create the view and user ALTER VIEW to add the dynamic cache. You can then conrm that the cached view
was created by checking the system view DYNAMIC_RESULT_CACHE:
select
schema_name, object_name, cache_type, cache_filter, cache_locations
from DYNAMIC_RESULT_CACHE;
The expected return values are as follows:
CACHE_TYPE
'DYNAMIC, FULL' (for a dynamic result cache without a lter) or
'DYNAMIC, PARTIAL' (for a cache with a lter).
CACHE_FILTER
Filter shown if specied.
CACHE_LOCATIONS
Location of cache entry if specied.
Verify the Query Plan
Run a test query against the cached view. You can now use Explain Plan (either within SAP HANA Studio or
from the SQL command line) to verify that the query plan for a dynamic cached view has been created. In the
output, search for the operator name property HAVING - DYNAMIC VIEW CACHE. This is only created when the
dynamic result cache is active.
For further testing, note that if implicit matching was used using the hint
DYNAMIC_RESULT_CACHE_IMPLICIT_MATCH the operator name CONTROL SWITCH will include "AUTO VIEW
MATCH" details as one of its properties.
Build and Monitor the Cache
The cache is built for the rst time when you rst run the query.
Firstly, you can use the Visualize Plan tool to see which alternative plans are built for the query and which one is
executed. Note also the detailed execution times in the tool.
Secondly, you can see full details of the cache refresh process in the monitoring view
M_DYNAMIC_RESULT_CACHE. Select all details for the view:
select * from m_dynamic_result_cache where object_name = 'MyView';
Key values include: Refresh reason (initially 'Cache Creation'), Duration, State, Refresh_Count, Memory_Size,
Record_Count.
Measure the Delta Record Count After Updates
After executing some INSERT operations in the target table you can monitor how the cache is used in this
situation.
1. Use Visualize Plan to see which plan is executed. Check the row count numbers to see the eects of adding
new data to the table.
2. In the M_DYNAMIC_RESULT_CACHE view, the Delta_Refresh_Count shows an increase in how often delta
records have been added to the cache.
222
P U B L I C
SAP HANA Troubleshooting and Performance Analysis Guide
Tools and Tracing

Monitor Version Garbage Collection
Verify the eects of garbage collection by holding queries back for one minute until after the garbage collection
process has run.
In the M_DYNAMIC_RESULT_CACHE view, check the value of the last refresh reason time. This will show
'MVCC_GARBAGE_COLLECTION'.
Test Implicit Matching
To test Implicit Matching you can use the Explain Plan tool in SAP HANA Studio to analyze the details of the
execution and optimization processes. You can see which views have been considered by the optimization
process by looking at the result value returned by the following procedure:
GET_DYNAMIC_RESULT_CACHE_IMPLICIT_MATCH_CANDIDATES_IN_STATEMENT
The views that passed the checking phase, but were not selected in the rewriting phase of the process will be
marked as 'CANDIDATE MATCH'. Explain Plan will show the rewritten plan with the selected view name
replacing the original table(s) specied in the statement.
4.5 Tracing for Calculation View Queries
Additional tracing options are available for the calculation engine in SQL.
The tracing level for the calculation engine can be set for individual queries from the SQL command line using
support mode tracing. This uses a placeholder parameter $$CE_SUPPORT$$ which can be appended to an SQL
query. The parameter takes one or more value pairs specifying the trace level and the name of the trace you
wish to activate. The following example has three pairs which set the calcengine to debug, the optimizer to
information and the instantiate level to warning:
SELECT * FROM "<CALC_VIEW_SCHEMA>"."<CALC_VIEW_NAME>" WITH PARAMETERS
('PLACEHOLDER' = ('$$CE_SUPPORT$$','d_calcengine, i_ceoptimizerinfo,
w_ceinstantiate'))
The possible values for the trace component identiers are:
● calcengine
● calcenginegc
● ceexecute
● ceinstantiate
● cejoin
● cemonitor
● ceoptimizer
● ceoptimizerinfo
● ceoptimizerperf
● ceplanexec
● ceqetree
● ceqeutils
● ceqo
For full details of this option refer to SAP Note 2594739 - HANA Calculation Engine support mode tracing.
SAP HANA Troubleshooting and Performance Analysis Guide
Tools and Tracing
P U B L I C 223

Related Information
SAP Note 2594739
4.6 Advanced Analysis
If have you an advanced knowledge of SAP HANA and SQL databases and you suspect that automated
processes are making poor decisions that have negative impacts on query performance, you can perform
advanced analyses to better understand how those decisions were made.
In SAP HANA cockpit you can use specic tracing features to generate detailed trace information to help
analyze the following processes:
● Table joins using the join evaluation (je) trace
● Column searches using the query optimizer (qo) trace
Recommendation
Perform these types of analysis only if analyses of query plans and SQL statements were not enough to nd
the root cause of slow query performance.
Exporting SQL Plans
In the SAP HANA backend, the SQL Query Processor parses the SQL query statements and generates
optimized SQL Query Execution plans. As the Query Processor and the Query Optimizer continue to be
developed the resultant execution plans for a given query may change. All developments are of course intended
to improve performance but if you suspect that performance of a query might be worse after an upgrade, the
Abstract SQL Plan feature makes it possible to export an abstracted version of an execution plan and reuse it in
a dierent target system.
4.6.1 Analyzing Column Searches (qo trace)
In SAP HANA, if a column search takes a long time, you can analyze how the query-optimizer performed the
column search. A query-optimizer (qo) trace of a single SAP HANA table search provides the details you need
for such an analysis.
Context
The qo trace provides a lot of detailed information that is hard to analyze if you are not an SAP HANA query-
optimizer expert; however, it provides very useful information for performance analysis. From the information
within the trace les, you can see which column the query-optimizer decided to use as the rst column in the
column search and you can determine whether that decision negatively impacted the performance of the
column search.
224
P U B L I C
SAP HANA Troubleshooting and Performance Analysis Guide
Tools and Tracing
To start a user-specic qo trace in SAP HANA cockpit and analyze the relevant trace information, proceed as
follows.
Procedure
1. In SAP HANA Database Explorer choose Trace Conguration from the database context menu and create a
new user-specic trace.
The Trace Conguration dialog box opens.
2. Specify a context name.
The context name appears as part of the trace le name and should be easy for you to recognize and later
nd.
3. Specify your database user or application user.
4. Enter qo as lter text and search for the trex_qo component.
5. For the trex_qo component, select DEBUG as the system trace level.
6. Choose OK.
7. Run the query you want to trace.
8. Switch o the trace by deleting the user-specic trace conguration.
9. Search through the Database Diagnostic Files folder and locate the trace le. The le opens on a new tab
page.
10. In the trace section, analyze the trace information for each term (WHERE condition).
a. Find the sections detailing the estimated results for the terms.
These sections are marked with GetEstimation.cpp.
b. Find the sections detailing the actual search results for the terms.
These sections are marked with Evaluate.cpp.
c. Compare the estimated results with the actual search results.
The query-optimizer selects which column to use as the rst column of the search based on the term
with the lowest estimated number of results.
Results
If the actual results indicate that a dierent term should have been used to start the column search, then this
may represent the source of poor performance. For more detailed analysis, you can send the trace le to SAP
Support.
SAP HANA Troubleshooting and Performance Analysis Guide
Tools and Tracing
P U B L I C 225
4.6.2 Analyzing Table Joins
In SAP HANA, if a query on joined tables takes a long time, you can analyze how the tables are joined and in
what order. A join evaluation (je) trace of joined SAP HANA tables provides the details you need for such an
analysis.
Context
The je trace provides a lot of detailed information that is hard to analyze if you are not an SAP HANA join engine
expert; however, it provides very useful information for performance analysis. From the information within the
trace les, you can see which table is used as the rst table when processing a join and how the order of tables
in the join is dened. You can use this information to determine whether query performance is negatively
impacted by the table join.
To start a je trace in SAP HANA cockpit and analyze the relevant trace information, proceed as follows:
Procedure
1. In SAP HANA Database Explorer choose Trace Conguration from the database context menu and create a
new user-specic trace.
The Trace Conguration dialog box opens.
2. Specify a context name.
The context name appears as part of the trace le name and should be easy for you to recognize and later
nd.
3. Specify your database user or application user.
4. Enter join as lter text and search for the join_eval component.
5. For the join_eval component, select DEBUG as the system trace level.
6. Choose OK.
7. Run the query you want to trace.
8. Switch o the trace by deleting the user-specic trace conguration.
9. Search through the Database Diagnostic Files folder and locate the trace le. The le opens on a new tab
page.
10. From the end of the le, search backwards for the beginning of the trace section.
The trace section starts with i TraceContext TraceContext.cpp.
11. In the trace section, analyze the following trace information:
○ Estimations for the WHERE conditions
○ Table size and join conditions
○ Join decision
226
P U B L I C
SAP HANA Troubleshooting and Performance Analysis Guide
Tools and Tracing
4.6.3 SQL Plan Stability
SQL Plan Stability is a feature to protect the performance of queries by capturing query plans in a source
system and reusing them in a target system to regenerate the original query plan.
In SAP HANA, the SQL query processor parses SQL statements and generates SQL query execution plans. As
the query processor and the query optimizer continue to be developed (in, for example, the new HANA
Execution Engine - HEX) the resultant execution plans for a given query may change from one HANA release to
another and it is possible that some SQL query statements do not show equivalent performance in the new
system.
In order to guarantee the performance of a query after new system upgrades, the plan stability feature oers
the option to preserve a query's execution plan by capturing an abstraction of the plan and reusing it after the
upgrade to regenerate the original plan and retain the original performance. In some cases using statement
hints may provide a solution to a loss of performance; hints are available, for example, to control which
optimizing engine is used; refer to Statement Performance Analysis for details.
HANA 1 to HANA 2 Upgrade Scenario
The Plan Stability feature could be used, for example, when upgrading from SAP HANA 1 to SAP HANA 2. The
feature is available in SAP HANA 1.0 SPS 12 for capture purposes and from HANA 2.0 SPS01 for both capturing
and regenerating execution plans.
Use Cases and Process Overview
Plan Stability is currently only eective for SELECT queries and can be used in two situations; to capture
abstract SQL plans from queries:
● which are executed at the command line
● which are already stored in the plan cache.
Plan Stability requires the OPTIMIZER_ADMIN privilege. The feature is enabled by default and a two-stage
process (capture and regenerate from captured plans) is used based on the following SQL statements:
● Start / stop CAPTURE (optionally, capture cached statements)
● Start / stop APPLY, that is, start the process of matching executed queries with captured abstract plans.
Abstract SQL plans are visible in view ABSTRACT_SQL_PLANS and cached plans can be queried in
M_SQL_PLAN_CACHE_. The plan cache includes a value COMPILATION_OPTIONS which indicates what type
of plan was used (either normal query optimizer or abstract SQL plan) to create the cached statement. By
referring to these two views you can follow the stages of the capture and regeneration process and verify the
results of each step.
SQL statements are also available to enable, disable or remove abstract SQL plans from the
ABSTRACT_SQL_PLANS table.
The following section gives an overview of the process with examples of the main SQL commands used. Full
details of the SQL commands are available in the SAP HANA SQL and System Views Reference Guide.
Applying Workload Class Filters to the Capture Process
You can use ltering to limit the capture process to specic targets. You can lter either by user name or by
workload class property. Filtering by user name is done at run time as the capture process is initiated (an
example is given below), but to lter by workload class property the lters must be set in advance so that they
apply permanently; they can be removed when no longer required.
SAP HANA Troubleshooting and Performance Analysis Guide
Tools and Tracing
P U B L I C 227

The workload class properties are the following mapping property-value pairs that an application can set in the
client interface (see also Workload Management in the SAP HANA Administration Guide):
● APPLICATION USER NAME
● APPLICATION NAME
● USER NAME
● SCHEMA
● XS APPLICATION USER NAME
Filters which have been applied can be seen in the _SYS_PLAN_STABILITY view, they are shown in JSON
format in the FILTERS column.
The following examples illustrate the basic syntax and usage of this feature:
Example
This example sets two lter conditions. The lters are applied when the capture process is run and captures
only plans for App2 where the application user name is 'Test':
ALTER SYSTEM ADD ABSTRACT SQL PLAN FILTER 'MyFilter01' SET 'application
name'='App2', 'application user name'='TEST’;
The following example shows how a named lter can be removed; the keyword 'ALL' is also available to remove
all lters:
ALTER SYSTEM REMOVE ABSTRACT SQL PLAN FILTER 'MyFilter01';
Example
Queries are tested against all existing lters to nd a match. In the following example two lters have been
dened, if the conditions of the rst lter match with a query plan it will be captured, if not, the conditions of
the next lter will be tested:
ALTER SYSTEM ADD ABSTRACT SQL PLAN FILTER 'filter01' SET 'application name' in
[‘MyStudio’, ‘MyBiz’], 'application user name'='TEST’;
ALTER SYSTEM ADD ABSTRACT SQL PLAN FILTER 'filter02' SET 'User name'='SYSTEM'
'application name'='MyShop' 'application user name'='Employee25’, 'Employee26’;
This means Plan Stability will capture only queries with application properties where:
Application name is "MyStudio" OR "MyBiz" AND application user name is "TEST"
OR
User name is "SYSTEM" AND application name is "MyShop" AND application user name is "Employee25" OR
"Employee26".
228
P U B L I C
SAP HANA Troubleshooting and Performance Analysis Guide
Tools and Tracing

Using Plan Stability
Capture
The capture process must be explicitly started and stopped manually. The view
M_ABSTRACT_SQL_PLAN_OVERVIEW shows high-level details of activity related to abstract plans for each
instance of host and port, this includes current state (ready, capture, apply), the number of plans, memory
consumption and timestamps of the last capture period (start/stop time).
SQL lter keywords are available to restrict the capture to individual users; this example starts the capture
process for queries submitted by two named users:
ALTER SYSTEM START CAPTURE ABSTRACT SQL PLAN FOR USER TESTUSER1, TESTUSER2;
The capture process runs in the background while selected queries are executed. During the capture period an
abstract plan will be created for any newly submitted queries. The abstracted plan is in JSON format, it is not a
complete plan but contains logical plans and essential properties such as join algorithms and table locations.
Once all required queries are captured, stop the capture process by executing the CAPTURE command again
with the keyword STOP. Verify that the abstract plans have been created by referring to system view
ABSTRACT_SQL_PLANS. This view shows key details including the following:
Key Values in ABSTRACT_SQL_PLANS
Column Example / Detail
ABSTRACT_SQL_PLAN_ID 10003, 20003 etc.
HOST, PORT Abstract plans are saved on the basis of locations (host and port). These details
can be updated using the SQL statement UPDATE ABSTRACT SQL PLAN.
STATEMENT_STRING SQL SELECT statement.
PLAN_KEY Text string.
ABSTRACT_SQL_PLAN JSON formatted string.
IS_ENABLED Abstract plans can be enabled or disabled as required - see below.
IS_VALID If FALSE the captured plan cannot be used - see validity details below.
The following example uses the JSON_VALUE() function to select abstract plans for a given schema (the
variable $.session_user could be used to select plans for a given user):
SELECT * FROM ABSTRACT_SQL_PLANS WHERE JSON_VALUE(PLAN_KEY, '$.schema') =
'mySchema';
Capture WITH CACHE Option
An additional option is available to capture an abstraction of plans which are already cached. For this, the
keywords WITH SQL PLAN CACHE are required with the START statement:
ALTER SYSTEM START CAPTURE ABSTRACT SQL PLAN WITH SQL PLAN CACHE;
SAP HANA Troubleshooting and Performance Analysis Guide
Tools and Tracing
P U B L I C 229

This triggers a job (JOB_NAME Plan Stability) which runs and stops when complete. You can monitor its
progress in view M_JOB_PROGRESS. On completion you can verify that abstract plans have been stored in
ABSTRACT_SQL_PLANS using the select statement given in the example above.
Regenerating Plans (Apply)
To apply the plan stability feature and use the abstract SQL plans run the START APPLY statement:
ALTER SYSTEM START APPLY ABSTRACT SQL PLAN;
Now any newly compiled SELECT queries will be based, wherever possible, on the abstract SQL plans: queries
are checked against the stored abstract plans and used to generate an execution plan. You can stop the apply
period with the STOP APPLY statement.
Verication: In the plan cache you can see the source of a cached statement by referring to the
COMPILATION_OPTIONS value, this will be either empty (compiled by HANA SQL query optimizer) or
'ABSTRACT SQL PLAN' to indicate that the plan was regenerated from an abstract plan.
Enabling and Disabling
Abstract SQL plans can be enabled, disabled or removed from the ABSTRACT_SQL_PLANS table by referring
to the ID value. The following example uses a list of plan IDs, the keyword ALL is also available to enable all
plans (this sets IS_ENABLED to true):
ALTER SYSTEM ENABLE ABSTRACT SQL PLAN ENTRY FOR MyPlanID01, MyPlanID02;
If a plan is invalid (IS_VALID= FALSE) it will not be used even if it is selected; the query will be compiled using
the current version of the optimizer instead of the captured abstract plan. Reasons for invalidation include
failed checks on related objects and JSON deserialization failure. The reason is saved in the NOTES column of
the ABSTRACT_SQL_PLANS table.
The cache is automatically cleared in the background when certain events take place, that is, when the apply
phase is either started or stopped, when one or more plans are enabled or disabled or when one or more plans
are removed.
Changing Locations
If it is necessary to change the location details (host and port) of the server you can use the SQL statement
UPDATE ABSTRACT SQL PLAN. One scenario where this might be required is in high availability systems after
a failover when the secondary data center performs a takeover and becomes the production system. In this
case, it would be necessary to update the locations of all nodes. The following example illustrates a multi-node
scaleout scenario with two hosts, and uses the keyword ALL to update the location information of all plans:
ALTER SYSTEM UPDATE ABSTRACT SQL PLAN
SET LOCATION site1host1:30040 to site2host1:30040, site1host2:30040 to
site2host2:30040
FOR ALL;
Migrating Abstract SQL Plan After an Upgrade
When the system is upgraded, there might be changes to the internal structure of how the Abstract SQL Plan is
captured and stored. So, a migration is needed to the current structure after the upgrade. The migration can be
done using the following SQL statement:
ALTER SYSTEM MIGRATE ABSTRACT SQL PLAN;
230
P U B L I C
SAP HANA Troubleshooting and Performance Analysis Guide
Tools and Tracing
Tracing
The trace level for this feature is congurable by setting a conguration parameter in the [trace] section of the
indexserver.ini le. The default value of the PlanStability parameter is 'error', set this to 'debug' if
necessary for detailed trace information.
Related Information
Statement Performance Analysis [page 121]
4.7 Additional Analysis Tools for Support
To complement the standard tools for performance analysis, SAP HANA provides additional analysis tools that
SAP Support can use to help determine the cause of performance issues.
The following analysis tools are available in SAP HANA; however, these tools are intended only for use when
requested by SAP Support:
● Performance trace
This tool records performance indicators for individual query processing steps in database kernel.
● Kernel proler
This tool provides information about hotspots and expensive execution paths during query processing.
4.7.1 Performance Trace
The performance trace is a performance tracing tool built into the SAP HANA database. It records performance
indicators for individual query processing steps in the database kernel. You may be requested by SAP Support
to provide a performance trace.
Information collected includes the processing time required in a particular step, the data size read and written,
network communication, and information specic to the operator or processing-step-specic (for example,
number of records used as input and output). The performance trace can be enabled in multiple tenant
databases at the same time to analyze cross-database queries.
Performance Trace Files
Performance trace results are saved to the trace les with le extension *.tpt or *.cpt, which you can access
with other diagnosis les. To analyze these les, you need a tool capable of reading the output format (*.tpt and
*.cpt). SAP Support has tools for evaluating performance traces.
SAP HANA Troubleshooting and Performance Analysis Guide
Tools and Tracing
P U B L I C 231

Enabling and Conguring the Performance Trace
You can enable and congure the performance trace in the SAP HANA studio or using the ALTER SYSTEM *
PERFTRACE SQL statements.
Example
To start the performance trace execute ALTER SYSTEM START PERFTRACE.
Conguration Options
Option
Description
Trace le name The name of the le to which the trace data is automatically saved after the performance
trace is stopped
User and application lters Filters to restrict the trace to a single specic database user, a single specic application
user, and a single specic application
Trace execution plans You can trace execution plans in addition to the default trace data.
Function proler The function proler is a very ne-grained performance tracing tool based on source code
instrumentation. It complements the performance trace by providing even more detailed in
formation about the individual processing steps that are done in the database kernel.
Duration How long you want tracing to run
If a certain scenario is to be traced, ensure that you enter a value greater than the time it
takes the scenario to run. If there is no specic scenario to trace but instead general system
performance, then enter a reasonable value. After the specied duration, the trace stops au
tomatically.
Additional lter options are available in extended mode to restrict the trace data further.
For more information about how to congure the performance trace using SQL, see the SAP HANA SQL and
System Views Reference.
Related Information
ALTER SYSTEM {START | STOP} PERFTRACE Statement (System Management)
ALTER SYSTEM SAVE PERFTRACE Statement (System Management)
ALTER SYSTEM LOAD PERFTRACE Statement (System Management)
M_PERFTRACE System View
232
P U B L I C
SAP HANA Troubleshooting and Performance Analysis Guide
Tools and Tracing

4.7.2 Kernel Proler
The kernel proler is a sampling proler built into the SAP HANA database. It can be used to analyze
performance issues with systems on which third-party software cannot be installed, or parts of the database
that are not accessible by the performance trace. It is inactive by default.
The kernel prole collects, for example, information about frequent and/or expensive execution paths during
query processing.
Kernel Proler Traces
Proling results are saved to the trace les CPU_<service>_<host>_<port>_<timestamp>.<format> and
WAIT_<service>_<host>_<port>_<timestamp>.<format>, where <format> is either dot or
kcachegrind. You can access the proling results with other diagnosis les. To analyze these trace les
meaningfully you need a tool capable of reading the congured output format, that is KCacheGrind or DOT
(default format). Alternatively, send the les to SAP Support.
Enabling and Conguring the Kernel Proler
You enable and congure the kernel prole in the SAP HANA studio or the SAP HANA database explorer. It is
recommended that you start kernel proler tracing immediately before you execute the statements you want
to analyze and stop it immediately after they have nished. This avoids the unnecessary recording of irrelevant
statements. It is also advisable as this kind of tracing can negatively impact performance.
Note
To enable the kernel prole, you must have the SAP_INTERNAL_HANA_SUPPORT role. This role is intended
only for SAP HANA development support.
Conguration Options
Option
Description
Service(s) to prole The service(s) that you want to prole
Wait time The amount of time the kernel proler is to wait between call stack retrievals
When you activate the kernel proler, it retrieves the call stacks of relevant threads several
times. If a wait time is specied, it must wait the specied time minus the time the previous
retrieval took.
Memory limit Memory limit that will stop tracing
The kernel proler can potentially use a lot a memory. To prevent the SAP HANA database
from running out of memory due to proling, you can specify a memory limit that cannot be
exceeded.
SAP HANA Troubleshooting and Performance Analysis Guide
Tools and Tracing
P U B L I C 233
Option Description
Database user, application
user
The database user or application user you want to prole
Use KCachegrind format to
write trace les
Output format of trace les (congurable when you stop tracing)
Related Information
Diagnosis Files
4.7.3 Diagnosis Information
You can collect diagnosis information (a full system info dump) in the SAP HANA studio, in SAP HANA cockpit
or using command line scripts.
To collect this information in SAP HANA studio open the Administration Editor and navigate to Diagnosis
Files
Diagnosis Information . Use the Collect function to run the system dump and use the List function to
download the dump to a local le.
To collect this information in SAP HANA cockpit, on the system overview page, under Alerting & Diagnostics,
select Manage full system information dumps. On the Diagnosis Files page, choose a zip le from the list or click
Collect Diagnostics to create a new zip le.
The SQL variant can be used when SAP HANA is online, otherwise you can use the Python script
fullSystemInfoDump.py in the python_support directory (shortcut cdpy):
python fullSystemInfoDump.py
When the dump has completed you can download the le from the snapshots directory: /usr/sap/HAN/sys/
global/sapcontrol/snapshots
All options related to getting a system dump are fully described in SAP Note 1732157. This note also includes a
video demonstration of the process.
Tip
Guided Answers is a support tool for troubleshooting problems using decision trees. A guided answer is
available on How to generate a runtime dump.
Related Information
SAP Note 1732157
How to generate a runtime dump (Guided Answer)
234
P U B L I C
SAP HANA Troubleshooting and Performance Analysis Guide
Tools and Tracing

4.7.4 Analysis Tools in SAP HANA Web-based Developer
Workbench
There are a number of tools available for application performance analysis in the SAP HANA Web-based
Developer Workbench.
SQL Console
The extended SQL Console (part of the Catalog perspective) supports implicit and explicit performance
measurement while executing a SQL statement. It allows you to easily acquire sound measurement data and to
assess whether a SQL statement is problematic.
Implicit performance measurement can be triggered via F9 run command and provides execution time
information for the database, XS, and UI layers. Additional information to judge the measurement quality like
table locks and system alerts is also provided. Detailed performance analysis supports the repeated execution
of statements thus allows you to check whether performance characteristics are stable.
You can use this feature to quickly check SQL performance and to determine whether the observed poor
performance is caused by system load or variability.
SAP HANA Troubleshooting and Performance Analysis Guide
Tools and Tracing
P U B L I C 235

Expensive Statements Trace
The expensive statements trace in the Trace perspective allows you to quickly analyze how the SQL layer of
your SAP HANA system is used (globally or within a specic session/application). It allows you to analyze if the
SAP HANA database is used eectively and eciently for a given application.
The expensive statement view supports ltering for passport-based application sessions - if the trace is
congured accordingly by the system administrator and you run your application with SAP passport. For each
statement you can see metrics such as start time, number of processed records and many more.
Furthermore, a statistical summary is provided that gives insight on the overall SQL load. It details metrics such
as:
● Number of statements executed
● Number of unique statements executed
● Number of result records
Last, for each unique statement summary statistics are shown that detail the frequency of their usage as well
as aggregated duration metrics.
You can use the expensive statement trace to analyze:
● the overall SQL load in your current system
● the SQL interaction of a specic application, for example, to gure out if an application that is not currently
performing well due to an issue on the application layer or on the database layer.
Immediate Database Performance Feedback
This feature is part of the Immediate Feedback context in WebIDE.It provides a performance overview of all SQL
statements which are executed during an Immediate Feedback session, thus helps application developers to
immediately understand the number and performance of their DB-related statements.
236
P U B L I C
SAP HANA Troubleshooting and Performance Analysis Guide
Tools and Tracing

The Database Performance overview provides 3 metrics for each SQL statement: step, statement and
execution.
● Step: the actual immediate feedback step in which a SQL statement was executed
● Statement: the SQL statement
● Execution time: the execution time of the statement (in milliseconds)
You can use this feature to understand the performance behavior of the SQL statements (for example, nding
expensive statements that belong to a particular function) and exploit this understanding for possible further
performance investigations, like subsequently taking a dedicated measurement using the SQL Console.
SAP HANA Troubleshooting and Performance Analysis Guide
Tools and Tracing
P U B L I C 237

5 SAP HANA Database monitoring with
Solution Manager
This topic gives information about SAP HANA database monitoring with Solution Manager.
Setting up Solution Manager
SAP Solution Manager can be used to monitor one or more SAP HANA databases. A starting point to nd all
the information you require for the setup and conguration of the SAP HANA database monitoring using
solution manager can be found on the WIKI page
SAP HANA Operations with SAP Solution Manager
A detailed step by step description of the conguration and setup is given in the WIKI subpage Managed
System Setup for SAP HANA , the conguration and setup have dierent steps depending on the SAP HANA
database architecture and environment you have, for example, you may have Multitenant Database Containers
(MDC) and/ or system replication may be enabled in your environment.
There are two main steps:
1. You need to register the SAP HANA system you want to monitor in SLD
2. You need to do the managed system conguration steps for the HANA Database in the solution manager
system.
The Resolution part of the KBA 2436986 - Registration and Managed System Setup of SAP HANA in SAP
Solution Manager links you to the correct steps to follow depending on your HANA Architecture.
Troubleshooting when registering an SAP HANA Database in SLD
Before starting troubleshooting please double check that you have done the required conguration on the SAP
HANA database side and that you are aware of known documented issues. For this please refer to the SAP
HANA Database Administration Guide that is relevant for your HANA release and the notes referenced below:
In the SAP HANA Administration guide see the section Conguring a SAP HANA System to Connect to the
System Landscape Directory (SLD) .
If you are following the documentation above and the SLD registration is not successful please then check the
steps in the Resolution part of the KBA 2537537 - SLD does not update after registering HANA using HDBLCM
.
If you still face a problem with the registration of the SAP HANA database in SLD please review the known
issues described in the below notes as they may be relevant for the issue that you face:
Important Notes for SAP HANA SLD Registration:
● 2729787 - FAQ: HANA Data Supplier for System Landscape Directory (SLD) and Focused Run (FRUN)
238
P U B L I C
SAP HANA Troubleshooting and Performance Analysis Guide
SAP HANA Database monitoring with Solution Manager

● 2697518 - Patch Level in LMDB and SLD show the HANA DB Service Pack Number and not its Patch Level
● 2688902 - LMDB Shows Invalid Instance and Version Information for Products Installed on a SAP HANA
● 2607076 - Support of SLD Registration of an SAP HANA System Using Fully Qualied Domain Names
(FQDN) in SLDSYSTEMHOME and SLDVIRTDBHOME
● 2646035 - SLD Registration: The Former Primary Site of a System Replication Still Show the old Values in
SLD and Solution Manager After a Takeover
● 2577511 - Support of SLD Registration of a HANA System Replication or Multi Database Container Setup
.
If you are not successful in resolving the problem with the above information, SAP Support would require the
following tracing and logs to further analyse issue:
Log les required for SAP HANA Database SLD registration problems
MDC Environment:
1. Increase the trace level on SYSTEMDB by executing the following SQL:
alter system alter configuration('nameserver.ini','SYSTEM')
SET ('trace','sldconfig') = 'debug', ('trace','sldcollect') = 'debug',
('trace','sldsend') = 'debug' with reconfigure;
2. Trigger the SLD data supplier by executing the following sql on SYSTEMDB:
alter system alter configuration ('nameserver.ini','SYSTEM')
SET ('sld','enable') = 'false' with reconfigure;
alter system alter configuration ('nameserver.ini','SYSTEM')
SET ('sld','enable') = 'true' with reconfigure;
3. Reset the trace level on SYSTEMDB to default:
alter system alter configuration('nameserver.ini','SYSTEM')
UNSET ('trace','sldconfig'), ('trace','sldcollect'), ('trace','sldsend') with
reconfigure;
4. Create a full system info dump of SYSTEMDB ( 1732157 - Collecting diagnosis information for SAP HANA
[VIDEO] )
5. Provide the les slddest.cfg, sldreg.log and sldreg.xml from the HANA server:
/usr/sap/<SID>/HDB<instance>/<host>/trace/sldreg.xml sldreg.log/usr/sap/
<sid>/SYS/global/slddest.cfg
Additionally, from every HANA host on primary and in case of a system replication environment from every
host on secondary side:
/usr/sap/<SID>/profile/DEFAULT.PFL
6. Provide the content of the global.ini le by executing the sql command on SYSTEMDB and every tenant DB.
Provide the result as .csv le Select * from sys.m_inile_contents where le_name = 'global.ini' and
layer_name = 'SYSTEM';
What information is captured in the above SAP tracing?
SAP HANA Troubleshooting and Performance Analysis Guide
SAP HANA Database monitoring with Solution Manager
P U B L I C 239

nameserver.ini . > [trace]:
Trace Detail level
sldcollect = 'debug' lists every step of the data collection
sldcong = 'debug' lists the initial registration to SLD done by hdblcm
sldsend = 'debug' lists the path to the log le sldreg.log of the last data transfer
Managed system conguration of the SAP HANA Database in Solution
Manager
To perform the second step: managed system setup of the SAP HANA Database in solution manager please
refer to the following section of the SAP HANA Administration guide:
Connecting SAP Solution Manager to SAP HANA
Additional troubleshooting information for the SLD registration and the managed system setup of the SAP
HANA database in solution manager is available in the Wiki Trouble Shooting Guide for SAP Solution Manager
Operations for SAP HANA
Please be aware of the below knowledge repositories that described common issues and questions that come
up when using Solution Manager to monitor SAP HANA databases:
Important KBAs and Notes related to Solution Manager and HANA monitoring:
● 2374090 - SOLMAN_SETUP - BW Content Activation fails "ERROR: EC:2048" column store error: in
Solution Manager 7.2
● 2264627 - How to Troubleshoot Grey HANA Metrics in Technical Monitoring - SAP Solution Manager
● 2711824 - High Number of Prepared Statements Causing High Usage of Memory Allocator Pool/Statistics
● 2211415 - SAP HANA alerting composite SAP Note
● 2147247 - FAQ: SAP HANA Statistics Server
● 1991615 - Conguration options for the Embedded Statistics Service
Technical requirements for setting up secondary database connection from Solution Manager to SAP HANA
Database:
● 1597627 - SAP HANA connection
Important changes regarding how Solution Manager collects monitoring information from SAP HANA
Database:
With SAP HANA Revisions >= 122.02 the method used by Solution manager to collect the alerting relating
information from a manged SAP HANA Database has been changed and optimized in such a way that it
reduces the workload on the SAP HANA Database for the statistics collection. To use this new HANA
Monitoring mechanism changes may be required on the solution manager system and the SAP HANA
Database, further information can be found in the SAP note 2374272 - Enabling new HANA Monitoring
mechanism for Solution Manager
240
P U B L I C
SAP HANA Troubleshooting and Performance Analysis Guide
SAP HANA Database monitoring with Solution Manager

Monitoring Recommendations
You observe dierences in parameter value recommendations coming from a solution manager generated EWA
report, HANA Parameter check script HANA_Conguration_Parameters_1.00.90+.txt script from KBA
1969700 - SQL Statement Collection for SAP HANA and/or EWA workspace tool (ewaviewer) . The root
cause is often that the EWA report generated from a customer’s solution manager system does not have the
latest information on the parameter value recommendations due to outdated version of solution manager
system or ST-SER Release installed. Further information is available in the KBA: 2749491 - Dierences in EWA
report for HANA Parameter recommendations when compared with output of HANA parameter check script
HANA_Conguration_Parameters_1.00.90+.txt
SAP HANA Troubleshooting and Performance Analysis Guide
SAP HANA Database monitoring with Solution Manager
P U B L I C 241

6 Alerts and the Statistics Service
Alert checkers are part of the statistics service which is a central element of SAP HANA's internal monitoring
infrastructure.
The statistics service is a key administration resource which noties you when potentially critical situations
arise in your systems. The statistics service is described in detail in the SAP HANA Administration Guide.
Note
The statistics service was redeveloped and relaunched in SAP HANA 01 SPS 07. Users of older releases
may need to migrate and activate the new service as described in SAP Note 1917938 - Migration of the
statistics server for Revision 74 or higher.
Alert Checkers
A set of over 100 scheduled alert checkers run in the background monitoring the system for specic events.
Details of all these alerts are given in the reference table which follows.
Alerts are dened in the following two tables;
● _SYS_STATISTICS.STATISTICS_ALERT_INFORMATION
● _SYS_STATISTICS.STATISTICS_ALERT_THRESHOLDS
Each alert also has a corresponding entry in the following statistics scheduling tables:
● _SYS_STATISTICS.STATISTICS_OBJECTS
● _SYS_STATISTICS.STATISTICS_SCHEDULE
Congurable Severity Levels
Some alert checkers are dened with threshold values so that a degree of severity can be indicated if the alert
is triggered. Default values are available for all severity thresholds and these can be over-ridden by user-dened
values using the administration tools SAP HANA Studio and SAP HANA Cockpit. The scale of severity values is
from one to four (1 = Information, 2 = Low, 3 = Medium, 4 = High) and alerts can use any, none or all of these as
required depending on the event which is being monitored and the unit of measurement. The following
examples illustrate this:
Alert 31 License expiry. This alert checker is scheduled to run every 24 hours and counts the days remaining
until your license expires. It has three default threshold values Low (30 days), Medium (14 days), High (when
only 7 days are remaining).
Alert 99 Maintenance Status. This alert checker is scheduled to run every 720 hours and checks the installed
HANA version. It has a single Information-level threshold value which retrieves the installed support package
number (therefore no severity value is possible). This is referred to as an 'Information-only' type of alert.
Alert 22 Notication of all alerts. This alert checker is scheduled to run every 24 hours and sends an email if
any alerts have been raised in the last 24 hours. This type of 'boolean' alert does not retrieve any information
value which can be displayed and does not use any congurable severity value.
A history of changes made to threshold levels for each alert is maintained and can be seen in system view
STATISTICS_ALERT_THRESHOLDS_HISTORY.
242
P U B L I C
SAP HANA Troubleshooting and Performance Analysis Guide
Alerts and the Statistics Service

Conguration Tools
Alerts are congurable in either SAP HANA Studio or SAP HANA Cockpit:
● Studio: Administration Alerts tab
● Cockpit: Alerting and Diagnostics Congure Alerts
Conguration activities and administration features for both Studio and Cockpit are described in the SAP
HANA Administration Guide. You are recommended to use Cockpit which provides more options; it includes, for
example, the ability to disable alerts and to trigger an alert manually on demand. A limitation in Studio is that
only alerts with threshold values can be maintained; information-only alerts and the boolean-type are excluded
from the list of congurable alerts.
If an alert check fails for any reason it is automatically de-activated by the system for a period of at least 60
minutes (1 hour + the interval length). This is done by setting the value of the schedule status to 'Inactive'
(_SYS_STATISTICS.STATISTICS_SCHEDULE STATUS). Alert checkers are re-enabled automatically after the
timeout period by setting the schedule status to 'Idle' (this restart feature was introduced in HANA 01 SPS 09
Revision 93).
Refer to SAP Note 1991615 - Conguration options for the Embedded Statistics Service for more details of the
statistics service and examples of managing the service from the SQL command line.
Related Information
SAP HANA Administration Guide
SAP Note 1917938
SAP Note 1991615
6.1 Reference: Alerts
This reference section gives details of all alerts and includes links to any related SAP Notes.
All alerts include a recommended user action and for many alerts a corresponding SAP Note is available. In
column 4 of the following table ('Conguration') an asterisk '*' identies alerts which have multiple
congurable severity thresholds, Info-only alerts are agged by 'Info', and those with only a single congurable
value with '1'.
Alerts
ID Name Description Cfg User Action Category
Further Infor
mation
0 Internal statis
tics server prob
lem
Identies internal statistics
server problem.
Resolve the problem. For
more information, see the
trace les. You may need to
activate tracing rst.
Availability
SAP Note:
1803039
SAP HANA Troubleshooting and Performance Analysis Guide
Alerts and the Statistics Service
P U B L I C 243

ID Name Description Cfg User Action Category
Further Infor
mation
1 Host physical
memory usage
Determines what percentage
of total physical memory
available on the host is used.
All processes consuming
memory are considered, in
cluding non-SAP HANA proc
esses.
*
Investigate memory usage of
processes.
Note
Only relevant in HANA
1.0. Not active in HANA
2.0. See SAP Note:
2757696 Alert 1
shows wrong information
Memory
SAP Note:
1898317 SAP
Note:1840954
2 Disk usage Determines what percentage
of each disk containing data,
log, and trace les is used.
This includes space used by
non-SAP HANA les.
*
Investigate disk usage of
processes. Increase disk
space, for example by shrink
ing volumes, deleting diagno
sis les, or adding additional
storage.
Disk
SAP Note:
1900643
3 Inactive services Identies inactive services. 1 Investigate why the service is
inactive, for example, by
checking the service's trace
les.
Availability
Inactive > 600
seconds. SAP
Note:
1902033
4 Restarted serv
ices
Identies services that have
restarted since the last time
the check was performed.
Investigate why the service
had to restart or be re
started, for example, by
checking the service's trace
les.
Availability
SAP Note:
1909660
5 Host CPU Usage Determines the percentage
CPU idle time on the host
and therefore whether or not
CPU resources are running
low.
*
Investigate CPU usage. CPU SAP Note:
1909670
10 Delta merge
(mergedog) con
guration
Determines whether or not
the 'active' parameter in the
'mergedog' section of system
conguration le(s) is 'yes'.
mergedog is the system
process that periodically
checks column tables to de
termine whether or not a
delta merge operation needs
to be executed.
Change in SYSTEM layer the
parameter active in sec
tion(s) mergedog to yes
Congura-
tion
SAP Note:
1909641
12 Memory usage
of name server
Determines what percentage
of allocated shared memory
is being used by the name
server on a host.
*
Increase the shared memory
size of the name server. In
the 'topology' section of the
nameserver.ini le, increase
the value of the 'size' param
eter.
Memory
SAP Note:
1977101
244 P U B L I C
SAP HANA Troubleshooting and Performance Analysis Guide
Alerts and the Statistics Service

ID Name Description Cfg User Action Category
Further Infor
mation
16 Lock wait time
out congura-
tion
Determines whether the
'lock_wait_timeout' parame
ter in the 'transaction' sec
tion of the indexserver.ini le
is between 100,000 and
7,200,000.
In the 'transaction' section of
the indexserver.ini le, set
the 'lock_wait_timeout' pa
rameter to a value between
100,000 and 7,200,000 for
the System layer.
Congura-
tion
SAP Note:
1909707
17 Record count of
non-partitioned
column-store ta
bles
Determines the number of
records in non-partitioned
column-store tables. Current
table size is not critical. Parti
tioning need only be consid
ered if tables are expected to
grow rapidly (a non-parti
tioned table cannot contain
more than 2,147,483,648 (2
billion) rows).
Info
Consider partitioning the ta
ble only if you expect it to
grow rapidly.
Memory SAP HANA Ad
ministration
Guide > Table
Partitioning, SAP
Note:
1909763
20
Table growth of
non-partitioned
column-store ta
bles
Determines the growth rate
of non-partitioned columns
tables.
*
Consider partitioning the ta
ble. See also: Guided Answer:
How to reduce the size of a
table.
Memory
SAP HANA Ad
ministration
Guide > Table
Partitioning, SAP
Note:
1910140
21
Internal event Identies internal database
events.
* Resolve the event and then
mark it as resolved by exe
cuting the SQL statement
ALTER SYSTEM SET EVENT
HANDLED '<host>:<port>'
<id>. Note that this is not
necessary for INFO events.
Availability
SAP Note:
1977252
22 Notication of all
alerts
Determines whether or not
there have been any alerts
since the last check and if so,
sends a summary e-mail to
specied recipients.
Investigate the alerts.
Availability
23 Notication of
medium and
high priority
alerts
Determines whether or not
there have been any medium
and high priority alerts since
the last check and if so,
sends a summary e-mail to
specied recipients.
Investigate the alerts.
Availability
24 Notication of
high priority
alerts
Determines whether or not
there have been any high pri
ority alerts since the last
check and if so, sends a sum
mary e-mail to specied re
cipients.
Investigate the alerts.
Availability
SAP HANA Troubleshooting and Performance Analysis Guide
Alerts and the Statistics Service
P U B L I C 245

ID Name Description Cfg User Action Category
Further Infor
mation
25 Open connec
tions
Determines what percentage
of the maximum number of
permitted SQL connections
are open. The maximum
number of permitted con
nections is congured in the
"session" section of the in
dexserver.ini le.
*
Investigate why the maxi
mum number of permitted
open connections is being
approached.
Sessions/
Transac
tions
SAP Note:
1910159
26 Unassigned vol
umes
Identies volumes that are
not assigned a service.
Investigate why the volume is
not assigned a service. For
example, the assigned serv
ice is not active, the removal
of a host failed, or the re
moval of a service was per
formed incorrectly.
Congura-
tion
SAP Note:
1910169
27 Record count of
column-store ta
ble partitions
Determines the number of
records in the partitions of
column-store tables. A table
partition cannot contain
more than 2,000,000,000 (2
billion) rows.
*
Consider repartitioning the
table.
Memory SAP HANA Ad
ministration
Guide > Table
Partitioning, SAP
Note:
1910188
28
Most recent sa
vepoint opera
tion
Determines how long ago the
last savepoint was dened,
that is, how long ago a com
plete, consistent image of the
database was persisted to
disk.
*
Investigate why there was a
delay dening the last save
point and consider triggering
the operation manually by
executing the SQL statement
ALTER SYSTEM SAVEPOINT.
Disk
SAP Note:
1977291
29 Size of delta
storage of col
umn-store ta
bles
Determines the size of the
delta storage of column ta
bles.
* Investigate the delta merge
history in the monitoring
view M_DELTA_MERGE_STA
TISTICS. Consider merging
the table delta manually.
Memory
SAP Note:
1977314
30 Check internal
disk full event
Determines whether or not
the disks to which data and
log les are written are full. A
disk-full event causes your
database to stop and must
be resolved.
*
Resolve the disk-full event as
follows: In the Administration
Editor on the Overview tab,
choose the "Disk Full Events"
link and mark the event as
handled. Alternatively, exe
cute the SQL statements AL
TER SYSTEM SET EVENT
ACKNOWLEDGED
'<host>:<port>' <id> and AL
TER SYSTEM SET EVENT
HANDLED '<host>:<port>'
<id>.
Disk
SAP Note:
1898460
246 P UB L IC
SAP HANA Troubleshooting and Performance Analysis Guide
Alerts and the Statistics Service

ID Name Description Cfg User Action Category
Further Infor
mation
31 License expiry Determines how many days
until your license expires.
Once your license expires,
you can no longer use the
system, except to install a
new license.
*
Obtain a valid license and in
stall it. For the exact expira
tion date, see the monitoring
view M_LICENSE.
Availability
Security, Author
ization and Li
censing, SAP
Note:
1899480
32
Log mode LEG
ACY
Determines whether or not
the database is running in log
mode "legacy". Log mode
"legacy" does not support
point-in-recovery and is not
recommended for productive
systems.
If you need point-in-time re
covery, recongure the log
mode of your system to "nor
mal". In the "persistence"
section of the global.ini con
guration le, set the param
eter "log_mode" to "normal"
for the System layer. When
you change the log mode,
you must restart the data
base system to activate the
changes. It is also recom
mended that you perform a
full data backup.
Backup
Conguration
Parameter Is
sues. SAP Note:
1900296
33
Log mode OVER
WRITE
Determines whether or not
the database is running in log
mode "overwrite". Log mode
"overwrite" does not support
point-in-recovery (only recov
ery to a data backup) and is
not recommended for pro
ductive systems.
If you need point-in-time re
covery, recongure the log
mode of your system to "nor
mal". In the "persistence"
section of the global.ini con
guration le, set the param
eter "log_mode" to "normal"
for the System layer. When
you change the log mode,
you must restart the data
base system to activate the
changes. It is also recom
mended that you perform a
full data backup.
Backup
SAP HANA Ad
ministration
Guide > Backing
up and Recover
ing the SAP
HANA Database.
SAP Note:
1900267
34
Unavailable vol
umes
Determines whether or not
all volumes are available.
Investigate why the volume is
not available.
Congura-
tion
SAP HANA Ad
ministration
Guide > Backing
up and Recover
ing the SAP
HANA Database,
SAP Note:
1900682
35
Existence of
data backup
Determines whether or not a
data backup exists. Without a
data backup, your database
cannot be recovered.
Perform a data backup as
soon as possible.
Backup SAP HANA Ad
ministration
Guide > Backing
up and Recover
ing the SAP
HANA Database,
SAP Note:
1900728
SAP HANA Troubleshooting and Performance Analysis Guide
Alerts and the Statistics Service
P U B L I C 247

ID Name Description Cfg User Action Category
Further Infor
mation
36 Status of most
recent data
backup
Determines whether or not
the most recent data backup
was successful.
Investigate why the last data
backup failed, resolve the
problem, and perform a new
data backup as soon as pos
sible.
Backup
SAP HANA Ad
ministration
Guide > Backing
up and Recover
ing the SAP
HANA Database,
SAP Note:
1900795
37
Age of most re
cent data
backup
Determines the age of the
most recent successful data
backup.
* Perform a data backup as
soon as possible.
Backup SAP HANA Ad
ministration
Guide > Backing
up and Recover
ing the SAP
HANA Database,
SAP Note:
1900730
38
Status of most
recent log back
ups
Determines whether or not
the most recent log backups
for services and volumes
were successful.
Investigate why the log
backup failed and resolve the
problem.
Backup SAP HANA Ad
ministration
Guide > Backing
up and Recover
ing the SAP
HANA Database,
SAP Note:
1900788
39
Long-running
statements
Identies long-running SQL
statements.
* Investigate the statement.
For more information, see
the table _SYS_STATIS
TICS.HOST_LONG_RUN
NING_STATEMENTS.
Sessions/
Transac
tions
SAP Note:
1849392
40 Total memory
usage of col
umn-store ta
bles
Determines what percentage
of the eective allocation
limit is being consumed by
individual column-store ta
bles as a whole (that is, the
cumulative size of all of a ta
ble's columns and internal
structures)
*
Consider partitioning or re
partitioning the table.
Memory SAP Note:
1977268
41 In-memory Da
taStore activa
tion
Determines whether or not
there is a problem with the
activation of an in-memory
DataStore object.
For more information, see
the table _SYS_STATIS
TICS.GLOBAL_DEC_EX
TRACTOR_STATUS and SAP
Note 1665553.
Availability
SAP Note:
1665553 SAP
Note:1977230
248 P U B L I C
SAP HANA Troubleshooting and Performance Analysis Guide
Alerts and the Statistics Service

ID Name Description Cfg User Action Category
Further Infor
mation
42 Long-running /
idling cursors.
Identies long-running /
idling cursors.
* Close the cursor in the appli
cation, or kill the connection
by executing the SQL state
ment ALTER SYSTEM DIS
CONNECT SESSION <LOGI
CAL_CONNECTION_ID>. For
more information, see the ta
ble HOST_LONG_IDLE_CUR
SOR (_SYS_STATISTICS).
Sessions/
Transac
tions
SAP Note:
1900261
43 Memory usage
of services
Determines what percentage
of its eective allocation limit
a service is using.
* Check for services that con
sume a lot of memory.
Memory SAP Note:
1900257
44 Licensed mem
ory usage
Determines what percentage
of licensed memory is used.
Info Increase licensed amount of
main memory. You can see
the peak memory allocation
since installation in the sys
tem view M_LICENSE (col
umn PRODUCT_USAGE).
Memory
SAP Note:
1899511
45 Memory usage
of main storage
of column-store
tables
Determines what percentage
of the eective allocation
limit is being consumed by
the main storage of individual
column-store tables.
*
Consider partitioning or re
partitioning the table.
Memory SAP Note:
1977269
46 RTEdump les Identies new runtime dump
les (*rtedump*) have been
generated in the trace direc
tory of the system. These
contain information about,
for example, build, loaded
modules, running threads,
CPU, and so on.
Check the contents of the
dump les.
Diagnosis
Files
SAP Note:
1977099
47 Long-running se
rializable trans
actions
Identies long-running serial
izable transactions.
* Close the serializable trans
action in the application or
kill the connection by execut
ing the SQL statement AL
TER SYSTEM DISCONNECT
SESSION <LOGICAL_CON
NECTION_ID>. For more in
formation, see the table
HOST_LONG_SERIALIZA
BLE_TRANSACTION
(_SYS_STATISTICS).
Sessions/
Transac
tions
Transactional
Problems
SAP HANA Troubleshooting and Performance Analysis Guide
Alerts and the Statistics Service
P U B L I C 249

ID Name Description Cfg User Action Category
Further Infor
mation
48 Long-running
uncommitted
write transac
tions
Identies long-running un
committed write transac
tions.
* Close the uncommitted
transaction in the application
or kill the connection by exe
cuting the SQL statement
ALTER SYSTEM DISCON
NECT SESSION <LOGI
CAL_CONNECTION_ID>. For
more information, see the ta
ble HOST_UNCOMMIT
TED_WRITE_TRANSACTION
(_SYS_STATISTICS).
Sessions/
Transac
tions
SAP Note:
1977276
49 Long-running
blocking situa
tions
Identies long-running block
ing situations.
* Investigate the blocking and
blocked transactions and if
appropriate cancel one of
them.
Sessions/
Transac
tions
SAP Note:
2079396
50 Number of diag
nosis les
Determines the number of di
agnosis les written by the
system (excluding zip-les).
An unusually large number of
les can indicate a problem
with the database (for exam
ple, problem with trace le
rotation or a high number of
crashes).
1
Investigate the diagnosis
les.
Diagnosis
Files
See KBA
1977162, SAP
Note:
1977162
51 Size of diagnosis
les
Identies large diagnosis
les. Unusually large les can
indicate a problem with the
database.
*
Check the diagnosis les in
the SAP HANA studio for de
tails.
Diagnosis
Files
See KBA
1977208, SAP
Note:
1977208
52 Crashdump les Identies new crashdump
les that have been gener
ated in the trace directory of
the system.
Check the contents of the
dump les.
Diagnosis
Files
SAP Note:
1977218
53 Pagedump les Identies new pagedump
les that have been gener
ated in the trace directory of
the system.
Check the contents of the
dump les.
Diagnosis
Files
SAP Note:
1977242
54 Savepoint dura
tion
Identies long-running save
point operations.
* Check disk I/O performance. Backup CPU Related
Root Causes and
Solutions, I/O
Related Root
Causes and Sol
utions, SAP
Note:
1977220
55
Columnstore un
loads
Determines how many col
umns in columnstore tables
have been unloaded from
memory. This can indicate
performance issues.
*
Check sizing with respect to
data distribution.
Memory SAP Note:
1977207
250 P U B LI C
SAP HANA Troubleshooting and Performance Analysis Guide
Alerts and the Statistics Service

ID Name Description Cfg User Action Category
Further Infor
mation
56 Python trace ac
tivity
Determines whether or not
the python trace is active and
for how long. The python
trace aects system per
formance.
*
If no longer required, deacti
vate the python trace in the
relevant conguration le.
Diagnosis
Files
SAP Note:
1977098
57 Instance secure
store le system
(SSFS) inacces
sible
Determines if the instance
secure store in the le sys
tem (SSFS) of your SAP
HANA system is accessible
to the database.
Check and make sure that
the instance SSFS is accessi
ble to the database.
Security SAP Note:
1977221
58 Plan cache size Determines whether or not
the plan cache is too small.
Info Currently Alert 58 is inactive
and replaced by Alert 91.
Please activate Alert 91 - Plan
Cache Hit Ratio
Memory
SAP Note:
1977253
59 Percentage of
transactions
blocked
Determines the percentage
of transactions that are
blocked.
* Investigate blocking and
blocked transactions and if
appropriate cancel some of
them.
Sessions/
Transac
tions
SAP Note:
2081856
60 Sync/Async
read ratio
Identies a bad trigger asyn
chronous read ratio. This
means that asynchronous
reads are blocking and be
have almost like synchronous
reads. This might have nega
tive impact on SAP HANA I/O
performance in certain sce
narios.
Info
Please refer to SAP note
1930979.
Disk I/O Related Root
Causes and Sol
utions, SAP
Note:
1965379
61
Sync/Async
write ratio
Identies a bad trigger asyn
chronous write ratio. This
means that asynchronous
writes are blocking and be
have almost like synchronous
writes. This might have nega
tive impact on SAP HANA I/O
performance in certain sce
narios.
Info
Please refer to SAP note
1930979.
Disk I/O Related Root
Causes and Sol
utions, SAP
Note:
1965379
SAP HANA Troubleshooting and Performance Analysis Guide
Alerts and the Statistics Service
P U B L I C 251

ID Name Description Cfg User Action Category
Further Infor
mation
62 Expiration of da
tabase user
passwords
Identies database users
whose password is due to ex
pire in line with the cong-
ured password policy. If the
password expires, the user
will be locked. If the user in
question is a technical user,
this may impact application
availability. It is recom
mended that you disable the
password lifetime check of
technical users so that their
password never expires (AL
TER USER <username> DIS
ABLE PASSWORD LIFE
TIME).
Change the password of the
database user.
Security SAP Note:
2082406
63 Granting of
SAP_INTER
NAL_HANA_SU
PPORT role
Determines if the internal
support role (SAP_INTER
NAL_HANA_SUPPORT) is
currently granted to any da
tabase users.
1
Check if the corresponding
users still need the role. If
not, revoke the role from
them.
Security
SAP Note:
2081857
64 Total memory
usage of table-
based audit log
Determines what percentage
of the eective memory allo
cation limit is being con
sumed by the database table
used for table-based audit
logging. If this table grows
too large, the availability of
the database could be im
pacted.
*
Consider exporting the con
tent of the table and then
truncating the table.
Memory SAP Note:
2081869
65 Runtime of the
log backups cur
rently running
Determines whether or not
the most recent log backup
terminates in the given time.
* Investigate why the log
backup runs for too long, and
resolve the issue.
Backup SAP HANA Ad
ministration
Guide, SAP
Note:
2081845
66
Storage snap
shot is prepared
Determines whether or not
the period, during which the
database is prepared for a
storage snapshot, exceeds a
given threshold.
*
Investigate why the storage
snapshot was not conrmed
or abandoned, and resolve
the issue.
Backup
SAP HANA Ad
ministration
Guide, SAP
Note:
2081405
67
Table growth of
rowstore tables
Determines the growth rate
of rowstore tables
* Try to reduce the size of row
store table by removing un
used data
Memory SAP Note:
2054411
68 Total memory
usage of row
store
Determines the current
memory size of a row store
used by a service
* Investigate memory usage by
row store tables and consider
cleanup of unused data
Memory SAP Note:
2050579
252 P U B L I C
SAP HANA Troubleshooting and Performance Analysis Guide
Alerts and the Statistics Service

ID Name Description Cfg User Action Category
Further Infor
mation
69 Enablement of
automatic log
backup
Determines whether auto
matic log backup is enabled.
Enable automatic log backup.
For more details please see
SAP HANA Administration
Guide.
Backup
SAP HANA Ad
ministration
Guide, SAP
Note:
2081360
70
Consistency of
internal system
components af
ter system up
grade
Veries the consistency of
schemas and tables in inter
nal system components (for
example, the repository) af
ter a system upgrade.
Contact SAP support.
Availability
71 Row store frag
mentation
Check for fragmentation of
row store.
Implement SAP Note
1813245.
Memory SAP Note:
1813245
72 Number of log
segments
Determines the number of
log segments in the log vol
ume of each serviceCheck
for number of log segments.
*
Make sure that log backups
are being automatically cre
ated and that there is enough
space available for them.
Check whether the system
has been frequently and un
usually restarting services. If
it has, then resolve the root
cause of this issue and create
log backups as soon as pos
sible.
Backup
75 Rowstore ver
sion space skew
Determines whether the row
store version chain is too
long.
* Identify the connection or
transaction that is blocking
version garbage collection.
You can do this in the SAP
HANA studio by executing
"MVCC Blocker Statement"
and "MVCC Blocker Transac
tion" available on the System
Information tab of the Ad
ministration editor. If possi
ble, kill the blocking connec
tion or cancel the blocking
transaction. For your infor
mation, you can nd table in
formation by using query
"SELECT * FROM TABLES
WHERE TABLE_OID = <table
object ID>".
Memory
Transactional
Problems
76 Discrepancy be
tween host
server times
Identies discrepancies be
tween the server times of
hosts in a scale-out system.
* Check operating system time
settings.
Congura-
tion
77 Database disk
usage
Determines the total used
disk space of the database.
All data, logs, traces and
backups are considered.
*
Investigate the disk usage of
the database. See system
view M_DISK_USAGE for
more details.
Disk
SAP HANA Troubleshooting and Performance Analysis Guide
Alerts and the Statistics Service
P U B L I C 253

ID Name Description Cfg User Action Category
Further Infor
mation
78 Connection be
tween systems
in system repli
cation setup
Identies closed connections
between the primary system
and a secondary system. If
connections are closed, the
primary system is no longer
being replicated.
Investigate why connections
are closed (for example, net
work problem) and resolve
the issue.
Availability
SAP HANA Ad
ministration
Guide
79 Conguration
consistency of
systems in sys
tem replication
setup
Identies conguration pa
rameters that do not have
the same value on the pri
mary system and a secon
dary system. Most congura-
tion parameters should have
the same value on both sys
tems because the secondary
system has to take over in
the event of a disaster.
If the identied conguration
parameter(s) should have
the same value in both sys
tems, adjust the congura-
tion. If dierent values are
acceptable, add the parame
ter(s) as an exception in
global.ini/[inile_checker].
Congura-
tion
SAP HANA Ad
ministration
Guide
80 Availability of ta
ble replication
Monitors error messages re
lated to table replication.
Determine which tables en
countered the table replica
tion error using system view
M_TABLE_REPLICAS, and
then check the correspond
ing indexserver alert traces.
Availability
81 Cached view size Determines how much mem
ory is occupied by cached
view
* Increase the size of the
cached view. In the "re
sult_cache" section of the in
dexserver.ini le, increase the
value of the "total_size" pa
rameter.
Memory
82 Timezone con
version
Compares SAP HANA inter
nal timezone conversion with
Operating System timezone
conversion.
*
Update SAP HANA internal
timezone tables (refer to SAP
note 1932132).
Congura-
tion
SAP Note:
1932132
83 Table consis
tency
Identies the number of er
rors and aected tables de
tected by _SYS_STATIS
TICS.Collector_Global_Ta
ble_Consistency.
*
Contact SAP support. Availability
84 Insecure in
stance SSFS en
cryption cong-
uration
Determines whether the
master key of the instance
secure store in the le sys
tem (SSFS) of your SAP
HANA system has been
changed. If the SSFS master
key is not changed after in
stallation, it cannot be guar
anteed that the initial key is
unique.
Change the instance SSFS
master key as soon as possi
ble. For more information,
see the SAP HANA Adminis
tration Guide.
Security
SAP HANA Ad
ministration
Guide
254 P U B L I C
SAP HANA Troubleshooting and Performance Analysis Guide
Alerts and the Statistics Service

ID Name Description Cfg User Action Category
Further Infor
mation
85 Insecure sys
temPKI SSFS
encryption con
guration
Determines whether the
master key of the secure
store in the le system
(SSFS) of your system's in
ternal public key infrastruc
ture (system PKI) has been
changed. If the SSFS master
key is not changed after in
stallation, it cannot be guar
anteed that the initial key is
unique.
Change the system PKI SSFS
master key as soon as possi
ble. For more information,
see the SAP HANA Adminis
tration Guide.
Security
SAP HANA Ad
ministration
Guide
86 Internal commu
nication is con
gured too
openly
Determines whether the
ports used by SAP HANA for
internal communication are
securely congured. If the
"listeninterface" property in
the "communication" section
of the global.ini le does not
have the value ".local" for sin
gle-host systems and ".all" or
".global" for multiple-host
systems, internal communi
cation channels are exter
nally exploitable.
The parameter [communica
tion] listeninterface in
global.ini is not set to a se
cure value. Please refer to
SAP Note 2183363 or the
section on internal host
name resolution in the SAP
HANA Administration Guide.
Security
SAP Note:
2183363
87 Granting of SAP
HANA DI sup
port privileges
Determines if support privi
leges for the SAP HANA De
ployment Infrastructure (DI)
are currently granted to any
database users or roles.
Check if the corresponding
users still need the privileges.
If not, revoke the privileges
from them.
Security
88 Auto merge for
column-store ta
bles
Determines if the delta
merge of a table was exe
cuted successfully or not.
* The delta merge was not exe
cuted successfully for a ta
ble. Check the error descrip
tion in view
M_DELTA_MERGE_STATIS
TICS and also Indexserver
trace.
Memory
89 Missing volume
les
Determines if there is any
volume le missing.
Volume le missing, data
base instance is broken, stop
immediately all operations
on this instance.
Congura-
tion
90 Status of HANA
platform lifecy
cle management
conguration
Determines if the system was
not installed/updated with
the SAP HANA Database
Lifecycle Manager
(HDBLCM).
Install/update SAP HANA
Database Lifecycle Manager
(HDBLCM). Implement SAP
note 2078425
Congura-
tion
SAP Note:
2078425
SAP HANA Troubleshooting and Performance Analysis Guide
Alerts and the Statistics Service
P U B L I C 255

ID Name Description Cfg User Action Category
Further Infor
mation
91 Plan cache hit
ratio
Determines whether or not
the plan cache hit ratio is too
low.
* Increase the size of the plan
cache. In the "sql" section of
the indexserver.ini le, in
crease the value of the
"plan_cache_size" parame
ter.
Memory
92 Root keys of per
sistent services
are not properly
synchronized
Not al services that persist
data could be reached the
last time the root key change
of the data volume encryp
tion service was changed. As
a result, at least one service
is running with an old root
key.
Trigger a savepoint for this
service or ush the SSFS
cache using hdbcons
Security
93 Streaming Li
cense expiry
Determines how many days
until your streaming license
expires. Once your license ex
pires, you can no longer start
streaming projects.
*
Obtain a valid license and in
stall it. For the exact expira
tion date, see the monitoring
view M_LICENSES.
Availability
94 Log replay back
log for system
replication sec
ondary
System Replication secon
dary site has a higher log re
play backlog than expected.
* Investigate on secondary
site, why log replay backlog is
increased
Availability
95 Availability of
Data Quality ref
erence data (di
rectory les)
Determine the Data Quality
reference data expiration
dates.
* Download the latest Data
Quality reference data les
and update the system. (For
more details about updating
the directories, see the In
stallation and Conguration
Guide for SAP HANA Smart
Data Integration and SAP
HANA Smart Data Quality.)
Availability
Installation and
Conguration
Guide for SAP
HANA Smart
Data Integration
and SAP HANA
Smart Data
Quality
96
Long-running
tasks
Identies all long-running
tasks.
* Investigate the long-running
tasks. For more information,
see the task statistics tables
or views in _SYS_TASK
schema and trace log.
97
Granting of SAP
HANA DI con
tainer import
privileges
Determines if the container
import feature of the SAP
HANA Deployment Infra
structure (DI) is enabled and
if import privileges for SAP
HANA DI containers are cur
rently granted to any data
base users or roles.
Check if the identied users
still need the privileges. If
not, revoke the privileges
from them and disable the
SAP HANA DI container im
port feature.
Security
98 LOB garbage
collection activ
ity
Determines whether or not
the lob garbage collection is
activated.
Activate the LOB garbage
collection using the corre
sponding conguration pa
rameters.
Congura-
tion
256 P U B L I C
SAP HANA Troubleshooting and Performance Analysis Guide
Alerts and the Statistics Service

ID Name Description Cfg User Action Category
Further Infor
mation
99 Maintenance
Status
Checks the installed SP ver
sion against the recom
mended SP version.
* Please consider upgrading to
the recommended SP ver
sion.
Congura-
tion
100 Unsupported
operating sys
tem in use
Determines if the operating
system of the SAP HANA Da
tabase hosts is supported.
Upgrade the operating sys
tem to a supported version
(see SAP HANA Master
Guide for more information).
Congura-
tion
101 SQL access for
SAP HANA DI
technical users
Determines if SQL access
has been enabled for any
SAP HANA DI technical
users. SAP HANA DI techni
cal users are either users
whose names start with
'_SYS_DI' or SAP HANA DI
container technical users
(<container name>, <con
tainer name>DI, <container
name>OO).
Check if the identied users
('_SYS_DI*' users or SAP
HANA DI container technical
users) still need SQL access.
If not, disable SQL access for
these users and deactivate
the users.
Security
102 Existence of sys
tem database
backup
Determines whether or not a
system database backup ex
ists. Without a system data
base backup, your system
cannot be recovered.
Perform a backup of the sys
tem database as soon as
possible.
Backup
103 Usage of depre
cated features
Determines if any deprecated
features were used in the last
interval.
Check the view M_FEA
TURE_USAGE to see which
features were used. Refer to
SAP Note 2425002 for fur
ther information.
104
System replica
tion: increased
log shipping
backlog
Monitors log shipping back
log. Alert is raised when
threshold value is reached
(priority dependent on
threshold values).
*
To identify the reason for the
increased system replication
log shipping backlog, check
the status of the secondary
system. Possible causes for
the increased system replica
tion log shipping backlog can
be a slow network perform
ance, connection problems,
or other internal issues.
105
Total Open
Transactions
Check
Monitors the number of open
transactions per service.
* Double check if the applica
tion is closing the connection
correctly, and whether the
high transaction load on the
system is expected.
Sessions/
Transac
tions
106 ASYNC replica
tion in-memory
buer overow
Checks if local in-memory
buer in ASYNC replication
mode runs full.
Check buer size, peak
loads, network, IO on secon
dary.
Availability
107 Inconsistent fall
back snapshot
Checks for inconsistent fall
back snapshots.
1 Drop the inconsistent snap
shot
Availability
SAP HANA Troubleshooting and Performance Analysis Guide
Alerts and the Statistics Service
P U B L I C 257

ID Name Description Cfg User Action Category
Further Infor
mation
108 Old fallback
snapshot
Checks for out of date fall
back snapshots (older than
the dened thresholds).
* Check the age and possibly
drop the snapshot
Availability
109 Backup history
broken
Checks if the backup history
is incomplete or inconsistent
(the log_mode is internally
set to overwrite, it is not en
sured that the service is fully
recoverable via backup).
Perform a data backup as
soon as possible to ensure
that the service is fully recov
erable.
Backup
110 Catalog Consis
tency
An alert is raised if the Cata
log Consistency Check de
tects errors (identies the
number of errors and af
fected objects).
*
Contact SAP support. Availability
111 Replication sta
tus of replication
log
Check whether the status of
replication log is disabled.
* Truncate replication log table
and enable replication log
Availability
112 Missing STO
NITH with
shared storage
Check whether a STONITH
provider is congured in a
scale-out system with shared
basepaths.
1
Implement a STONITH pro
vider.
? See Implement
ing a HA/DR
Provider in the
SAP HANA Sys
tem Administra
tion Guide
.
113
Open le count Determines what percentage
of total open le handles are
in use. All processes are con
sidered, including non-SAP
HANA processes.
*
You can congure the Linux
file-max parameter using
the following commands:
1. Check the current maxi
mum number of allowed le
handles: cat /proc/sys/fs/
le-max
2. Extend maximum number
of le handles in /etc/
sysctl.conf: fs.le-max =
20000000
3. Activate changes for oper
ating system: sysctl -p /etc/
sysctl.conf
Congura-
tion
114 Active async IO
count
Determines what percentage
of total asynchronous input/
output requests are in use.
All processes are considered,
including non-SAP HANA
processes.
*
You can increase the size of
the Linux I/O queue (
aio-
max-nr parameter) as de
scribed in SAP Note
1868829.
Congura-
tion
SAP Note:
1868829
258 P UB L IC
SAP HANA Troubleshooting and Performance Analysis Guide
Alerts and the Statistics Service

ID Name Description Cfg User Action Category
Further Infor
mation
115 Timezone envi
ronment varia
ble verication
Determines if the timezone
environment variable TZ can
be interpreted. See M_TIME
ZONE_ALERTS. Otherwise
HANA falls back to a system
call which can cause signi-
cant performance issues.
1
Please set the timezone envi
ronment variable TZ to a
valid value according to the
POSIX documentation and
restart the HANA database.
See also SAP Note 2100040.
Congura-
tion
SAP Note:
2100040
116 Transparent
huge pages sta
tus
Determines if Transparent
Huge Pages (THP) are acti
vated which can cause issues
for the database.
1
Deactivate THP by setting
the kernel parameter to
"[never]".
SAP Notes:
2031375
118 Port ephemeral
max count
Checks for free local ports by
referring to following kernel
parameters:
net.ipv4.ip_local_p
ort_range
and
net.ipv4.ip_local_r
eserved_ports. The alert
is raised if the number of free
local ports is below the con
gured minimum.
1
Increase the local port range
by setting prole parameters
as described in SAP Note
401162, or free ports which
do not have to be reserved.
The number of free local
ports and ports which should
be reserved for HANA serv
ices can be found in the sys
tem view M_HOST_INFOR
MATION, keys:
net_port_ephemeral_
max_count and
net_port_ranges.
Congura-
tion
SAP Note:
401162 . See
also SAP Host
Agent and Linux
kernel parame
ters in the SAP
HANA System
Administration
Guide
.
119
Required local
SAP HANA port
ranges
Checks for local ports which
are required but which have
not been reserved (see Alert
118). If not reserved there is a
risk that these ports could be
automatically assigned to
other applications.
The alert is raised if any ports
in the local ports range are
not reserved.
1
Reserve ports by setting pro
le parameters as described
in SAP Note 401162.
Details of unreserved ports
can be retrieved from the
system view M_HOST_IN
FORMATION key:
net_port_unreserved
_ranges.
Congura-
tion
SAP Note:
401162 See
also SAP Host
Agent and Linux
kernel parame
ters in the SAP
HANA System
Administration
Guide
.
128
LDAP Enabled
Users without
SSL
Checks for the vulnerability
where users may be enabled
for LDAP Authentication but
SSL is not enabled.
Congure SSL to reduce risk
of man-in-the-middle attacks
and privacy protection.
Security
129 Check trusted
certicate expi
ration date
Determines if there are any
trusted certicates that will
expire soon or have already
expired.
1
Replace the certicates that
are expiring or are already ex
pired with new ones.
Security
SAP HANA Troubleshooting and Performance Analysis Guide
Alerts and the Statistics Service
P U B L I C 259

ID Name Description Cfg User Action Category
Further Infor
mation
130 Check own cer
ticate expira
tion date
Determines if there are any
own or chained certicates
that will expire soon or have
already expired.
*
Replace the certicates that
are expiring or are already ex
pired with new ones.
Security
131 Session re
quests queued
by admission
control
Determines the number of
session requests waiting in
the admission control queue.
This can indicate an issue
with the response time of the
request.
1
Investigate why the session
requests newly queued by
admission control. Refer to
M_ADMISSION_CON
TROL_EVENTS for more in
formation.
Availability
132 Session re
quests rejected
by admission
control
Determines the number of
session requests newly re
jected by admission control.
This can indicate an issue
with the availability of the da
tabase.
1
Investigate why the session
requests newly rejected by
admission control. Refer to
M_ADMISSION_CON
TROL_EVENTS for more in
formation.
Availability
135 Checks congu-
ration for SAP
HANA SLD Data
Supplier
For system replication, virtual
and physical databases must
be congured to send the
correct landscape data to the
Landscape Management Da
tabase via the System Land
scape Directory (SLD).
Congure SAP HANA SLD
Data Supplier as docu
mented in SAP HANA System
Administration Guide (see
link in Further Information).
Congura-
tion
Conguring SAP
HANA for Sys
tem Replication
Technical Sce
nario in SAP Sol
ution Manager
136
Unsupported
Parameter Val
ues Set
Checks if conguration pa
rameters are set to an un
supported value.
Correct the values of congu-
ration parameters as neces
sary.
Congura-
tion
137 Restart Required
for Congura-
tion Change
Check if a restart is required
for a conguration change to
become eective.
If necessary, restart the sys
tem.
Congura-
tion
500 Dbspace usage Checks for the dbspace size
usage.
* Investigate the usage of
dbspace and increase the
size.
Disk
501 Dbspace status Determines whether or not
all dbspaces are available.
Investigate why the dbspace
is not available.
Availability
502 Dbspace le sta
tus
Determines whether or not
all dbspace les are available.
Investigate why the dbspace
le is not available.
Availability
600 Inactive Stream
ing applications
Identies inactive Streaming
applications.
Investigate why the Stream
ing application is inactive, for
example, by checking the
Streaming application's trace
les.
Availability
601 Inactive Stream
ing project man
aged adapters
Identies inactive Streaming
project managed adapters.
Investigate why the Stream
ing project managed adapter
is inactive, for example, by
checking the trace les.
Availability
260 P U B L I C
SAP HANA Troubleshooting and Performance Analysis Guide
Alerts and the Statistics Service

ID Name Description Cfg User Action Category
Further Infor
mation
602 Streaming
project physical
memory usage
Determines what percentage
of total physical memory
available on the host is used
for the streaming project.
*
Investigate memory usage of
the streaming project.
Memory
603 Streaming
project CPU us
age
Determines the percentage
CPU usage for a streaming
project on the host and
therefore whether or not CPU
resources are running out.
*
Investigate CPU usage. CPU
604 Number of pub
lishers of
streaming
project
Identify the large publishers
of streaming project. Make
sure that they will not break
the streaming project.
*
Investigate whether these
publishers are created inten
tionally.
Congura-
tion
605 Number of sub
scribers of
streaming
project
Identify the large subscribers
of streaming project. Make
sure that they will not break
the streaming project.
*
Investigate whether these
subscribers are created in
tentionally.
Congura-
tion
606 Row throughput
of subscriber of
streaming
project
Identify which subscriber of
streaming project has low
throughput measured in rows
per second.
1
Investigate why the sub
scriber works slowly.
Congura-
tion
607 Transaction
throughput of
subscriber of
streaming
project
Identify which subscriber of
streaming project has trans
action throughput measured
in transactions per second.
1
Investigate why the sub
scriber works slowly.
Congura-
tion
608 Row throughput
of publisher of
streaming
project
Identify which publisher of
streaming project has low
throughput measured in rows
per second.
1
Investigate why the publisher
works slowly.
Congura-
tion
609 Transaction
throughput of
publisher of
streaming
project
Identify which publisher of
streaming project has trans
action throughput measured
in transactions per second.
1
Investigate why the publisher
works slowly.
Congura-
tion
610 Bad rows of
project managed
adapter
Identify which project man
aged adapter has much rows
with error.
1 Investigate why the adapter
has such much rows with er
ror.
Congura-
tion
611 High latency of
project managed
adapter
Identify which project man
aged adapter has high la
tency.
1 Investigate why the adapter
has high latency.
Congura-
tion
612 Large queue of
stream of
streaming
project
Identify which stream of
streaming project has large
queue.
1 Investigate why the stream
has large queue.
Congura-
tion
SAP HANA Troubleshooting and Performance Analysis Guide
Alerts and the Statistics Service
P U B L I C 261

ID Name Description Cfg User Action Category
Further Infor
mation
613 Large store of
stream of
streaming
project
Identify which stream of
streaming project has large
store.
1 Investigate why the stream
has large store.
Congura-
tion
700 Agent availability Determines how many mi
nutes the agent has been in
active.
* Investigate connection of
agent and check if agent is
up and running.
Availability
701 Agent memory
usage
Determines what percentage
of total available memory on
agent is used.
* Investigate which adapter or
processes use a lot of mem
ory.
Memory
710 Remote Sub
scription excep
tion
Checks for recent exceptions
in remote subscriptions and
remote sources.
Investigate the error mes
sage and the error code and
restart the remote subscrip
tion if necessary.
0
6.2
Alerts Reference
Details of alerts in Version SPS 04.
ID: 0
Name: Internal statistics server problem
Description: Identies internal statistics server problem.
Category: Availability
User Action: Resolve the problem. For more information, see the trace les. You may need to activate
tracing rst.
Further information: SAP Note: 1803039
ID: 1
Name: Host physical memory usage
Description: Determines what percentage of total physical memory available on the host is used. All
processes consuming memory are considered, including non-SAP HANA processes.
Category: Memory
Unit: percent
262 P U B L I C
SAP HANA Troubleshooting and Performance Analysis Guide
Alerts and the Statistics Service

Default threshold(s) (Se
verity):
95; 98; 100 (2; 3; 4)
User Action: Investigate memory usage of processes.
Further information: SAP Note: 1898317; SAP Note: 1840954
ID: 2
Name: Disk usage
Description: Determines what percentage of each disk containing data, log, and trace les is used. This
includes space used by non-SAP HANA les.
Category: Disk
Unit: percent
Default threshold(s) (Se
verity):
90; 95; 98 (2; 3; 4)
User Action: Investigate disk usage of processes. Increase disk space, for example by shrinking volumes,
deleting diagnosis les, or adding additional storage.
Further information: SAP Note: 1900643
ID: 3
Name: Inactive services
Description: Identies inactive services.
Category: Availability
Unit: seconds
Default threshold(s) (Se
verity):
600 (4)
User Action: Investigate why the service is inactive, for example, by checking the service's trace les.
Further information: Inactive > 600 seconds. SAP Note: 1902033
ID: 4
Name: Restarted services
Description: Identies services that have restarted since the last time the check was performed.
Category: Availability
SAP HANA Troubleshooting and Performance Analysis Guide
Alerts and the Statistics Service
P U B L I C 263

User Action: Investigate why the service had to restart or be restarted, for example, by checking the serv
ice's trace les.
Further information: SAP Note: 1909660
ID: 5
Name: Host CPU Usage
Description: Determines the percentage CPU idle time on the host and therefore whether or not CPU re
sources are running low.
Category: CPU
Unit: percent
Default threshold(s) (Se
verity):
25; 15; 10 (2; 3; 4)
User Action: Investigate CPU usage.
Further information: SAP Note: 1909670
ID: 10
Name: Delta merge (mergedog) conguration
Description: Determines whether or not the 'active' parameter in the 'mergedog' section of system con
guration le(s) is 'yes'. mergedog is the system process that periodically checks column
tables to determine whether or not a delta merge operation needs to be executed.
Category: Conguration
User Action: Change in SYSTEM layer the parameter active in section(s) mergedog to yes
Further information: SAP Note: 1909641
ID: 12
Name: Memory usage of name server
Description: Determines what percentage of allocated shared memory is being used by the name server
on a host.
Category: Memory
Unit: percent
264 P UB L IC
SAP HANA Troubleshooting and Performance Analysis Guide
Alerts and the Statistics Service

Default threshold(s) (Se
verity):
70; 80 (3; 4)
User Action: Increase the shared memory size of the name server. In the 'topology' section of the name
server.ini le, increase the value of the 'size' parameter.
Further information: SAP Note: 1977101
ID: 16
Name: Lock wait timeout conguration
Description: Determines whether the 'lock_wait_timeout' parameter in the 'transaction' section of the in
dexserver.ini le is between 100,000 and 7,200,000.
Category: Conguration
User Action: In the 'transaction' section of the indexserver.ini le, set the 'lock_wait_timeout' parameter
to a value between 100,000 and 7,200,000 for the System layer.
Further information: SAP Note: 1909707
ID: 17
Name: Record count of non-partitioned column-store tables
Description: Determines the number of records in non-partitioned column-store tables. Current table
size is not critical. Partitioning need only be considered if tables are expected to grow rap
idly (a non-partitioned table cannot contain more than 2,147,483,648 (2 billion) rows).
Category: Memory
Unit: records
Default threshold(s) (Se
verity):
300000000 (1)
User Action: Consider partitioning the table only if you expect it to grow rapidly.
Further information: SAP HANA Administration Guide > Table Partitioning, SAP Note: 1909763
ID: 20
Name: Table growth of non-partitioned column-store tables
Description: Determines the growth rate of non-partitioned columns tables.
Category: Memory
SAP HANA Troubleshooting and Performance Analysis Guide
Alerts and the Statistics Service
P U B L I C 265

Unit: percent
Default threshold(s) (Se
verity):
5; 7,5; 10 (2; 3; 4)
User Action: Consider partitioning the table.
Further information: SAP HANA Administration Guide > Table Partitioning, SAP Note: 1910140
ID: 21
Name: Internal event
Description: Identies internal database events.
Category: Availability
Unit: state
Default threshold(s) (Se
verity):
HANDLED; INFO; NEW (2; 3; 4)
User Action: Resolve the event and then mark it as resolved by executing the SQL statement ALTER SYS
TEM SET EVENT HANDLED '<host>:<port>' <id>. Note that this is not necessary for INFO
events.
Further information: SAP Note: 1977252
ID: 22
Name: Notication of all alerts
Description: Determines whether or not there have been any alerts since the last check and if so, sends a
summary e-mail to specied recipients.
Category: Availability
User Action: Investigate the alerts.
ID: 23
Name: Notication of medium and high priority alerts
Description: Determines whether or not there have been any medium and high priority alerts since the
last check and if so, sends a summary e-mail to specied recipients.
Category: Availability
User Action: Investigate the alerts.
266 PU B L I C
SAP HANA Troubleshooting and Performance Analysis Guide
Alerts and the Statistics Service

ID: 24
Name: Notication of high priority alerts
Description: Determines whether or not there have been any high priority alerts since the last check and
if so, sends a summary e-mail to specied recipients.
Category: Availability
User Action: Investigate the alerts.
ID: 25
Name: Open connections
Description: Determines what percentage of the maximum number of permitted SQL connections are
open. The maximum number of permitted connections is congured in the "session" sec
tion of the indexserver.ini le.
Category: Sessions/Transactions
Unit: percent
Default threshold(s) (Se
verity):
90; 95; 98 (2; 3; 4)
User Action: Investigate why the maximum number of permitted open connections is being approached.
Further information: SAP Note: 1910159
ID: 26
Name: Unassigned volumes
Description: Identies volumes that are not assigned a service.
Category: Conguration
User Action: Investigate why the volume is not assigned a service. For example, the assigned service is
not active, the removal of a host failed, or the removal of a service was performed incor
rectly.
Further information: SAP Note: 1910169
ID: 27
Name: Record count of column-store table partitions
Description: Determines the number of records in the partitions of column-store tables. A table partition
cannot contain more than 2,000,000,000 (2 billion) rows.
SAP HANA Troubleshooting and Performance Analysis Guide
Alerts and the Statistics Service
P U B L I C 267

Category: Memory
Unit: records
Default threshold(s) (Se
verity):
1500000000; 1800000000; 1900000000 (2; 3; 4)
User Action: Consider repartitioning the table.
Further information: SAP HANA Administration Guide > Table Partitioning, SAP Note: 1910188
ID: 28
Name: Most recent savepoint operation
Description: Determines how long ago the last savepoint was dened, that is, how long ago a complete,
consistent image of the database was persisted to disk.
Category: Disk
Unit: minutes
Default threshold(s) (Se
verity):
60; 120; 300 (1; 2; 3)
User Action: Investigate why there was a delay dening the last savepoint and consider triggering the op
eration manually by executing the SQL statement ALTER SYSTEM SAVEPOINT.
Further information: SAP Note: 1977291
ID: 29
Name: Size of delta storage of column-store tables
Description: Determines the size of the delta storage of column tables.
Category: Memory
Unit: MB
Default threshold(s) (Se
verity):
2048; 5120; 10240 (1; 2; 3)
User Action: Investigate the delta merge history in the monitoring view M_DELTA_MERGE_STATISTICS.
Consider merging the table delta manually.
Further information: SAP Note: 1977314
ID: 30
268 P U B L I C
SAP HANA Troubleshooting and Performance Analysis Guide
Alerts and the Statistics Service

Name: Check internal disk full event
Description: Determines whether or not the disks to which data and log les are written are full. A disk-
full event causes your database to stop and must be resolved.
Category: Disk
Unit: state
Default threshold(s) (Se
verity):
HANDLED, NEW (2; 4)
User Action: Resolve the disk-full event as follows: In the Administration Editor on the Overview tab,
choose the "Disk Full Events" link and mark the event as handled. Alternatively, execute the
SQL statements ALTER SYSTEM SET EVENT ACKNOWLEDGED '<host>:<por
Further information: SAP Note: 1898460
ID: 31
Name: License expiry
Description: Determines how many days until your license expires. Once your license expires, you can no
longer use the system, except to install a new license.
Category: Availability
Unit: day
Default threshold(s) (Se
verity):
30; 14; 7 (2; 3; 4)
User Action: Obtain a valid license and install it. For the exact expiration date, see the monitoring view
M_LICENSE.
Further information: Security, Authorization and Licensing, SAP Note: 1899480
ID: 32
Name: Log mode LEGACY
Description: Determines whether or not the database is running in log mode "legacy". Log mode "legacy"
does not support point-in-recovery and is not recommended for productive systems.
Category: Backup
User Action: If you need point-in-time recovery, recongure the log mode of your system to "normal". In
the "persistence" section of the global.ini conguration le, set the parameter "log_mode"
to "normal" for the System layer. When you change the log mode, you m
SAP HANA Troubleshooting and Performance Analysis Guide
Alerts and the Statistics Service
P U B L I C 269

Further information: Conguration Parameter Issues. SAP Note: 1900296
ID: 33
Name: Log mode OVERWRITE
Description: Determines whether or not the database is running in log mode "overwrite". Log mode
"overwrite" does not support point-in-recovery (only recovery to a data backup) and is not
recommended for productive systems.
Category: Backup
User Action: If you need point-in-time recovery, recongure the log mode of your system to "normal". In
the "persistence" section of the global.ini conguration le, set the parameter "log_mode"
to "normal" for the System layer. When you change the log mode, you m
Further information: SAP HANA Administration Guide > Backing up and Recovering the SAP HANA Database.
SAP Note: 1900267
ID: 34
Name: Unavailable volumes
Description: Determines whether or not all volumes are available.
Category: Conguration
User Action: Investigate why the volume is not available.
Further information: SAP HANA Administration Guide > Backing up and Recovering the SAP HANA Database,
SAP Note: 1900682
ID: 35
Name: Existence of data backup
Description: Determines whether or not a data backup exists. Without a data backup, your database can
not be recovered.
Category: Backup
User Action: Perform a data backup as soon as possible.
Further information: SAP HANA Administration Guide > Backing up and Recovering the SAP HANA Database,
SAP Note: 1900728
ID: 36
270 P U B L I C
SAP HANA Troubleshooting and Performance Analysis Guide
Alerts and the Statistics Service

Name: Status of most recent data backup
Description: Determines whether or not the most recent data backup was successful.
Category: Backup
User Action: Investigate why the last data backup failed, resolve the problem, and perform a new data
backup as soon as possible.
Further information: SAP HANA Administration Guide > Backing up and Recovering the SAP HANA Database,
SAP Note: 1900795
ID: 37
Name: Age of most recent data backup
Description: Determines the age of the most recent successful data backup.
Category: Backup
Unit: day
Default threshold(s) (Se
verity):
5; 7 ; 20 (2; 3; 4)
User Action: Perform a data backup as soon as possible.
Further information: SAP HANA Administration Guide > Backing up and Recovering the SAP HANA Database,
SAP Note: 1900730
ID: 38
Name: Status of most recent log backups
Description: Determines whether or not the most recent log backups for services and volumes were suc
cessful.
Category: Backup
User Action: Investigate why the log backup failed and resolve the problem.
Further information: SAP HANA Administration Guide > Backing up and Recovering the SAP HANA Database,
SAP Note: 1900788
ID: 39
Name: Long-running statements
Description: Identies long-running SQL statements.
SAP HANA Troubleshooting and Performance Analysis Guide
Alerts and the Statistics Service
P U B L I C 271

Category: Sessions/Transactions
Unit: seconds
Default threshold(s) (Se
verity):
1800; 2700; 3600 (1; 2; 3)
User Action: Investigate the statement. For more information, see the table _SYS_STATIS
TICS.HOST_LONG_RUNNING_STATEMENTS.
Further information: SAP Note: 1977262
ID: 40
Name: Total memory usage of column-store tables
Description: Determines what percentage of the eective allocation limit is being consumed by individual
column-store tables as a whole (that is, the cumulative size of all of a table's columns and
internal structures)
Category: Memory
Unit: percent
Default threshold(s) (Se
verity):
20; 25; 30 (1; 2; 3)
User Action: Consider partitioning or repartitioning the table.
Further information: SAP Note: 1977268
ID: 41
Name: In-memory DataStore activation
Description: Determines whether or not there is a problem with the activation of an in-memory Data
Store object.
Category: Availability
User Action: For more information, see the table _SYS_STATISTICS.GLOBAL_DEC_EXTRACTOR_STATUS
and SAP Note 1665553.
Further information: SAP Note: 1665553, SAP Note: 1977230
ID: 42
Name: Long-idling cursors
272 P U B L I C
SAP HANA Troubleshooting and Performance Analysis Guide
Alerts and the Statistics Service

Description: Identies long-idling cursors.
Category: Sessions/Transactions
Unit: ratio
Default threshold(s) (Se
verity):
0.5; 0.7 ;0.9 (2; 3; 4)
User Action: Close the cursor in the application, or kill the connection by executing the SQL statement
ALTER SYSTEM DISCONNECT SESSION <LOGICAL_CONNECTION_ID>. For more informa
tion, see the table HOST_LONG_IDLE_CURSOR (_SYS_STATISTICS).
Further information: SAP Note: 1900261
ID: 43
Name: Memory usage of services
Description: Determines what percentage of its eective allocation limit a service is using.
Category: Memory
Unit: percent
Default threshold(s) (Se
verity):
80; 90; 95 (2; 3; 4)
User Action: Check for services that consume a lot of memory.
Further information: SAP Note: 1900257
ID: 44
Name: Licensed memory usage
Description: Determines what percentage of licensed memory is used.
Category: Memory
Unit: percent
Default threshold(s) (Se
verity):
98 (1)
User Action: Increase licensed amount of main memory. You can see the peak memory allocation since
installation in the system view M_LICENSE (column PRODUCT_USAGE).
Further information: SAP Note: 1899511
SAP HANA Troubleshooting and Performance Analysis Guide
Alerts and the Statistics Service
P U B L I C 273

ID: 45
Name: Memory usage of main storage of column-store tables
Description: Determines what percentage of the eective allocation limit is being consumed by the main
storage of individual column-store tables.
Category: Memory
Unit: percent
Default threshold(s) (Se
verity):
20; 25; 30 (1; 2; 3)
User Action: Consider partitioning or repartitioning the table.
Further information: SAP Note: 1977269
ID: 46
Name: RTEdump les
Description: Identies new runtime dump les (*rtedump*) have been generated in the trace directory of
the system. These contain information about, for example, build, loaded modules, running
threads, CPU, and so on.
Category: Diagnosis Files
User Action: Check the contents of the dump les.
Further information: SAP Note: 1977099
ID: 47
Name: Long-running serializable transactions
Description: Identies long-running serializable transactions.
Category: Sessions/Transactions
Unit: ratio
Default threshold(s) (Se
verity):
0.7; 0.9 (3; 4)
User Action: Close the serializable transaction in the application or kill the connection by executing the
SQL statement ALTER SYSTEM DISCONNECT SESSION <LOGICAL_CONNECTION_ID>. For
more information, see the table HOST_LONG_SERIALIZABLE_TRANSACTION (_SYS_STA
TIST
Further information: Transactional Problems
274 P U B L I C
SAP HANA Troubleshooting and Performance Analysis Guide
Alerts and the Statistics Service

ID: 48
Name: Long-running uncommitted write transactions
Description: Identies long-running uncommitted write transactions.
Category: Sessions/Transactions
Unit: ratio
Default threshold(s) (Se
verity):
0.7; 0.9 (3; 4)
User Action: Close the uncommitted transaction in the application or kill the connection by executing the
SQL statement ALTER SYSTEM DISCONNECT SESSION <LOGICAL_CONNECTION_ID>. For
more information, see the table HOST_UNCOMMITTED_WRITE_TRANSACTION
(_SYS_STATISTI
Further information: SAP Note: 1977276
ID: 49
Name: Long-running blocking situations
Description: Identies long-running blocking situations.
Category: Sessions/Transactions
Unit: minutes
Default threshold(s) (Se
verity):
15; 20; 25 (2; 3; 4)
User Action: Investigate the blocking and blocked transactions and if appropriate cancel one of them.
Further information: SAP Note: 2079396
ID: 50
Name: Number of diagnosis les
Description: Determines the number of diagnosis les written by the system (excluding zip-les). An un
usually large number of les can indicate a problem with the database (for example, prob
lem with trace le rotation or a high number of crashes).
Category: Diagnosis Files
Unit: les
Default threshold(s) (Se
verity):
200 (2)
SAP HANA Troubleshooting and Performance Analysis Guide
Alerts and the Statistics Service
P U B L I C 275

User Action: Investigate the diagnosis les.
Further information: See KBA 1977162, SAP Note: 1977162
ID: 51
Name: Size of diagnosis les
Description: Identies large diagnosis les. Unusually large les can indicate a problem with the data
base.
Category: Diagnosis Files
Unit: MB
Default threshold(s) (Se
verity):
1024; 2048 (2; 3)
User Action: Check the diagnosis les in the SAP HANA studio for details.
Further information: See KBA 1977208, SAP Note: 1977208
ID: 52
Name: Crashdump les
Description: Identies new crashdump les that have been generated in the trace directory of the sys
tem.
Category: Diagnosis Files
User Action: Check the contents of the dump les.
Further information: SAP Note: 1977218
ID: 53
Name: Pagedump les
Description: Identies new pagedump les that have been generated in the trace directory of the system.
Category: Diagnosis Files
User Action: Check the contents of the dump les.
Further information: SAP Note: 1977242
ID: 54
276 P U B L I C
SAP HANA Troubleshooting and Performance Analysis Guide
Alerts and the Statistics Service

Name: Savepoint duration
Description: Identies long-running savepoint operations.
Category: Backup
Unit: seconds
Default threshold(s) (Se
verity):
300; 600; 900 (1; 2; 3)
User Action: Check disk I/O performance.
Further information: CPU Related Root Causes and Solutions, I/O Related Root Causes and Solutions, SAP Note:
1977220
ID: 55
Name: Columnstore unloads
Description: Determines how many columns in columnstore tables have been unloaded from memory.
This can indicate performance issues.
Category: Memory
Unit: tables
Default threshold(s) (Se
verity):
1000; 10000; 100000 (1; 2; 3)
User Action: Check sizing with respect to data distribution.
Further information: SAP Note: 1977207
ID: 56
Name: Python trace activity
Description: Determines whether or not the python trace is active and for how long. The python trace
aects system performance.
Category: Diagnosis Files
Unit: minutes
Default threshold(s) (Se
verity):
20; 60; 300 (1; 2; 3)
User Action: If no longer required, deactivate the python trace in the relevant conguration le.
Further information: SAP Note: 1977098
SAP HANA Troubleshooting and Performance Analysis Guide
Alerts and the Statistics Service
P U B L I C 277

ID: 57
Name: Instance secure store le system (SSFS) inaccessible
Description: Determines if the instance secure store in the le system (SSFS) of your SAP HANA system
is accessible to the database.
Category: Security
Unit: state
Default threshold(s) (Se
verity):
1 (4)
User Action: Check and make sure that the instance SSFS is accessible to the database.
Further information: SAP Note: 1977221
ID: 58
Name: Plan cache size
Description: Determines whether or not the plan cache is too small.
Category: Memory
Unit: evictions
Default threshold(s) (Se
verity):
1000 (1)
User Action: Currently Alert 58 is inactive and replaced by Alert 91. Please activate Alert 91 - Plan Cache
Hit Ratio
Further information: SAP Note: 1977253
ID: 59
Name: Percentage of transactions blocked
Description: Determines the percentage of transactions that are blocked.
Category: Sessions/Transactions
Unit: percent
Default threshold(s) (Se
verity):
5; 10; 20 (2; 3; 4)
User Action: Investigate blocking and blocked transactions and if appropriate cancel some of them.
278 P U B L I C
SAP HANA Troubleshooting and Performance Analysis Guide
Alerts and the Statistics Service

Further information: SAP Note: 2081856
ID: 60
Name: Sync/Async read ratio
Description: Identies a bad trigger asynchronous read ratio. This means that asynchronous reads are
blocking and behave almost like synchronous reads. This might have negative impact on
SAP HANA I/O performance in certain scenarios.
Category: Disk
Unit: ratio
Default threshold(s) (Se
verity):
0.5 (1)
User Action: Please refer to SAP note 1930979.
Further information: I/O Related Root Causes and Solutions, SAP Note: 1965379
ID: 61
Name: Sync/Async write ratio
Description: Identies a bad trigger asynchronous write ratio. This means that asynchronous writes are
blocking and behave almost like synchronous writes. This might have negative impact on
SAP HANA I/O performance in certain scenarios.
Category: Disk
Unit: ratio
Default threshold(s) (Se
verity):
0.5 (1)
User Action: Please refer to SAP note 1930979.
Further information: I/O Related Root Causes and Solutions, SAP Note: 1965379
ID: 62
Name: Expiration of database user passwords
Description: Identies database users whose password is due to expire in line with the congured pass
word policy. If the password expires, the user will be locked. If the user in question is a tech
nical user, this may impact application availability. It is recommended that you disable the
password lifetime check of technical users so that their password never expires (ALTER
USER <username> DISABLE PASSWORD LIFETIME).
SAP HANA Troubleshooting and Performance Analysis Guide
Alerts and the Statistics Service
P U B L I C 279

Category: Security
User Action: Change the password of the database user.
Further information: SAP Note: 2082406
ID: 63
Name: Granting of SAP_INTERNAL_HANA_SUPPORT role
Description: Determines if the internal support role (SAP_INTERNAL_HANA_SUPPORT) is currently
granted to any database users.
Category: Security
Unit: users
Default threshold(s) (Se
verity):
1 (2)
User Action: Check if the corresponding users still need the role. If not, revoke the role from them.
Further information: SAP Note: 2081857
ID: 64
Name: Total memory usage of table-based audit log
Description: Determines what percentage of the eective memory allocation limit is being consumed by
the database table used for table-based audit logging. If this table grows too large, the avail
ability of the database could be impacted.
Category: Memory
Unit: percent
Default threshold(s) (Se
verity):
5; 7; 9; 11 (1; 2; 3; 4)
User Action: Consider exporting the content of the table and then truncating the table.
Further information: SAP Note: 2081869
ID: 65
Name: Runtime of the log backups currently running
Description: Determines whether or not the most recent log backup terminates in the given time.
Category: Backup
280 P U B L I C
SAP HANA Troubleshooting and Performance Analysis Guide
Alerts and the Statistics Service

Unit: seconds
Default threshold(s) (Se
verity):
30; 300; 900 (2; 3; 4)
User Action: Investigate why the log backup runs for too long, and resolve the issue.
Further information: SAP HANA Administration Guide, SAP Note: 2081845
ID: 66
Name: Storage snapshot is prepared
Description: Determines whether or not the period, during which the database is prepared for a storage
snapshot, exceeds a given threshold.
Category: Backup
Unit: seconds
Default threshold(s) (Se
verity):
300; 900; 3600 (2; 3; 4)
User Action: Investigate why the storage snapshot was not conrmed or abandoned, and resolve the is
sue.
Further information: SAP HANA Administration Guide, SAP Note: 2081405
ID: 67
Name: Table growth of rowstore tables
Description: Determines the growth rate of rowstore tables
Category: Memory
Unit: percent
Default threshold(s) (Se
verity):
5; 7.5; 10 (2; 3; 4)
User Action: Try to reduce the size of row store table by removing unused data
Further information: SAP Note: 2054411
ID: 68
Name: Total memory usage of row store
Description: Determines the current memory size of a row store used by a service
SAP HANA Troubleshooting and Performance Analysis Guide
Alerts and the Statistics Service
P U B L I C 281

Category: Memory
Unit: percent
Default threshold(s) (Se
verity):
70; 80; 90 (2; 3; 4)
User Action: Investigate memory usage by row store tables and consider cleanup of unused data
Further information: SAP Note: 2050579
ID: 69
Name: Enablement of automatic log backup
Description: Determines whether automatic log backup is enabled.
Category: Backup
User Action: Enable automatic log backup. For more details please see SAP HANA Administration Guide.
Further information: SAP HANA Administration Guide, SAP Note: 2081360
ID: 70
Name: Consistency of internal system components after system upgrade
Description: Veries the consistency of schemas and tables in internal system components (for example,
the repository) after a system upgrade.
Category: Availability
User Action: Contact SAP support.
ID: 71
Name: Row store fragmentation
Description: Check for fragmentation of row store.
Category: Memory
User Action: Implement SAP Note 1813245.
Further information: SAP Note: 1813245
ID: 72
Name: Number of log segments
282 P U B L I C
SAP HANA Troubleshooting and Performance Analysis Guide
Alerts and the Statistics Service

Description: Determines the number of log segments in the log volume of each serviceCheck for number
of log segments.
Category: Backup
Unit: log segments
Default threshold(s) (Se
verity):
5000; 7000; 9000 (2; 3; 4)
User Action: Make sure that log backups are being automatically created and that there is enough space
available for them. Check whether the system has been frequently and unusually restarting
services. If it has, then resolve the root cause of this issue and create l
ID: 73
Name: Overow of rowstore version space
Description: Determines the overow ratio of the rowstore version space.
Category: Memory
Unit: ratio
Default threshold(s) (Se
verity):
10; 50; 100 (2; 3; 4)
User Action: Identify the connection or transaction that is blocking version garbage collection. You can
do this in the SAP HANA studio by executing "MVCC Blocker Statement" and "MVCC
Blocker Transaction" available on the System Information tab of the Administration e
Further information: Transactional Problems
ID: 74
Name: Overow of metadata version space
Description: Determines the overow ratio of the metadata version space.
Category: Memory
Unit: ratio
Default threshold(s) (Se
verity):
10; 50; 100 (2; 3; 4)
User Action: Identify the connection or transaction that is blocking version garbage collection. You can
do this in the SAP HANA studio by executing "MVCC Blocker Statement" and "MVCC
Blocker Transaction" available on the System Information tab of the Administration e
SAP HANA Troubleshooting and Performance Analysis Guide
Alerts and the Statistics Service
P U B L I C 283

Further information: Transactional Problems
ID: 75
Name: Rowstore version space skew
Description: Determines whether the rowstore version chain is too long.
Category: Memory
Unit: versions
Default threshold(s) (Se
verity):
10000; 100000; 1000000 (2; 3; 4)
User Action: Identify the connection or transaction that is blocking version garbage collection. You can
do this in the SAP HANA studio by executing "MVCC Blocker Statement" and "MVCC
Blocker Transaction" available on the System Information tab of the Administration e
Further information: Transactional Problems
ID: 76
Name: Discrepancy between host server times
Description: Identies discrepancies between the server times of hosts in a scale-out system.
Category: Conguration
Unit: minutes
Default threshold(s) (Se
verity):
1; 2; 3 (2; 3; 4)
User Action: Check operating system time settings.
ID: 77
Name: Database disk usage
Description: Determines the total used disk space of the database. All data, logs, traces and backups are
considered.
Category: Disk
Unit: GB
Default threshold(s) (Se
verity):
300; 400; 500 (2; 3; 4)
284 P U B L I C
SAP HANA Troubleshooting and Performance Analysis Guide
Alerts and the Statistics Service

User Action: Investigate the disk usage of the database. See system view M_DISK_USAGE for more de
tails.
ID: 78
Name: Connection between systems in system replication setup
Description: Identies closed connections between the primary system and a secondary system. If con
nections are closed, the primary system is no longer being replicated.
Category: Availability
User Action: Investigate why connections are closed (for example, network problem) and resolve the is
sue.
Further information: SAP HANA Administration Guide
ID: 79
Name: Conguration consistency of systems in system replication setup
Description: Identies conguration parameters that do not have the same value on the primary system
and a secondary system. Most conguration parameters should have the same value on
both systems because the secondary system has to take over in the event of a disaster.
Category: Conguration
User Action: If the identied conguration parameter(s) should have the same value in both systems, ad
just the conguration. If dierent values are acceptable, add the parameter(s) as an excep
tion in global.ini/[inile_checker].
Further information: SAP HANA Administration Guide
ID: 80
Name: Availability of table replication
Description: Monitors error messages related to table replication.
Category: Availability
Unit: number of deactivated tables
Default threshold(s) (Se
verity):
1 (4)
User Action: Determine which tables encountered the table replication error using system view M_TA
BLE_REPLICAS, and then check the corresponding indexserver alert traces.
SAP HANA Troubleshooting and Performance Analysis Guide
Alerts and the Statistics Service
P U B L I C 285

ID: 81
Name: Cached view size
Description: Determines how much memory is occupied by cached view
Category: Memory
Unit: percent
Default threshold(s) (Se
verity):
50; 75; 90 (1; 2; 3)
User Action: Increase the size of the cached view. In the "result_cache" section of the indexserver.ini le,
increase the value of the "total_size" parameter.
ID: 82
Name: Timezone conversion
Description: Compares SAP HANA internal timezone conversion with Operating System timezone con
version.
Category: Conguration
Unit: days
Default threshold(s) (Se
verity):
999999999; 100; 10 (2; 3; 4)
User Action: Update SAP HANA internal timezone tables (refer to SAP note 1932132).
Further information: SAP Note: 1932132
ID: 83
Name: Table consistency
Description: Identies the number of errors and aected tables detected by _SYS_STATISTICS.Collec
tor_Global_Table_Consistency.
Category: Availability
Unit: errors
Default threshold(s) (Se
verity):
0; 1 (1; 3)
User Action: Contact SAP support.
Further information: FAQ
286 P U B L I C
SAP HANA Troubleshooting and Performance Analysis Guide
Alerts and the Statistics Service

ID: 84
Name: Insecure instance SSFS encryption conguration
Description: Determines whether the master key of the instance secure store in the le system (SSFS) of
your SAP HANA system has been changed. If the SSFS master key is not changed after in
stallation, it cannot be guaranteed that the initial key is unique.
Category: Security
User Action: Change the instance SSFS master key as soon as possible. For more information, see the
SAP HANA Administration Guide.
Further information: SAP HANA Administration Guide
ID: 85
Name: Insecure systemPKI SSFS encryption conguration
Description: Determines whether the master key of the secure store in the le system (SSFS) of your
system's internal public key infrastructure (system PKI) has been changed. If the SSFS
master key is not changed after installation, it cannot be guaranteed that the initial key is
unique.
Category: Security
User Action: Change the system PKI SSFS master key as soon as possible. For more information, see the
SAP HANA Administration Guide.
Further information: SAP HANA Administration Guide
ID: 86
Name: Internal communication is congured too openly
Description: Determines whether the ports used by SAP HANA for internal communication are securely
congured. If the "listeninterface" property in the "communication" section of the global.ini
le does not have the value ".local" for single-host systems and ".all" or ".global" for multi
ple-host systems, internal communication channels are externally exploitable.
Category: Security
User Action: The parameter [communication] listeninterface in global.ini is not set to a secure value.
Please refer to SAP Note 2183363 or the section on internal host name resolution in the SAP
HANA Administration Guide.
Further information: SAP Note: 2183363
ID: 87
SAP HANA Troubleshooting and Performance Analysis Guide
Alerts and the Statistics Service
P U B L I C 287

Name: Granting of SAP HANA DI support privileges
Description: Determines if support privileges for the SAP HANA Deployment Infrastructure (DI) are cur
rently granted to any database users or roles.
Category: Security
Unit: users
Default threshold(s) (Se
verity):
1 (2)
User Action: Check if the corresponding users still need the privileges. If not, revoke the privileges from
them.
ID: 88
Name: Auto merge for column-store tables
Description: Determines if the delta merge of a table was executed successfully or not.
Category: Memory
Unit: records
Default threshold(s) (Se
verity):
1; 5; 10 (2; 3; 4)
User Action: The delta merge was not executed successfully for a table. Check the error description in
view M_DELTA_MERGE_STATISTICS and also Indexserver trace.
ID: 89
Name: Missing volume les
Description: Determines if there is any volume le missing.
Category: Conguration
User Action: Volume le missing, database instance is broken, stop immediately all operations on this in
stance.
ID: 90
Name: Status of HANA platform lifecycle management conguration
Description: Determines if the system was not installed/updated with the SAP HANA Database Lifecycle
Manager (HDBLCM).
288 P U BL I C
SAP HANA Troubleshooting and Performance Analysis Guide
Alerts and the Statistics Service

Category: Conguration
User Action: Install/update SAP HANA Database Lifecycle Manager (HDBLCM). Implement SAP note
2078425
Further information: SAP Note: 2078425
ID: 91
Name: Plan cache hit ratio
Description: Determines whether or not the plan cache hit ratio is too low.
Category: Memory
Unit: ratio
Default threshold(s) (Se
verity):
0.95; 0.90 (1;2)
User Action: Increase the size of the plan cache. In the "sql" section of the indexserver.ini le, increase
the value of the "plan_cache_size" parameter.
ID: 92
Name: Root keys of persistent services are not properly synchronized
Description: Not al services that persist data could be reached the last time the root key change of the
data volume encryption service was changed. As a result, at least one service is running
with an old root key.
Category: Security
User Action: Trigger a savepoint for this service or ush the SSFS cache using hdbcons
ID: 93
Name: Streaming License expiry
Description: Determines how many days until your streaming license expires. Once your license expires,
you can no longer start streaming projects.
Category: Availability
Unit: day
Default threshold(s) (Se
verity):
30; 14 ; 7 (2; 3; 4)
SAP HANA Troubleshooting and Performance Analysis Guide
Alerts and the Statistics Service
P U B L I C 289

User Action: Obtain a valid license and install it. For the exact expiration date, see the monitoring view
M_LICENSES.
ID: 94
Name: Log replay backlog for system replication secondary
Description: System Replication secondary site has a higher log replay backlog than expected.
Category: Availability
Unit: MB
Default threshold(s) (Se
verity):
10240; 51200; 512000 (2; 3; 4)
User Action: Investigate on secondary site, why log replay backlog is increased
ID: 95
Name: Availability of Data Quality reference data (directory les)
Description: Determine the Data Quality reference data expiration dates.
Category: Availability
Unit: day
Default threshold(s) (Se
verity):
30; 7 ; 1 (2; 3; 4)
User Action: Download the latest Data Quality reference data les and update the system. (For more de
tails about updating the directories, see the Administration Guide.)
Further information: SAP HANA Administration Guide
ID: 96
Name: Long-running tasks
Description: Identies all long-running tasks.
Category:
Unit: seconds
Default threshold(s) (Se
verity):
3600; 21600; 43200 (2; 3; 4)
290 P U B L I C
SAP HANA Troubleshooting and Performance Analysis Guide
Alerts and the Statistics Service

User Action: Investigate the long-running tasks. For more information, see the task statistics tables or
views in _SYS_TASK schema and trace log.
ID: 97
Name: Granting of SAP HANA DI container import privileges
Description: Determines if the container import feature of the SAP HANA Deployment Infrastructure (DI)
is enabled and if import privileges for SAP HANA DI containers are currently granted to any
database users or roles.
Category: Security
Unit: users
User Action: Check if the identied users still need the privileges. If not, revoke the privileges from them
and disable the SAP HANA DI container import feature.
ID: 98
Name: LOB garbage collection activity
Description: Determines whether or not the lob garbage collection is activated.
Category: Conguration
User Action: Activate the LOB garbage collection using the corresponding conguration parameters.
ID: 99
Name: Maintenance Status
Description: Checks the installed SP version against the recommended SP version.
Category: Conguration
Unit: support package
User Action: Please consider upgrading to the recommended SP version.
ID: 100
Name: Unsupported operating system in use
Description: Determines if the operating system of the SAP HANA Database hosts is supported.
Category: Conguration
SAP HANA Troubleshooting and Performance Analysis Guide
Alerts and the Statistics Service
P U B L I C 291

User Action: Upgrade the operating system to a supported version (see SAP HANA Master Guide for
more information).
ID: 101
Name: SQL access for SAP HANA DI technical users
Description: Determines if SQL access has been enabled for any SAP HANA DI technical users. SAP
HANA DI technical users are either users whose names start with '_SYS_DI' or SAP HANA DI
container technical users (<container name>, <container name>#DI, <container
name>#OO).
Category: Security
Unit: users
User Action: Check if the identied users ('_SYS_DI*' users or SAP HANA DI container technical users)
still need SQL access. If not, disable SQL access for these users and deactivate the users.
ID: 102
Name: Existence of system database backup
Description: Determines whether or not a system database backup exists. Without a system database
backup, your system cannot be recovered.
Category: Backup
User Action: Perform a backup of the system database as soon as possible.
ID: 103
Name: Usage of deprecated features
Description: Determines if any deprecated features were used in the last interval.
Category:
Unit: calls
User Action: Check the view M_FEATURE_USAGE to see which features were used. Refer to SAP Note
2425002 for further information.
ID: 104
Name: HA New in SPS02
Description:
292 P U B L I C
SAP HANA Troubleshooting and Performance Analysis Guide
Alerts and the Statistics Service

Category:
User Action:
ID: 105
Name: Statistics New in SPS03 Takt 1
Description: if the number of open transactions is approaching the maximum number of permitted open
transactions
Category:
User Action:
ID: 500
Name: Dbspace usage
Description: Checks for the dbspace size usage.
Category: Disk
Unit: percent
Default threshold(s) (Se
verity):
90; 95; 98 (2; 3; 4)
User Action: Investigate the usage of dbspace and increase the size.
ID: 501
Name: Dbspace status
Description: Determines whether or not all dbspaces are available.
Category: Availability
User Action: Investigate why the dbspace is not available.
ID: 502
Name: Dbspace le status
Description: Determines whether or not all dbspace les are available.
Category: Availability
User Action: Investigate why the dbspace le is not available.
SAP HANA Troubleshooting and Performance Analysis Guide
Alerts and the Statistics Service
P U B L I C 293

ID: 503
Name: xxxInconsistent Persistence Encryptionxxx
Description: Conguration between HANA and HANA Extended Storage do not match. Data may not be
completely protected.
Category: Security
User Action: Investigate the alert and congure the persistence Encryption as required.
294 P UB L IC
SAP HANA Troubleshooting and Performance Analysis Guide
Alerts and the Statistics Service
7 Important Disclaimer for Features in SAP
HANA
For information about the capabilities available for your license and installation scenario, refer to the Feature
Scope Description for SAP HANA.
SAP HANA Troubleshooting and Performance Analysis Guide
Important Disclaimer for Features in SAP HANA
P U B L I C 295

Important Disclaimers and Legal Information
Hyperlinks
Some links are classied by an icon and/or a mouseover text. These links provide additional information.
About the icons:
● Links with the icon : You are entering a Web site that is not hosted by SAP. By using such links, you agree (unless expressly stated otherwise in your
agreements with SAP) to this:
● The content of the linked-to site is not SAP documentation. You may not infer any product claims against SAP based on this information.
● SAP does not agree or disagree with the content on the linked-to site, nor does SAP warrant the availability and correctness. SAP shall not be liable for any
damages caused by the use of such content unless damages have been caused by SAP's gross negligence or willful misconduct.
● Links with the icon : You are leaving the documentation for that particular SAP product or service and are entering a SAP-hosted Web site. By using such
links, you agree that (unless expressly stated otherwise in your agreements with SAP) you may not infer any product claims against SAP based on this
information.
Beta and Other Experimental Features
Experimental features are not part of the ocially delivered scope that SAP guarantees for future releases. This means that experimental features may be changed by
SAP at any time for any reason without notice. Experimental features are not for productive use. You may not demonstrate, test, examine, evaluate or otherwise use
the experimental features in a live operating environment or with data that has not been suciently backed up.
The purpose of experimental features is to get feedback early on, allowing customers and partners to inuence the future product accordingly. By providing your
feedback (e.g. in the SAP Community), you accept that intellectual property rights of the contributions or derivative works shall remain the exclusive property of SAP.
Example Code
Any software coding and/or code snippets are examples. They are not for productive use. The example code is only intended to better explain and visualize the syntax
and phrasing rules. SAP does not warrant the correctness and completeness of the example code. SAP shall not be liable for errors or damages caused by the use of
example code unless damages have been caused by SAP's gross negligence or willful misconduct.
Gender-Related Language
We try not to use gender-specic word forms and formulations. As appropriate for context and readability, SAP may use masculine word forms to refer to all genders.
296
P U B L I C
SAP HANA Troubleshooting and Performance Analysis Guide
Important Disclaimers and Legal Information
SAP HANA Troubleshooting and Performance Analysis Guide
Important Disclaimers and Legal Information
P U B L I C 297

www.sap.com/contactsap
© 2019 SAP SE or an SAP aliate company. All rights reserved.
No part of this publication may be reproduced or transmitted in any form
or for any purpose without the express permission of SAP SE or an SAP
aliate company. The information contained herein may be changed
without prior notice.
Some software products marketed by SAP SE and its distributors
contain proprietary software components of other software vendors.
National product specications may vary.
These materials are provided by SAP SE or an SAP aliate company for
informational purposes only, without representation or warranty of any
kind, and SAP or its aliated companies shall not be liable for errors or
omissions with respect to the materials. The only warranties for SAP or
SAP aliate company products and services are those that are set forth
in the express warranty statements accompanying such products and
services, if any. Nothing herein should be construed as constituting an
additional warranty.
SAP and other SAP products and services mentioned herein as well as
their respective logos are trademarks or registered trademarks of SAP
SE (or an SAP aliate company) in Germany and other countries. All
other product and service names mentioned are the trademarks of their
respective companies.
Please see https://www.sap.com/about/legal/trademark.html for
additional trademark information and notices.
THE BEST RUN
