
How Useful are Your Comments?
Analyz i ng and P redi ct i ng YouTube Comment s
and Comment Ratings
Stefan Siersdorfer, Sergiu Chelaru,
Wolfgang Nejdl
L3S Research Center
Appelstr. 9a
30167 Hannover, Germany
{siersdorfer, chelaru, nejdl}@L3S.de
Jose San Pedro
Telefonica Research
Via Augusta, 171
Barcelona 08021, Spain
jsanpedr[email protected]
ABSTRACT
An analysis of the social video sharing platform YouTube
reveals a high amount of community feedback through com-
ments for published videos as well as through meta ratings
for these comments. In this paper, we present an in -depth
study of commenting and comment rating behavior on a
sample of more than 6 million comments on 67,000 YouTube
videos for which we analyzed dependencies between com-
ments, views, comment ratings and topic categories. In
addition, we studied the influence of sentiment expressed
in comments on the ratings for these comments using the
SentiWordNet thesaurus, a lexical WordNet-based resource
containing sentiment annotations. Finally, to predict com-
munity acceptance for comments not yet rated, we built dif-
ferent classifiers for the estimation of ratings for these com-
ments. The results of our large-scale evaluations are promis-
ing and indicate that community feedback on already rated
comment s can help to filter new unrated comments or sug-
gest particularly useful but still unrated comments.
Categories and Subject Descriptors
H.4 [Information Systems Applications]: Miscellaneous
General Terms
Algorithms, Experimentation, Measurement
Keywo rds
comment ratings, community feedback, youtube
1. INTRODUCTION
The rapidly increasing popularity and data volume of mod-
ern Web 2.0 content sharing applications is based on th eir
ease of operation even for unexperienced users, suitable mech-
anisms for supporting collaboration, and attractiveness of
shared annotated material (images in Flickr, bookmarks in
del.icio.us, etc.). For video sharing, the most popular site is
YouTube
1
. Recent studies have shown that traffic to/from
1
http://www.youtube.com
Copyright is held by the International World Wide Web Conference Com-
mittee (IW3C2). Distribution of these papers is limited to classroom use,
and personal use by others.
WWW 2010, April 26–30, 2010, Raleigh, North Carolina, USA.
ACM 978-1-60558-799-8/10/04.
Figure 1: Comments and Comment Ratings in
YouTube
this site accounts for over 20% of the web total and 10%
of th e whole internet [3], and comprises 60% of the videos
watched on-line [11].
YouTube provides several social tools for community in-
teraction, including t he possibility to comment published
videos and, in addition, to provide ratings about these com-
ments by other users (see Figure 1). These meta ratings
serve the purpose of helping the community to filter rele-
vant opinions more efficiently. Furthermore, because neg-
ative votes are also available, comments with offensive or
inappropriate content can be easily skipped.
The analysis of comments and associated ratings consti-
tutes a potentially interesting data source to mine for obtain-
ing implicit kn owledge about users, videos, categories and
commu nity interests. In this p aper, we conduct a study of
this information with several complementary goals. On the
one hand, we study the viability of using comments and com-
munity feedback to train classification models for deciding
on the likely community acceptance of new comments. Such
models have direct application to the enh ancement of com-
ment browsing, by promoting interesting comments even in
the absence of community feedback. On t he other hand, we
perform an in-depth analysis of the distribution of comment
ratings, including qualitative and quantitative studies about
WWW 2010 • Full Paper
April 26-30 • Raleigh • NC • USA
891
sentiment values of terms and differences across categories.
Can we predict the community feedback for comments? Is
there a conn ection between sentiment and comment ratings?
Can comment ratings be an ind icator for polarizing content?
Do comment ratings and sentiment depend on the topic of
the discussed content ? These are some of the questions we
investigate in this paper by analyzing a large sample of com-
ments from YouTube.
Clearly, due to the continu in g and increasing stream of
comment s in social sharing environments such as YouTube,
the community is able to read and rate just a fraction of
these. The methods we present in this paper can help to
automatically structure and filter comments. Analyzing the
ratings of comments for videos can provide indicators for
highly polarizing content; users of the system could be pro-
vided with different views on that content using comment
clustering and aggregation techniques. Furthermore, auto-
matically generated content ratings might help to identify
users showing malicious beh avior such as sp ammers and
trolls at an early stage, and, in the future, might lead to
methods for recommending to an ind ividual user of the sys-
tem other users with similar interests and points of views.
The rest of th is paper is organized as follows: In Sec-
tion 2 we discuss related work on user generated content,
product reviews and comment analysis. Section 3 describes
our data gathering process, as well as the characteristics of
our dataset. In Section 4 we analyze the connection be-
tween sentiment in comments and community ratings us-
ing the SentiWordNet thesaurus. We then provide a short
overview of classification techniques in Section 5, explain
how we can apply these techniques to rate comments, and
provide the results of large-scale classification experiments
on our YouTube data set. In S ection 6 we analyze the corre-
spondence between comment ratings and polarizing content
through user ex periments. Section 7 describes dependencies
of ratings and sentiments on topic categories. We conclude
and sh ow directions for future work in Section 8.
2. RELATED WORK
There is a body of work on analyzing product reviews and
postings in forums. In [4] the dependency of helpfulness of
product reviews from Amazon users on the overall star rat-
ing of the product is examined and a possible explanation
model is provided. “Helpfulness” in that context is d efined
by Amazon’s notion of how many users rated a review and
how many of them found it helpful. Lu et al. [17] use a latent
topic approach to extract rated q uality aspects (correspond-
ing to concepts such as “price”or “shipping”) from comments
in ebay. In [27] the temporal development of product rat-
ings and their helpfulness and dependencies on factors such
number of reviews or effort required (writing review vs. just
assigning a rating) are studied. The helpfulness of answers
on the Yahoo! Answers site and the influ ence of variables
such as required type of answer (e.g. factual, opinion, per-
sonal advice), topic domain of the question or “priori effect”
(e.g. Did the inquirer some apriori research on the topic?) is
manually analyzed in [12]. In comparison, our paper focuses
on community ratings for comments and discussions rather
than product ratings.
Work on sent iment classification and opinion mining such
as [19, 25] deals with the problem of automatically assigning
opinion values (e.g. “positive” vs. “negative” vs. “neut ral”)
to documents or topics using various text-oriented and lin-
guistic features. Recent work in this area makes also use
of SentiWordNet [5] to improve classification performance.
However, the problem setting in th ese papers differs from
ours as we analyze community feedback for comments rather
than trying to predict the sentiment of the comments them-
selves.
There is a plethora of work on classification using proba-
bilistic and discriminative models [2] and learning regression
and ranking functions [24, 20, 1]. The popular SVM Light
software package [14] provides various kinds of parameteri-
zations and variations of SVM training (e.g., binary classi-
fication, SVM regression and ranking, transductive SVMs,
etc.). In this paper we will apply these techniques in a novel
context to automatic classification of comment acceptance.
Kim et al. [15] rank product reviews according to th eir
helpfulness using different textual features and meta data.
However, th ey report their best results for a combination of
information obtained from the star ratings (e.g. deviation
from other ratings) provided by the authors of the reviews
themselves; this information is not available for all sites,
and in particular not for comments in YouTube. Weimer
et al. [26] make use of a similar idea to automatically pre-
dict the quality of posts in the software online forum Nab-
ble.com. Liu et al [16] describe an approach for aggregat ion
of ratings on product features using helpfulness classifiers
based on a manually determined ground truth, and com-
pare their summarization with special “editor reviews” on
these sites. Another example of using commu nity feedback
to obtain training data and ground truth for classification
and regression can be found in our own work [22], for an
entirely different domain, where tags and visual features in
comb in ation with favorite assignments in Flick r are used to
classify and rank photos according to their attractiveness.
Compared to previous work, our paper is the first to apply
and evaluate automatic classification methods for comment
acceptance in YouTube. Furthermore, we are the first t o
provide an in-depth analysis of the distribution of YouTube
comment ratings, including both qualitative and quantita-
tive studies as well as dependencies on comment sent iment,
rating differences between categories, and polarizing con-
tent.
3. DATA
We created our test collection by formulating queries and
subsequent searches for “related videos”, analogously to the
typical user interaction with the YouTube system. Given
that an archive of most common queries does not exist for
YouTube, we selected our set of queries from Google’s Zeit-
geist archive from 2001 to 2007, similarly to our previous
work [23]. These are generic queries, used to search for web
pages. In this way, we obtained 756 keyword queries.
In 2009, for each video we gathered the first 500 comments
(if available) for the video, along with their authors, times-
tamps and comment ratings. YouTube computes comment
ratings by counting the number of “thumbs up” or “thumbs
down” ratings, which correspond to positive or a negative
votes by other users. In addition, for each video we col-
lected meta data such as title, tags, category, d escription,
upload date as well as statistics provided by YouTube su ch
as overall number of comments, views, and star rating for
the video. The complete collection used for evaluation had a
final size of 67, 290 videos and about 6.1 million comments.
WWW 2010 • Full Paper
April 26-30 • Raleigh • NC • USA
892

0
0.01
0.02
0.03
0.04
0.05
0.06
0.07
1 10 100 1000 10000 100000
Frequency
N. Comments
Figure 2: Distribution of Number of Comments per
Video
0
500000
1e+06
1.5e+06
2e+06
2.5e+06
3e+06
3.5e+06
<-10 -10 -9 -8 -7 -6 -5 -4 -3 -2 -1 0 1 2 3 4 5 6 7 8 9 10 >10
Figure 3: Distribution of comment ratings
Figure 2 shows the distribution of the number of com-
ments per video in the collected set. The distribution follows
the expected zipfian pattern, characterized by h aving most
of the energy contained within the first ranked elements as
well as subsequent long tail of additional low-represented el-
ements, valid for most community provided data. For our
collection, we observe a mean value of µ
comm
= 475 com-
ments per video, with ratings ranging from −1, 918 to 4, 170
for a mean value of µ
r
= 0.61.
Figure 3 shows the distribution of comment ratings. The
following two main observations can be made: On the one
hand, the distribution is asymmetric for positive and neg-
ative ratings, indicating that th e community tends to cast
more positive th an negative votes. On the other hand, com-
ments with rating 0 represent about 50% of the overall pop-
ulation, indicating that most comments lack votes or are
neutrally evaluated by the community.
Preliminary Term Analysis.
The textual content of comments in Web 2.0 infrastruc-
tures such as YouTube can p rovide clues on the community
acceptance of comments. This is partly due to the choice of
words and language used in different kinds of comments. As
Table 1: Top-50 terms according to their MI val ues
for accepted (i.e. high comment ratings) vs. not
accepted (i.e. low comment ratings) comments
Terms for Accepted Comments
love favorit perfect wish sweet
song her perform hilari jame
best hot miss most talent
amaz my omg gorgeou feel
beauti d nice brilliant avril
awesom voic bless legend wond er
she rock music ador janet
thank lol sexi fantast danc
lt xd man heart absolut
cute luv greatest time watch
Terms for Unaccepted Comments
fuck ur game fuckin shut
suck dont fat worst gui
u ugli kill y im
gai dick idiot pussi jew
shit better dumb crap comment
stupid fag retard de die
bitch white bad cunt cock
ass fake know bore name
nigger black don loser asshol
hate faggot sorri look read
an illustrative example we computed a ranked list of terms
from a set of 100,000 comments with a rating of 5 or higher
(high community acceptance) and another set of the same
size containing comments with a rating of -5 or lower ( low
commu nity acceptance). For ranking the terms, we used the
Mutual Information (MI) measure [18, 28] from information
theory which can be interpreted as a measure of how much
the joint distribution of features X
i
(terms in our case) de-
viate from a hypothetical distribution in which features and
categories (“high community acceptance” and “low commu-
nity acceptance”) are independent of each other.
Table 1 shows the top-50 stemmed terms extracted for
each category. Obviously many of the “accepted” comments
contain terms expressing sympathy or commendation (love,
fantast, greatest, perfect). “Unaccepted” comments , on the
other hand, often contain swear words (retard, idiot) and
negative adjectives (ugli, dumb); this indicates that offensive
comment s are, in general, not promoted by the community.
4. SENTIMENT ANALYSIS OF RATED
COMMENTS
Do comment language and sentiment have an influence on
comment ratings? In this section, we will make use of the
publicly available SentiWordNet thesaurus to study the con-
nection between sentiment scores obtained from SentiWord-
Net and the comment rating behavior of the community.
SentiWordNet [9] is a lexical resource built on top of Word-
Net. WordNet [10] is a thesaurus contain in g text ual descrip-
tions of terms and relationships between terms (examples are
hypernyms: “car” is a subconcept of “vehicle” or syn onyms:
“car” describes t he same concept as “automobile”). WordNet
distinguishes between different part-of-speech types (verb,
noun, adjective, etc.) A synset in WordNet comprises all
terms referring to t he same concept (e.g. {car, automobile}).
WWW 2010 • Full Paper
April 26-30 • Raleigh • NC • USA
893

0
0.1
0.2
0.3
0.4
0.5
0.6
0.7
0.8
0 0.1 0.2 0.3 0.4 0.5 0.6 0.7 0.8 0.9 1
Frequency
Positivity
Terms Corresponding to Negatively Rated Comments
Terms Corresponding to Positively Rated Comments
0
0.1
0.2
0.3
0.4
0.5
0.6
0.7
0.8
0 0.1 0.2 0.3 0.4 0.5 0.6 0.7 0.8 0.9 1
Frequency
Negativity
Terms Corresponding to Negatively Rated Comments
Terms Corresponding to Positively Rated Comments
Figure 4: SentiValue histograms for term lists ac-
cording to MI
In SentiWordNet a triple of three senti values (pos, neg, obj)
(corresponding t o positive, negative, or rather neutral sen-
timent flavor of a word respectively) are assigned to each
WordNet synset (and, thus, to each term in t he synset). The
sentivalues are in the range of [0, 1] and sum up to 1 for each
triple. For instance (p os , neg, obj) = (0.875, 0.0, 0.125) for
the term“good” or (0.25, 0.375, 0.375) for the term “ill”. Sen-
tivalues were partly created by human assessors and partly
automatically assigned using an ensemble of different classi-
fiers (see [8] for an evaluation of these methods). In our ex-
periments, we assign a sentivalue to each comment by com-
puting the averages for pos, neg and obj over all words in
the comment that have an entry in SentiWordNet.
A SentiWordNet-based Analysis of Terms.
We want to provide a more quantitative study of the inter-
relation between terms typically used in comments with high
positive or negative ratings. To this end, we selected the
top-2000 terms according to the MI measure (see previous
section) for positively and negatively rated comments, and
retrieved their sentivalue triples (pos, neg, obj) from Senti-
WordNet if available.
Figure 4 shows the histograms of sentivalues for t hese
terms. In comparison to terms corresponding to positively
rated comments, we can observe a clear tendency of the
terms corresp onding to negatively rated comments t owards
higher negative sentivalue assignments.
Sentiment Analysis of Ratings.
Now we d escribe our statistical comparison of the influ-
ence of sent iment scores in comment ratings. For our anal-
ysis, we restricted ourselves to adjectives as we observed
0
0.1
0.2
0.3
0.4
0.5
0.6
0.0 0.1 0.2 0.3 0.4 0.5 0.6 0.7 0.8 0.9 1.0
Frequency
Negativity Sentivalue
5Neg
0Dist
5Pos
0
0.05
0.1
0.15
0.2
0.25
0.0 0.1 0.2 0.3 0.4 0.5 0.6 0.7 0.8 0.9 1.0
Frequency
Objectivity Sentivalue
5Neg
0Dist
5Pos
0
0.05
0.1
0.15
0.2
0.25
0.3
0.35
0.0 0.1 0.2 0.3 0.4 0.5 0.6 0.7 0.8 0.9
Frequency
Positivity Sentivalue
5Neg
0Dist
5Pos
Figure 5: Distribution of comment negativity / ob-
jectivity / positivity
the highest accuracy in SentiWordNet for these. Our intu-
ition is that the choice of terms used to compose a comment
may provoke strong reactions of approval or denial in the
commu nity, and therefore determine t he final rating score.
For instance, comments with a high proportion of offensive
terms would tend to receive more negative ratings. We used
comment -wise sentivalues, computed as explained above, to
study the presence of sentiments in comment s according to
their rating.
To this end, we first subdivided the data set into three
disjoint p artitions:
• 5Neg: The set of comments with rating score r less
or equal to -5, r ≤ −5.
• 0Di st: The set of comments with rating score equal
to 0, r = 0.
• 5Pos: The set of comments with rating score greater
or equal to 5, r ≥ 5.
We then analyzed the dependent sentiment variables pos-
itive, objective and negative for each different p artition. De-
tailed comparison histograms for these sentiments are shown
WWW 2010 • Full Paper
April 26-30 • Raleigh • NC • USA
894

0
0.1
0.2
0.3
0.4
5Neg 0Dist 5Pos
Mean Value
Partition
Negativity
Positivity
Figure 6: Difference of Mean values for sentiment
categories
in Figure 5. These figures provide graphical evidence of the
intuition stated above. Negatively rated comments (5Neg)
tend t o contain more negative sentiment terms than pos-
itively rated comments (5Pos), reflected on a lower fre-
quency of sentivalues at negativity level 0.0 along with con-
sistently higher frequ encies at negativity levels ≥ 0.1. Simi-
larly, positively rated comments t end to contain more posi-
tive sentiment terms. We also observe that comments with
rating score equal to 0 (0Dist) have sentivalues in between,
in line with th e initial intuition.
We further analyzed whether the difference of sentivalues
across partitions was significant. We considered comment
positivity, objectivity and negativity as dependent variables.
Rating partition (5Neg, 0Dist, 5Pos) was used as the in-
dependent variable (grouping factor) of our test. Let us
denote µ
k
s
the mean value for sentiment s ∈ {N, O, P } (neg-
ativity, objectivity and positivity respectively) for partition
k ∈ {5Neg, 0Dist, 5P os}. Our initial null hypothesis states
that the distribution of sentiment values does not depend
on the partition states, i.e. the mean value of each inde-
pendent variable is equal across partitions H
0
: µ
5Neg
s
=
µ
0Dist
s
= µ
5P os
s
. The alternative hypothesis H
a
states that
the d ifference is significant for at least two partitions. We
then used three separate one-way ANOVA (Analysis of Vari-
ance) procedures [6], a statistical test of whether the means
of several groups are all equal, t o verify t he null hypothesis,
H
0
, for each variable negativity (F
N
), objectivity (F
O
) and
positivity (F
P
).
We selected a random sample of 15, 000 comments. From
this, we discarded comment s for which sentiment values were
unavailable in SentiWordNet, resulting in a final set of 5047
comment s. All tests resulted in a strong rejection of the
null hypothesis H
0
at significance level 0.01. Figure 6 shows
the d ifference of mean values for negativity and positivity,
revealing that negative sentivalues are predominant in nega-
tively rated comments, whereas positive sentivalues are pre-
dominant in positively rated comments.
The ANOVA test does not provide information about the
specific mean values µ
k
s
that refuted H
0
. Many different
post-hoc tests exist to reveal this information. We used the
Games-Howell [6] test to reveal t hese inter-partition mean
differences because of its tolerance for standard deviation
heterogeneity in data sets. For negativity, the following ho-
mogeneous groups were found: { {5Neg}, {0Dist, 5Pos}
}. Finally, for positivity the following homogeneous groups
were found: { {5Neg}, {0Dist}, {5Pos} }. These results
provide statistical evidence of the intuition that negatively
rated comments contain a significant ly larger number of
negative sentiment terms, and similarly for positively rated
comment s and positive sentiment terms.
5. PREDICTING COMMENT RATINGS
Can we predict community acceptance? We will use sup-
port vector machine classification and term-based represen-
tations of comments to automatically categorize comments
as likely to obtain a high overall rating or not. Results
of a systematic and large-scale evaluation on our YouTube
dataset show promising results, and demonstrate the viabil-
ity of our approach.
5.1 Experimental Setup for Classification
Our term- and SentiWordNet-based analysis in the previ-
ous sections indicates that a word-based approach for classi-
fication might result in good discriminative performance. In
order to classify comments into categories “accepted by the
commu nity” or “not accepted”, we use a supervised learning
paradigm which is based on training items (comments in
our case) that need t o be provided for each category. Both
training and test items, which are later given to the clas-
sifier, are represented as multi dimensional feature vectors.
These vectors can, for instance, be constructed using tf or
tf · idf weights which represent the importance of a term for
a document in a specific corpus. Comments labeled as “ac-
cepted” or “not accepted” are used to t rain a classification
model, using probabilistic (e.g., Naive Bayes) or discrimina-
tive models (e.g., SVMs).
How can we obtain sufficiently large training sets of “ac-
cepted” or “not accepted” comments? We are aware that the
concept is highly subjective and problematic. However, the
amount of community feedback in YouTube results in large
annotated comment sets which can help to average out noise
in various forms and, thus, reflects to a certain degree the
“democratic” view of a community. To this end we consid-
ered distinct thresholds for the minimum comment rating for
comment s. Formally, we obtain a set {( ~c
1
, l
1
), . . . ( ~c
n
, l
n
)} of
comment vectors ~c
i
labeled by l
i
with l
i
= 1 if the rating
lies above a threshold (“positive” examples), l
i
= −1 if the
rating is below a certain threshold (“negative” examples).
Linear support vector machines (SVMs) construct a hy-
perplane ~w ·~x+b = 0 that separates a set of positive training
examples from a set of negative examples with maximum
margin. For a new previously unseen comment ~c, the SV M
merely needs to test whether it lies on the “positive” side or
the “negative” side of the separating hyperplane. We used
the S VMlight [14] implementation of linear support vector
mach in es (SVMs) with standard parameterization in our ex-
periments, as this has been shown to perform well for various
classification tasks (see, e.g.,[7, 13]).
We performed different series of binary classification ex-
periments of YouTube comments into the classes “accepted”
and “not accepted” as introduced in the previous subsection.
For our classification experiments, we considered different
levels of restrictiveness for these classes. Specifically, we
considered distinct thresholds for the minimum and max-
imum ratings (above/below +2/-2, +5/-5 and +7/-7) for
comment s to be considered as “accepted” or “not accepted”
by the community.
We also considered d ifferent amounts of randomly cho-
sen “accepted” training comments (T = 1000, 10000, 50000,
WWW 2010 • Full Paper
April 26-30 • Raleigh • NC • USA
895

0
0.2
0.4
0.6
0.8
1
0 0.2 0.4 0.6 0.8 1
Precision
Recall
AC_POS - Rating Threshold: 5 T: 50000
BEP
0
0.2
0.4
0.6
0.8
1
0 0.2 0.4 0.6 0.8 1
Precision
Recall
AC_NEG - Rating Threshold: 5 T: 50000
BEP
0
0.2
0.4
0.6
0.8
1
0 0.2 0.4 0.6 0.8 1
Precision
Recall
THRES-0 - Rating Threshold: 5 T: 50000
BEP
Figure 7: Comment Classification: Precision-recall curves (50000 training comments per class, rating≥5)
Table 2: Comme nt Classification Results (BEPs)
AC POS
T Rating ≥ 2 Rating ≥ 5 Rating ≥ 7
1000 0.6047 0.6279 0.6522
10000 0.642 0.6714 0.6932
50000 0.6616 0.6957 0.7208
200000 0.6753 - -
AC NEG
T Rating ≥ 2 Rating ≥ 5 Rating ≥ 7
1000 0.6061 0.629 0.6531
10000 0.6431 0.6724 0.6943
50000 0.6627 0.6966 0.7215
200000 0.6763 - -
THRES-0
T Rating ≥ 2 Rating ≥ 5 Rating ≥ 7
1000 0.5516 0.5807 0.6014
10000 0.5812 0.6264 0.6424
50000 0.6003 0.6456 0.6639
200000 0.6106 0.6586 0.6786
200000) as positive examples and the same amount of ran-
domly chosen “unaccepted” comment s as negative samples
(where that number of training comments and at least 1000
test comments were available for each of the two classes).
For testing the models based on these training sets we used
the disjoint sets of remaining “accepted” comments with
same minimum rating and a randomly selected disjoint sub-
set of negative samples of the same size. We performed
a similar experiment by considering “unaccepted” comments
as positive and “accepted” ones as negative, thus, testing the
recognition of “bad” comments. We also considered the sce-
nario of discriminating comments with a high absolute rat-
ing (either positive or negative) against u nrated comments
(rating = 0). The three scenarios are lab eled AC POS,
AC NEG, and THRES-0 respectively.
5.2 Results and Conclusions
Our quality measures are the precision-recall curves as
well as the precision-recall break-even points (BEPs) for
these curves (i.e. precision/recall at the point where preci-
sion equals recall, which is also equal to the F1 measure, the
harmonic mean of precision and recall in that case). The re-
sults for the BEP values are shown in Table 2. The detailed
precision-recall curves for the example case of T=50000 train-
ing comments class and thresholds +5/-5 for “accepted”/
“unaccepted” comments are shown in Figure 7. The main
observations are:
• A ll three types of classifiers provide good performance.
For instance, the configuration with T=50,000 posi-
tive/negative training comments and thresholds +7/-7
for the scenario AC POS leads to a BEP of 0.7208.
Consistently, similar observations can be made for all
examined configurations.
• Trading recall against precision leads to applicable re-
sults. For instance, we obtain prec=0.8598 for re-
call=0.4, and prec=0.9319 for recall=0.1 for AC POS;
this is useful for finding candidates for interesting com-
ments in large comment sets.
• Classification results tend to improve, as expected,
with an increasing number of training comments. Fur-
thermore, classification performance increases with
higher thresholds for community ratings for which a
comment is considered as “accepted”.
6. COMMENT RATINGS AND
POLARIZING YOUTUBE CONTENT
In this section, we will study the relationship between
comment ratings and polarizing content, more specifically
tags/topics and videos. By “polarizing content” we mean
content likely to trigger diverse opinions and sentiment, ex-
amples being content related to the war in Irak or the pres-
idential election in contrast to rather “neutral” topics such
as chemistry or physics. Intuitively, we expect a correspon-
dence between diverging and intensive comment rating be-
havior and polarizing cont ent in Youtube.
Variance of Comment Ratings as Indicator for
Polarizing Videos.
In order to identify polarizing videos, we computed the
variance of comment ratings for each video in our dataset.
Figure 8 shows examples of videos with high versus low rat-
ing variance (in our specific ex amples videos about an I raki
girl stoned to death, Obama, and protest on Tiananmen
Square in contrast to videos about The Beatles, cartoons,
and amateur music). To show the relation between com-
ment ratings and polarizing videos, we conducted a user
evaluation of the top- and bottom-50 videos sorted by their
variance. These 100 videos were put into random order, and
evaluated by 5 users on a 3-point Likert scale (3: polarizing,
1: rather neutral, 2: in between). The assessments of the
WWW 2010 • Full Paper
April 26-30 • Raleigh • NC • USA
896

Figure 8: Videos with high (upper row) versus low
variance (lower row) of comment ratings
different users were averaged for each vid eo, and we com-
puted the inter-rater agreement using the κ-measure [21],
a statistical measure of agreement between individuals for
qualitative ratings. The mean user rating for videos on top
of the list was 2.085 in contrast to a mean of 1.25 for videos
on the bottom (inter-rater agreement κ = 0.42); this is quite
a high difference on a scale from 1 to 3, and supports our hy-
pothesis that polarizing videos tend to trigger more diverse
comment rating behavior. A t-test confirmed the statistical
significance of this result (t= 7.35, d.f. = 63, P < 0.000001).
Variance of Comment Ratings as Indicator for
Polarizing Topics.
We were also studying the connection between comment
ratings and video tags correspondin g to polarizing topics.
To this end we selected all tags from our dataset occurring
in at least 50 videos resulting in 1, 413 tags. For each tag
we t hen computed the average variance of comment ratings
over all videos labeled with this t ag. Table 3 shows the
top- and bottom-25 tags according to the average variance.
We can clearly observe a higher tendency for tags of videos
with higher variance to be associated with more polarizing
topics such as presidential, islam, irak, or hamas, whereas
tags of videos with low variance correspond to rather neut ral
topics such as butter, daylight or snowboard. There are also
less obvious cases an example being the tag xbox with high
rating variance which might be due to polarizing gaming
commu nities strongly favoring either Xbox or other consoles
such as PS3, another example being f-18 with low rating
variance, a fighter jet that might be discussed under rather
technical aspects in YouTube (rather than in th e context of
wars). We quantitatively evaluated this tendency in a user
experiment with 3 assessors similar to the one described for
videos using the same 3-point Likert scale and presenting
the tags to the assessors in random order. The mean user
rating for tags in the top-100 of the list was 1.53 in contrast
to a mean of 1.16 for tags on the bottom-100 (with inter-
rater agreement κ = 0.431), supporting our hypothesis that
tags corresponding to polarizing t opics tend to be connected
to more diverse comment rating behavior. The statistical
significance of this result was confirmed by a t-test (t=4.86,
d.f. = 132, P = 0.0000016).
Table 3: Top and Bottom-25 tags according to the
variance of comment ratings for the corresponding
videos
High comment rating variance
presidential nomination muslim shakira islam
campaign station itunes grassroots nice
xbox barack efron zac iraq
3g kiss obama deals celebrities
jew space shark hamas kiedis
Low comment rating variance
betting turns puckett tmx tropical
skybus peanut defender f-18 vlog
butter chanukah form savings iditarod
lent daylight egan snowboard havanese
menorah casserole 1040a 1040ez booklet
7. CATEGORY D EPENDENCIES OF
RATINGS
Videos in YouTube belong to a variety of categories such
as “News & Politics”, “Sports” or “Science”. Given that dif-
ferent categories attract different types of users, an inter-
esting question is wheth er this results in different kinds of
comment s, d iscussions and feedback.
7.1 Classification
In order to study the influence of categories on the classifi-
cation behavior, we conducted a similar experimental series
as described in section 5. In the following paragraphs, we
describe the results of classification of YouTube comments
into the classes “accepted” and “not accepted” as introduced
in t he previous subsection. I n each classification experiment
we restricted our training and test sets to comments from
the same class. We used smaller training sets than in sec-
tion 5 as we had less comments available per category than
for the overall dataset.
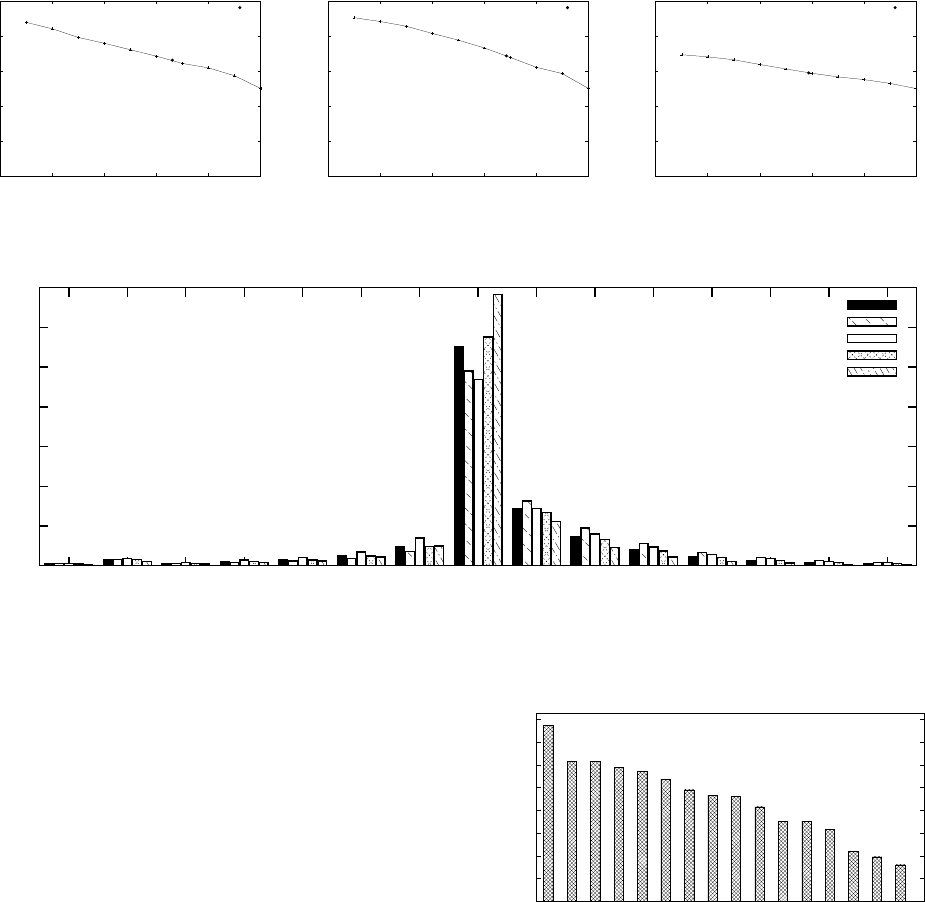
Figure 9 shows the precision-recall curves as well as the
break-even-points (BEPs) for comment classification for the
configuration T=10,000 training documents and threshold
+5/-5 for accepted/unaccepted comments. We observe that
training and classifying on different categories leads to clear
differences in classification results. While classifiers applied
within the categories“Music”and“Entertainment”show com-
parable performance, the performance drops for for “N ews
& Politics”. This might be an indicator for more complex
patterns and user relationships for that domain.
7.2 Analysis of comment ratings for different
categories
In this section we consider the analysis of comment rating
distribution across different categories. Our intuition is that
some topics are more prone to generate intense discussions
than others. Differences of opinion will normally lead to
an increasing number of comments and comment ratings,
affecting the distribut ion.
Figure 10 shows t he distribution of comment ratings for a
set of selected categories from our subset. We observe sev-
eral variations for the different categories. For instance, sci-
ence videos present a majority of 0-scored comments, maybe
due to the impartial nature of this category. Politics v ideos
have significantly more negatively rated comments than any
other category. Music videos, on the other hand, have a
WWW 2010 • Full Paper
April 26-30 • Raleigh • NC • USA
897
0
0.2
0.4
0.6
0.8
1
0 0.2 0.4 0.6 0.8 1
Precision
Recall
Category Entertainment - Rating Threshold: 5, T: 10000
BEP
0
0.2
0.4
0.6
0.8
1
0 0.2 0.4 0.6 0.8 1
Precision
Recall
Category Music - Rating Threshold: 5, T: 10000
BEP
0
0.2
0.4
0.6
0.8
1
0 0.2 0.4 0.6 0.8 1
Precision
Recall
Category Politics - Rating Threshold: 5, T: 10000
BEP
Figure 9: Classification Precision-Recall Curves for Multiple Categories
0
0.1
0.2
0.3
0.4
0.5
0.6
0.7
-7 -6 -5 -4 -3 -2 -1 0 1 2 3 4 5 6 7
Frequency
Comment Rating
Enterntainment
Music
Politics
People
Science
Figure 10: Distribution of comment ratings for different categories
clear majority of positively rated comments. Mean rating
score values for all categories in our d atabase are shown in
Figure 11.
We further analyzed whether the rating score d ifference
across categories was significant. We considered comment
ratings as the dependent variable, and categories as the
grouping factor. Let us denote µ
i
r
the mean rating score
value for category i. We wanted to refute hypothesis H
0
:
µ
i
r
= µ
j
r
, ∀ i, j (i.e. comment ratings mean value is identical
for all categories). Our alternative hypothesis H
a
states that
at least two categories, i and j, feature mean rating scores
that are statistically different. We used one-way ANOVA
to test the validity of the null hypothesis. For this experi-
ment we considered the complete data set, excluding com-
ments with 0 ratings and no assigned category, for a total
of 2, 539, 142 comments. The test resulted in a strong rejec-
tion of the hypothesis H
0
at significance level 0.01, providing
evidence that mean rating values across categories are sta-
tistically different.
A subsequent post-hoc Games-Howell test was conducted
to stud y pair-wise differences between categories. Table 4
shows the homogeneous groups found. The table identi-
fies category “Music” as having significantly h igher comment
ratings than any other, and categories “Autos&Vehicles”,
“Gaming” and “Science” having significantly lower comment
ratings. While some categories are likely to be affected by
the lack of comment ratings (“Science”), the significantly
lower comment ratings in some categories like “Gaming”
0
0.2
0.4
0.6
0.8
1
1.2
1.4
1.6
Music
Entertainment
People - Blogs
Film - Animation
Comedy
Education
News - Politics
Travel - Events
Nonprofits - Activism
Pets - Animals
Howto - Style
Shows
Sports
Gaming
Autos - Vehicles
Science
Mean Rating
Category
Figure 11: Mean Rating Score per Comment for
different Categories
might indicate that malign users (trolls, spammers, . . . ) are
more dominant in these categories th an in others.
7.3 Sentivalues in Categories
In Section 4 we provided statistical evidence of the de-
pendency of comment ratings on sentivalues. In this section
we extend the analysis to also consider categories, to check
whether we can find a dependen cy of sentivalues for differ-
WWW 2010 • Full Paper
April 26-30 • Raleigh • NC • USA
898

Table 4: Homogeneous Groups by Mean Rating
Homogeneous Category Groups
Highest Music
Mean
Medium Pets&Animals, Comedy, Education
Mean Entertainment, News&Politics
Nonprofits&Activism, Sports
People&Blogs, Shows
Travel&Event s, Howto&Style
Lowest Autos&Vehicles, Gaming, Science
Mean
ent categories, and provide additional ground to the claims
presented in Section 7.2.
We proceeded similarly to Section 7.2. In this case, we
considered sentivalue negativity, objectivity and positivity
as dependent variables, and categories as the grouping fac-
tor. We denote µ
N,i
r
the mean negativity value for category
i. Analogously, µ
O,i
r
and µ
P,i
r
denote mean objectivity and
positivity values for category i. We wanted to refute hypoth-
esis H
0
: µ
K,i
r
= µ
K,j
r
, ∀ i, j, K ∈ {N, O, P } (i.e. comment
ratings mean value is identical for all categories). Our al-
ternative hypothesis H
a
states that at least two categories,
i and j, feature mean values that are statistically different.
We used three one-way ANOVA procedures to test the valid-
ity of the null hy pothesis. For this experiment we considered
the complete data set, excluding comments for which senti-
values were not available, for a total of 2, 665, 483 comments.
The test resulted in a strong rejection of the hypothesis H
0
at significance level 0.01 for the three cases, providing ev-
idence that mean sentivalues across categories are statisti-
cally different. Figure 12 shows mean values for sentiments
negativity, objectivity and positivity for different categories.
Results are in agreement with findings of Section 7.2 (Ta-
ble 4 and Figure 11). For instance, music exhibits the lowest
negativity sentivalue and the highest positivity sentivalue.
Our interpretation of these results is that different cate-
gories tend to attract different kinds of users and generate
more or less discussion as a function of the controversy of
their topics. This clearly goes along with significantly differ-
ent ratings and sentivalues of comments associated to videos.
As a result, user generated comments tend to differ widely
across different categories, and therefore the qu ality of clas-
sification models gets affected (illustrated in section 7.1).
8. CONCLUSION AND FUTURE WORK
We conducted an in-depth analysis of YouTube comments
to shed some light on different aspects of comment ratings
for the YouTube v id eo sharing platform. How does commu-
nity feedback on comments depends on language and sen-
timent exp ressed? Can we learn models for comments and
predict comment ratings? Does comment rating behavior
depend on topics and categories? Can comment ratings be
an indicator for polarizing content? These are some of th e
questions we examined in this paper by analyzing a sam-
ple of more than 6 million YouTube comments and ratings.
Large-scale studies using the SentiWordNet thesaurus and
YouTube meta data revealed strong dependencies between
different kinds of sentiments expressed in comments, com-
ment ratings provided by the commun ity and topic orien-
tation of the discussed video content. In our classification
0
0.1
0.2
0.3
0.4
0.5
0.6
0.7
0.8
Shows
Nonprofits - Activism
Comedy
People - Blogs
News - Politics
Howto - Style
Education
Pets - Animals
Sports
Entertainment
Science - Technology
Gaming
Autos - Vehicles
Shows
Film - Animation
Music
Mean Rating
Category
Negativity
Objectivity
Positivity
Figure 12: D istribution of comment sentivalues
experiments, we demonstrated that community feedback in
social sharing systems in combination with term features
in comments can be used for automatically determining the
commu nity acceptance of comments. User experiments show
that rating behavior can be often conn ected to polarizing
topics and content.
Regarding future work, we plan to study temporal aspects,
additional stylistic and linguistic features, relationships be-
tween users, and techniques for aggregating information ob-
tained from comments and ratings. We think that tempo-
ral aspects such as order and timestamps of comments and
upload dates of commented videos can have a strong influ-
ence on commenting behavior and comment ratings, and,
in combination with other criteria, could help to increase
the performance of rating predictors. More advanced lin-
guistic and stylistic features of comment texts might also be
useful to build better classification and clustering models.
Finally, comments and ratings can lead to further insights
on different types of users (helpful users, spammers, t rolls,
etc.) and on social relationships between users (friendship,
rivalry, etc). This could, for instance, be applied for identify-
ing groups of u sers with similar interest and recommending
contacts or groups to users in the system.
We think that the proposed techniques have direct ap-
plications to comment search. When searching for addi-
tional information in other users’ comments, automatically
predicted comment ratings could be u sed as an additional
ranking criterion for search results. In this connection, inte-
gration and user evaluation within a wider system context
and encompassing additional complementary retrieval and
mining methods is of high practical importance.
9. ACKNOWLEDGEMEN TS
This work was supported by EU FP7 integration projects
LivingKnowledge (Contract No. 231126) and GLOCAL (Con-
tract No. 248984) and the Marie Curie IOF project“Mieson”.
10. REFERENCES
[1] C. Burges, T. Shaked, E. Renshaw, A. Lazier,
M. Deeds, N. Hamilton, and G. Hullender. Learning to
rank using gradient descent. In ICML ’05: Proceedings
WWW 2010 • Full Paper
April 26-30 • Raleigh • NC • USA
899
of the 22nd international conference on Machine
learning, pages 89–96, New York, NY, USA, 2005.
ACM.
[2] S. Chakrabarti. Mining the Web: Discovering
Knowledge from Hypertext Data. Morgan-Kauffman,
2002.
[3] X. Cheng, C. Dale, and J. Liu. U nderstanding the
characteristics of internet short video sharing:
Youtube as a case study. In Technical Report
arXiv:0707.3670v1 cs.NI, New York, NY, USA, 2007.
Cornell University, arXiv e-prints.
[4] C. Danescu-Niculescu-Mizil, G. Kossinets,
J. Kleinberg, and L. Lee. How opinions are received by
online communities: a case study on amazon.com
helpfulness votes. In WWW ’09: Proceedings of the
18th international conference on World wide web,
pages 141–150, New York, NY, USA, 2009. ACM.
[5] K. Denecke. Using sentiwordnet for multilingual
sentiment analysis. In Data Engineering Workshop,
2008. ICDEW 2008, p ages 507– 512, 2009.
[6] J. L. Devore. Probability and Statistics for Engineering
and the Sciences. Thomson Brooks/Cole, 2004.
[7] S. Dumais, J. Platt, D. Heckerman, and M. Sahami.
Inductive learning algorithms and representations for
text categorization. In CIKM ’98: Proceedings of the
seventh international conf erence on Information and
knowledge management, pages 148–155, Bethesda,
Maryland, United States, 1998. ACM Press.
[8] A. Esuli. Automatic Generation of Lexical Resources
for Opinion Mining: Models, Algorithms and
Applications. PhD in Information Engineering, PhD
School “Leonardo da Vinci”, University of Pisa, 2008.
[9] A. Esuli and F. Sebastiani. Sentiwordnet: A publicly
available lexical resource for opinion mining. In In
Proceedings of the 5th Conference on Language
Resources and Evaluation (LREC
ˆ
A
ˇ
S06), pages
417–422, 2006.
[10] C. Fellbaum, editor. WordNet: An Electronic Lexical
Database. MIT Press, Cambridge, MA, 1998.
[11] P. Gill, M. Arlitt, Z. Li, and A. Mahanti. Youtube
traffic characterization: a view from the edge. In IMC
’07: Proceedings of the 7th ACM SIGCOMM
conference on Internet measurement, pages 15–28,
New York, NY, USA, 2007. ACM.
[12] F. M. Harper, D. Raban, S. Rafaeli, and J. A.
Konstan. Predictors of answer quality in online q&a
sites. In CHI ’08: Proceeding of the twenty-si xth
annual SIGCHI conference on Human factors in
computing systems, pages 865–874, New York, NY,
USA, 2008. ACM.
[13] T. Joachims. Text categorization with Support Vector
Machines: Learning with many relevant features.
ECML, 1998.
[14] T. Joachims. Making large-scale support vector
mach in e learning practical. Advances in kernel
methods: support vector learning, pages 169–184, 1999.
[15] S.- M. Kim, P. Pantel, T. Chklovski, and
M. Pennacchiotti. Automatically assessing review
helpfulness. In Proceedings of the Conf erence on
Empirical Methods in Natural Language Processing
(EMNLP), p ages 423–430, Sydney, Australia, July
2006. Association for Computational Linguistics.
[16] J. Liu, Y. Cao, C.-Y. Lin, Y . Huang, and M. Zhou.
Low-quality product review detection in opinion
summarization. In Proceedings of the Joint Conference
on Empirical Methods in Natural Language Processing
and Computational Natural Language Learning
(EMNLP-CoNLL), pages 334–342, 2007. Poster paper.
[17] Y . Lu, C. Zhai, and N. Sundaresan. Rated aspect
summarization of short comments. In WWW ’09:
Proceedings of the 18th international conference on
World wide web, pages 131–140, New York, NY, USA,
2009. ACM.
[18] C. Manning and H. Schuetze. Foundations of
Statistical Natural Language Processing. MIT Press,
1999.
[19] B. Pang and L. Lee. Thumbs up? sentiment
classification using machine learning t echniques. In
Conference on Empirical Methods in Natural Language
Processing (EMNLP), Philadelphia, PA, USA, 2002.
[20] M. Richardson, A. Prakash, and E. Brill. Beyond
pagerank: machine learning for static ranking. In
WWW ’06: Proceedings of the 15th international
conference on World Wide Web, pages 707–715, New
York, NY, USA, 2006. ACM.
[21] A . Rosenberg and E. Binkowski. Augmenting the
kappa statistic to determine interannotator reliability
for multiply labeled data points. In HLT-NAACL ’04:
Proceedings of HLT-NAACL 2004: Short Papers on
XX, pages 77–80, Morristown, NJ, USA, 2004.
Association for Computational Linguistics.
[22] J. San Pedro and S. Siersdorfer. Ranking and
classifying attractiveness of photos in folksonomies. In
WWW ’09: Proceedings of the 18th international
conference on World wide web, pages 771–780, New
York, NY, USA, 2009. ACM.
[23] S. Siersdorfer, J. San Ped ro, and M. Sanderson.
Automatic v id eo tagging using content red undancy. In
SIGIR ’09: Proceedings of the 32nd international
ACM SIGIR conf erence on Research and development
in information retrieval, pages 395–402, New York,
NY, USA, 2009. ACM.
[24] A . J. Smola and B. Sch
¨
olkopf. A tutorial on support
vector regression. Statistics and Computing,
14(3):199–222, 2004.
[25] M. Thomas, B. Pang, and L. Lee. Get out the vote:
Determining support or opp osition from Congressional
floor-debate transcripts. In EMNLP ’06: Proceedings
of the ACL-02 conference on Empirical methods in
natural language processing, pages 327–335, 2006.
[26] M. Weimer, I. Gurevych, and M. Muehlhaeuser.
Automatically assessing the post quality in online
discussions on software. In Companion Volume of the
45rd Annual Meeting of the Association f or
Computational Linguistics (ACL), 2007.
[27] F. Wu and B. A. Huberman. How public opinion
forms. In Internet and Network Economics, 4th
International Workshop, WINE 2008, Shanghai,
China, pages 334–341, 2008.
[28] Y . Yang and J. O. Pedersen. A comparative stu dy on
feature selection in text categorization. In ICML ’97:
Proceedings of the Fourteenth International Conference
on Machine Learning, pages 412–420, San Francisco,
CA, USA, 1997. Morgan Kaufmann Publishers Inc.
WWW 2010 • Full Paper
April 26-30 • Raleigh • NC • USA
900
